 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Machine Learning for Cost-Effective Allocation of Development Aid
Jan 31, 2024



The Sustainable Development Goals (SDGs) of the United Nations provide a blueprint of a better future by 'leaving no one behind', and, to achieve the SDGs by 2030, poor countries require immense volumes of development aid. In this paper, we develop a causal machine learning framework for predicting heterogeneous treatment effects of aid disbursements to inform effective aid allocation. Specifically, our framework comprises three components: (i) a balancing autoencoder that uses representation learning to embed high-dimensional country characteristics while addressing treatment selection bias; (ii) a counterfactual generator to compute counterfactual outcomes for varying aid volumes to address small sample-size settings; and (iii) an inference model that is used to predict heterogeneous treatment-response curves. We demonstrate the effectiveness of our framework using data with official development aid earmarked to end HIV/AIDS in 105 countries, amounting to more than USD 5.2 billion. For this, we first show that our framework successfully computes heterogeneous treatment-response curves using semi-synthetic data. Then, we demonstrate our framework using real-world HIV data. Our framework points to large opportunities for a more effective aid allocation, suggesting that the total number of new HIV infections could be reduced by up to 3.3% (~50,000 cases) compared to the current allocation practice.
Addressing distributional shifts in operations management: The case of order fulfillment in customized production
Apr 24, 2023
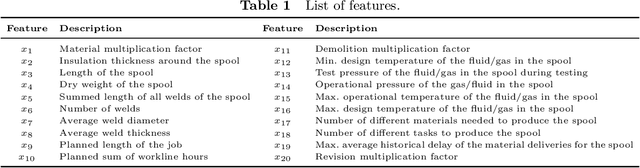
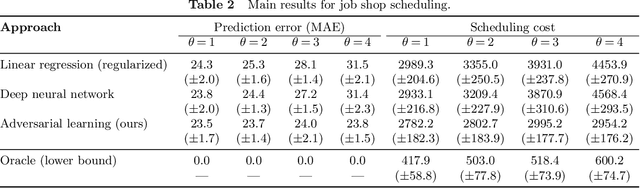
To meet order fulfillment targets, manufacturers seek to optimize production schedules. Machine learning can support this objective by predicting throughput times on production lines given order specifications. However, this is challenging when manufacturers produce customized products because customization often leads to changes in the probability distribution of operational data -- so-called distributional shifts. Distributional shifts can harm the performance of predictive models when deployed to future customer orders with new specifications. The literature provides limited advice on how such distributional shifts can be addressed in operations management. Here, we propose a data-driven approach based on adversarial learning and job shop scheduling, which allows us to account for distributional shifts in manufacturing settings with high degrees of product customization. We empirically validate our proposed approach using real-world data from a job shop production that supplies large metal components to an oil platform construction yard. Across an extensive series of numerical experiments, we find that our adversarial learning approach outperforms common baselines. Overall, this paper shows how production managers can improve their decision-making under distributional shifts.
Estimating Conditional Average Treatment Effects with Missing Treatment Information
Mar 02, 2022



Estimating conditional average treatment effects (CATE) is challenging, especially when treatment information is missing. Although this is a widespread problem in practice, CATE estimation with missing treatments has received little attention. In this paper, we analyze CATE estimation in the setting with missing treatments where, thus, unique challenges arise in the form of covariate shifts. We identify two covariate shifts in our setting: (i) a covariate shift between the treated and control population; and (ii) a covariate shift between the observed and missing treatment population. We first theoretically show the effect of these covariate shifts by deriving a generalization bound for estimating CATE in our setting with missing treatments. Then, motivated by our bound, we develop the missing treatment representation network (MTRNet), a novel CATE estimation algorithm that learns a balanced representation of covariates using domain adaptation. By using balanced representations, MTRNet provides more reliable CATE estimates in the covariate domains where the data are not fully observed. In various experiments with semi-synthetic and real-world data, we show that our algorithm improves over the state-of-the-art by a substantial margin.
Deconfounding Temporal Autoencoder: Estimating Treatment Effects over Time Using Noisy Proxies
Dec 06, 2021

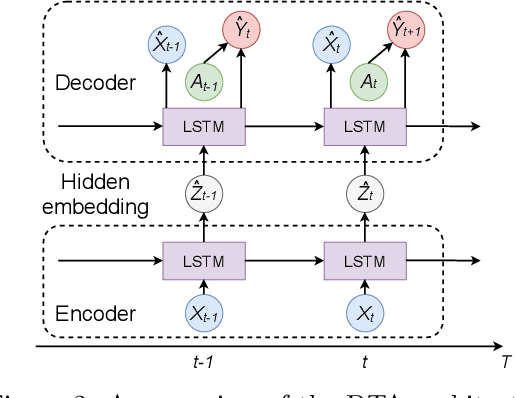
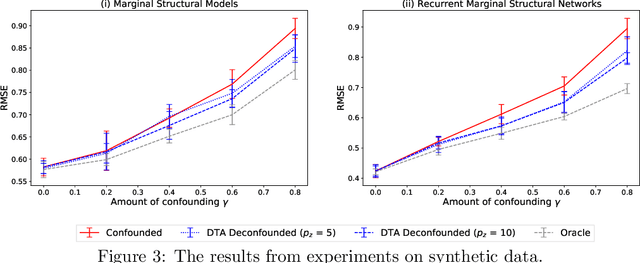
Estimating individualized treatment effects (ITEs) from observational data is crucial for decision-making. In order to obtain unbiased ITE estimates, a common assumption is that all confounders are observed. However, in practice, it is unlikely that we observe these confounders directly. Instead, we often observe noisy measurements of true confounders, which can serve as valid proxies. In this paper, we address the problem of estimating ITE in the longitudinal setting where we observe noisy proxies instead of true confounders. To this end, we develop the Deconfounding Temporal Autoencoder, a novel method that leverages observed noisy proxies to learn a hidden embedding that reflects the true hidden confounders. In particular, the DTA combines a long short-term memory autoencoder with a causal regularization penalty that renders the potential outcomes and treatment assignment conditionally independent given the learned hidden embedding. Once the hidden embedding is learned via DTA, state-of-the-art outcome models can be used to control for it and obtain unbiased estimates of ITE. Using synthetic and real-world medical data, we demonstrate the effectiveness of our DTA by improving over state-of-the-art benchmarks by a substantial margin.