 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePutting Question-Answering Systems into Practice: Transfer Learning for Efficient Domain Customization
Paper and Code
Apr 19, 2018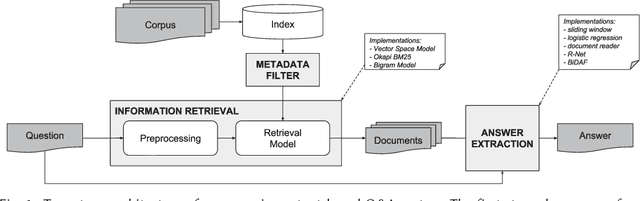

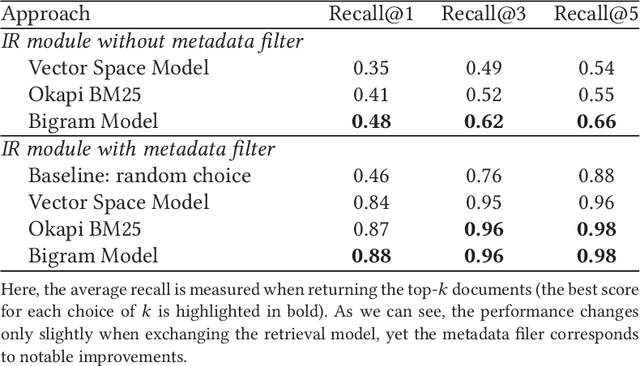
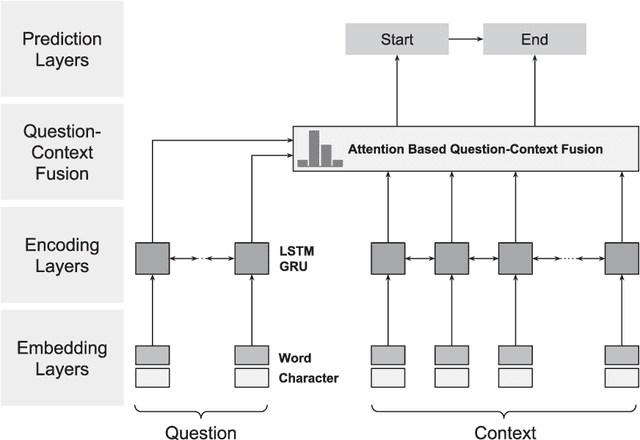
Traditional information retrieval (such as that offered by web search engines) impedes users with information overload from extensive result pages and the need to manually locate the desired information therein. Conversely, question-answering systems change how humans interact with information systems: users can now ask specific questions and obtain a tailored answer - both conveniently in natural language. Despite obvious benefits, their use is often limited to an academic context, largely because of expensive domain customizations, which means that the performance in domain-specific applications often fails to meet expectations. This paper presents cost-efficient remedies: a selection mechanism increases the precision of document retrieval and a fused approach to transfer learning is proposed in order to improve the performance of answer extraction. Here knowledge is inductively transferred from a related, yet different, tasks to the domain-specific application, while accounting for potential differences in the sample sizes across both tasks. The resulting performance is demonstrated with an actual use case from a finance company, where fewer than 400 question-answer pairs had to be annotated in order to yield significant performance gains. As a direct implication to management, this presents a promising path to better leveraging of knowledge stored in information systems.