 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Contextual Modeling for ASR Correction and Language Understanding
Jan 28, 2020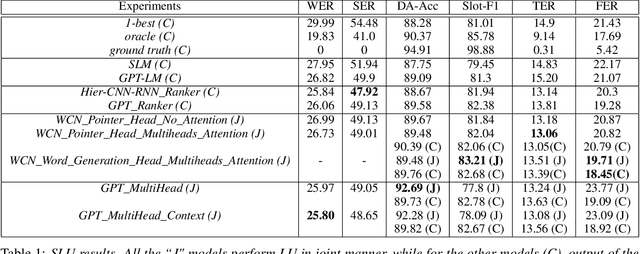
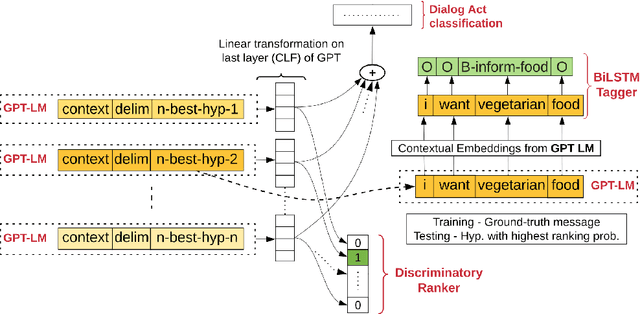
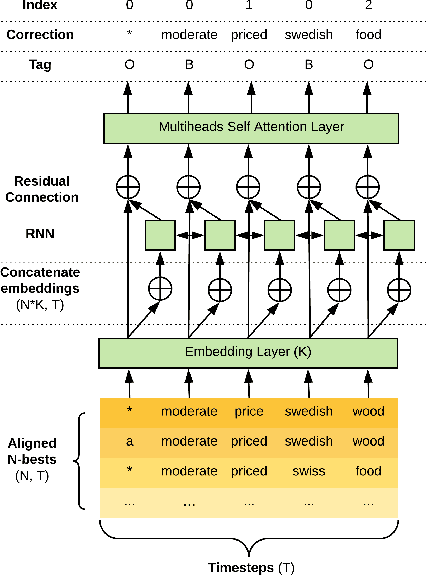
The quality of automatic speech recognition (ASR) is critical to Dialogue Systems as ASR errors propagate to and directly impact downstream tasks such as language understanding (LU). In this paper, we propose multi-task neural approaches to perform contextual language correction on ASR outputs jointly with LU to improve the performance of both tasks simultaneously. To measure the effectiveness of this approach we used a public benchmark, the 2nd Dialogue State Tracking (DSTC2) corpus. As a baseline approach, we trained task-specific Statistical Language Models (SLM) and fine-tuned state-of-the-art Generalized Pre-training (GPT) Language Model to re-rank the n-best ASR hypotheses, followed by a model to identify the dialog act and slots. i) We further trained ranker models using GPT and Hierarchical CNN-RNN models with discriminatory losses to detect the best output given n-best hypotheses. We extended these ranker models to first select the best ASR output and then identify the dialogue act and slots in an end to end fashion. ii) We also proposed a novel joint ASR error correction and LU model, a word confusion pointer network (WCN-Ptr) with multi-head self-attention on top, which consumes the word confusions populated from the n-best. We show that the error rates of off the shelf ASR and following LU systems can be reduced significantly by 14% relative with joint models trained using small amounts of in-domain data.
Ludwig: a type-based declarative deep learning toolbox
Sep 17, 2019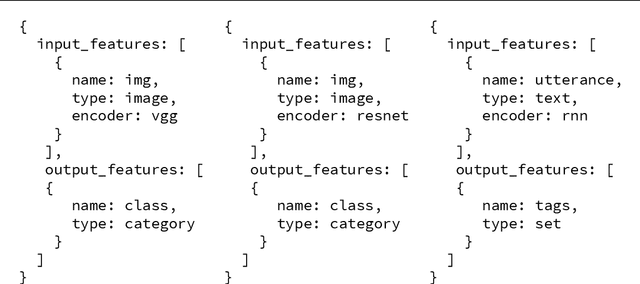
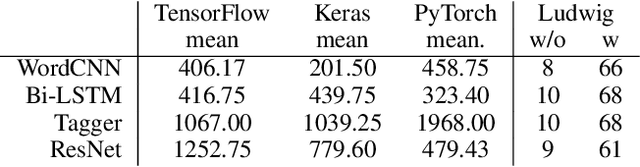

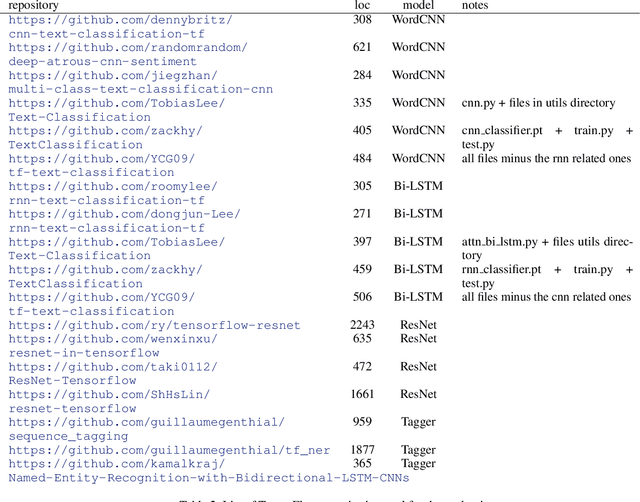
In this work we present Ludwig, a flexible, extensible and easy to use toolbox which allows users to train deep learning models and use them for obtaining predictions without writing code. Ludwig implements a novel approach to deep learning model building based on two main abstractions: data types and declarative configuration files. The data type abstraction allows for easier code and sub-model reuse, and the standardized interfaces imposed by this abstraction allow for encapsulation and make the code easy to extend. Declarative model definition configuration files enable inexperienced users to obtain effective models and increase the productivity of expert users. Alongside these two innovations, Ludwig introduces a general modularized deep learning architecture called Encoder-Combiner-Decoder that can be instantiated to perform a vast amount of machine learning tasks. These innovations make it possible for engineers, scientists from other fields and, in general, a much broader audience to adopt deep learning models for their tasks, concretely helping in its democratization.