 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Machine Learning for Cost-Effective Allocation of Development Aid
Jan 31, 2024



The Sustainable Development Goals (SDGs) of the United Nations provide a blueprint of a better future by 'leaving no one behind', and, to achieve the SDGs by 2030, poor countries require immense volumes of development aid. In this paper, we develop a causal machine learning framework for predicting heterogeneous treatment effects of aid disbursements to inform effective aid allocation. Specifically, our framework comprises three components: (i) a balancing autoencoder that uses representation learning to embed high-dimensional country characteristics while addressing treatment selection bias; (ii) a counterfactual generator to compute counterfactual outcomes for varying aid volumes to address small sample-size settings; and (iii) an inference model that is used to predict heterogeneous treatment-response curves. We demonstrate the effectiveness of our framework using data with official development aid earmarked to end HIV/AIDS in 105 countries, amounting to more than USD 5.2 billion. For this, we first show that our framework successfully computes heterogeneous treatment-response curves using semi-synthetic data. Then, we demonstrate our framework using real-world HIV data. Our framework points to large opportunities for a more effective aid allocation, suggesting that the total number of new HIV infections could be reduced by up to 3.3% (~50,000 cases) compared to the current allocation practice.
Detecting User Exits from Online Behavior: A Duration-Dependent Latent State Model
Aug 08, 2022In order to steer e-commerce users towards making a purchase, marketers rely upon predictions of when users exit without purchasing. Previously, such predictions were based upon hidden Markov models (HMMs) due to their ability of modeling latent shopping phases with different user intents. In this work, we develop a duration-dependent hidden Markov model. In contrast to traditional HMMs, it explicitly models the duration of latent states and thereby allows states to become "sticky". The proposed model is superior to prior HMMs in detecting user exits: out of 100 user exits without purchase, it correctly identifies an additional 18. This helps marketers in better managing the online behavior of e-commerce customers. The reason for the superior performance of our model is the duration dependence, which allows our model to recover latent states that are characterized by a distorted sense of time. We finally provide a theoretical explanation for this, which builds upon the concept of "flow".
Interpretable Off-Policy Learning via Hyperbox Search
Mar 04, 2022
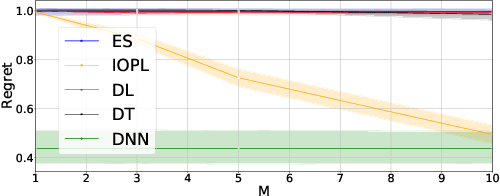


Personalized treatment decisions have become an integral part of modern medicine. Thereby, the aim is to make treatment decisions based on individual patient characteristics. Numerous methods have been developed for learning such policies from observational data that achieve the best outcome across a certain policy class. Yet these methods are rarely interpretable. However, interpretability is often a prerequisite for policy learning in clinical practice. In this paper, we propose an algorithm for interpretable off-policy learning via hyperbox search. In particular, our policies can be represented in disjunctive normal form (i.e., OR-of-ANDs) and are thus intelligible. We prove a universal approximation theorem that shows that our policy class is flexible enough to approximate any measurable function arbitrarily well. For optimization, we develop a tailored column generation procedure within a branch-and-bound framework. Using a simulation study, we demonstrate that our algorithm outperforms state-of-the-art methods from interpretable off-policy learning in terms of regret. Using real-word clinical data, we perform a user study with actual clinical experts, who rate our policies as highly interpretable.
Estimating Conditional Average Treatment Effects with Missing Treatment Information
Mar 02, 2022



Estimating conditional average treatment effects (CATE) is challenging, especially when treatment information is missing. Although this is a widespread problem in practice, CATE estimation with missing treatments has received little attention. In this paper, we analyze CATE estimation in the setting with missing treatments where, thus, unique challenges arise in the form of covariate shifts. We identify two covariate shifts in our setting: (i) a covariate shift between the treated and control population; and (ii) a covariate shift between the observed and missing treatment population. We first theoretically show the effect of these covariate shifts by deriving a generalization bound for estimating CATE in our setting with missing treatments. Then, motivated by our bound, we develop the missing treatment representation network (MTRNet), a novel CATE estimation algorithm that learns a balanced representation of covariates using domain adaptation. By using balanced representations, MTRNet provides more reliable CATE estimates in the covariate domains where the data are not fully observed. In various experiments with semi-synthetic and real-world data, we show that our algorithm improves over the state-of-the-art by a substantial margin.
Estimating average causal effects from patient trajectories
Mar 02, 2022


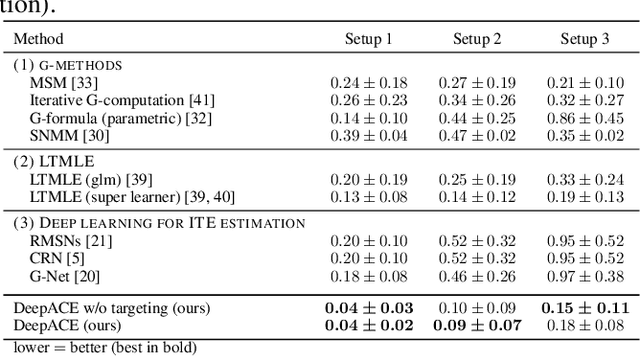
In medical practice, treatments are selected based on the expected causal effects on patient outcomes. Here, the gold standard for estimating causal effects are randomized controlled trials; however, such trials are costly and sometimes even unethical. Instead, medical practice is increasingly interested in estimating causal effects among patient subgroups from electronic health records, that is, observational data. In this paper, we aim at estimating the average causal effect (ACE) from observational data (patient trajectories) that are collected over time. For this, we propose DeepACE: an end-to-end deep learning model. DeepACE leverages the iterative G-computation formula to adjust for the bias induced by time-varying confounders. Moreover, we develop a novel sequential targeting procedure which ensures that DeepACE has favorable theoretical properties, i.e., is doubly robust and asymptotically efficient. To the best of our knowledge, this is the first work that proposes an end-to-end deep learning model for estimating time-varying ACEs. We compare DeepACE in an extensive number of experiments, confirming that it achieves state-of-the-art performance. We further provide a case study for patients suffering from low back pain to demonstrate that DeepACE generates important and meaningful findings for clinical practice. Our work enables medical practitioners to develop effective treatment recommendations tailored to patient subgroups.
Combining Observational and Randomized Data for Estimating Heterogeneous Treatment Effects
Feb 25, 2022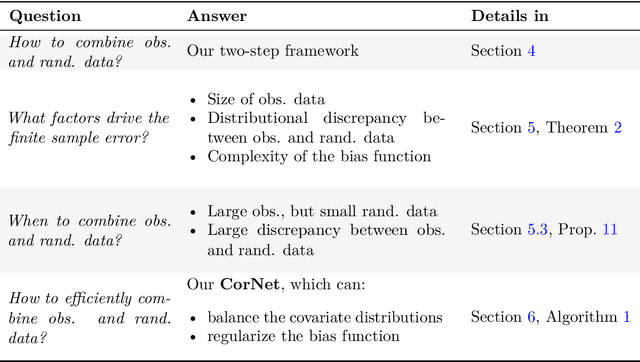
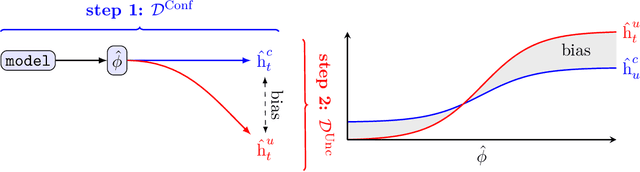
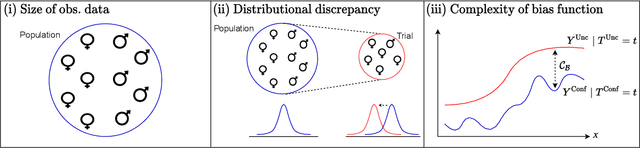

Estimating heterogeneous treatment effects is an important problem across many domains. In order to accurately estimate such treatment effects, one typically relies on data from observational studies or randomized experiments. Currently, most existing works rely exclusively on observational data, which is often confounded and, hence, yields biased estimates. While observational data is confounded, randomized data is unconfounded, but its sample size is usually too small to learn heterogeneous treatment effects. In this paper, we propose to estimate heterogeneous treatment effects by combining large amounts of observational data and small amounts of randomized data via representation learning. In particular, we introduce a two-step framework: first, we use observational data to learn a shared structure (in form of a representation); and then, we use randomized data to learn the data-specific structures. We analyze the finite sample properties of our framework and compare them to several natural baselines. As such, we derive conditions for when combining observational and randomized data is beneficial, and for when it is not. Based on this, we introduce a sample-efficient algorithm, called CorNet. We use extensive simulation studies to verify the theoretical properties of CorNet and multiple real-world datasets to demonstrate our method's superiority compared to existing methods.
Deconfounding Temporal Autoencoder: Estimating Treatment Effects over Time Using Noisy Proxies
Dec 06, 2021

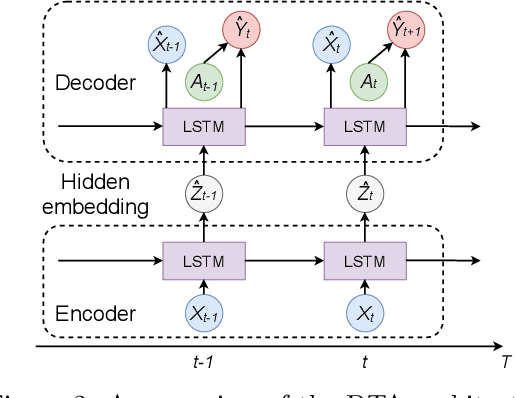
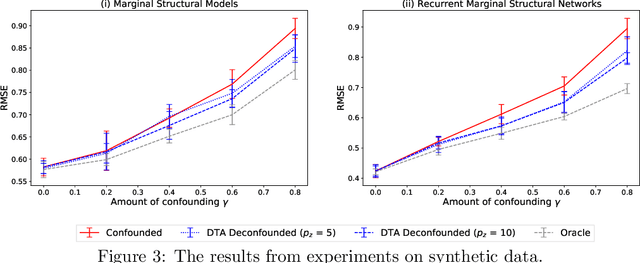
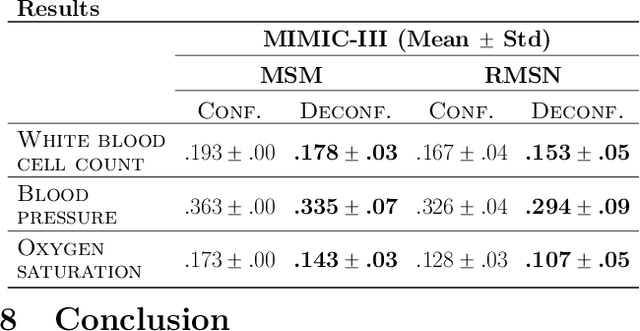
Estimating individualized treatment effects (ITEs) from observational data is crucial for decision-making. In order to obtain unbiased ITE estimates, a common assumption is that all confounders are observed. However, in practice, it is unlikely that we observe these confounders directly. Instead, we often observe noisy measurements of true confounders, which can serve as valid proxies. In this paper, we address the problem of estimating ITE in the longitudinal setting where we observe noisy proxies instead of true confounders. To this end, we develop the Deconfounding Temporal Autoencoder, a novel method that leverages observed noisy proxies to learn a hidden embedding that reflects the true hidden confounders. In particular, the DTA combines a long short-term memory autoencoder with a causal regularization penalty that renders the potential outcomes and treatment assignment conditionally independent given the learned hidden embedding. Once the hidden embedding is learned via DTA, state-of-the-art outcome models can be used to control for it and obtain unbiased estimates of ITE. Using synthetic and real-world medical data, we demonstrate the effectiveness of our DTA by improving over state-of-the-art benchmarks by a substantial margin.
Generalizing Off-Policy Learning under Sample Selection Bias
Dec 02, 2021
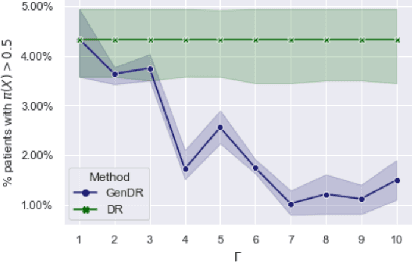
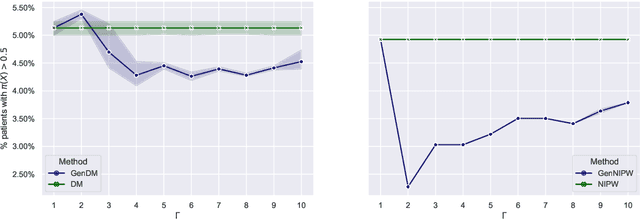
Learning personalized decision policies that generalize to the target population is of great relevance. Since training data is often not representative of the target population, standard policy learning methods may yield policies that do not generalize target population. To address this challenge, we propose a novel framework for learning policies that generalize to the target population. For this, we characterize the difference between the training data and the target population as a sample selection bias using a selection variable. Over an uncertainty set around this selection variable, we optimize the minimax value of a policy to achieve the best worst-case policy value on the target population. In order to solve the minimax problem, we derive an efficient algorithm based on a convex-concave procedure and prove convergence for parametrized spaces of policies such as logistic policies. We prove that, if the uncertainty set is well-specified, our policies generalize to the target population as they can not do worse than on the training data. Using simulated data and a clinical trial, we demonstrate that, compared to standard policy learning methods, our framework improves the generalizability of policies substantially.
Sequential Deconfounding for Causal Inference with Unobserved Confounders
Apr 16, 2021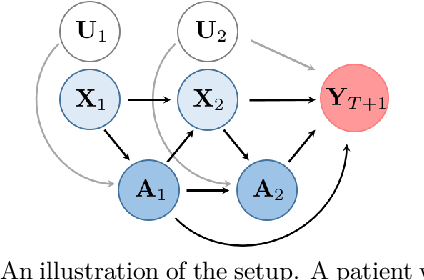
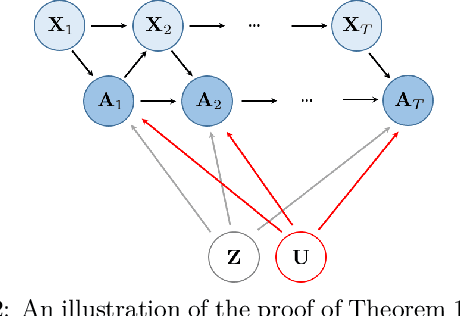

Using observational data to estimate the effect of a treatment is a powerful tool for decision-making when randomized experiments are infeasible or costly. However, observational data often yields biased estimates of treatment effects, since treatment assignment can be confounded by unobserved variables. A remedy is offered by deconfounding methods that adjust for such unobserved confounders. In this paper, we develop the Sequential Deconfounder, a method that enables estimating individualized treatment effects over time in presence of unobserved confounders. This is the first deconfounding method that can be used in a general sequential setting (i.e., with one or more treatments assigned at each timestep). The Sequential Deconfounder uses a novel Gaussian process latent variable model to infer substitutes for the unobserved confounders, which are then used in conjunction with an outcome model to estimate treatment effects over time. We prove that using our method yields unbiased estimates of individualized treatment responses over time. Using simulated and real medical data, we demonstrate the efficacy of our method in deconfounding the estimation of treatment responses over time.
AttDMM: An Attentive Deep Markov Model for Risk Scoring in Intensive Care Units
Feb 17, 2021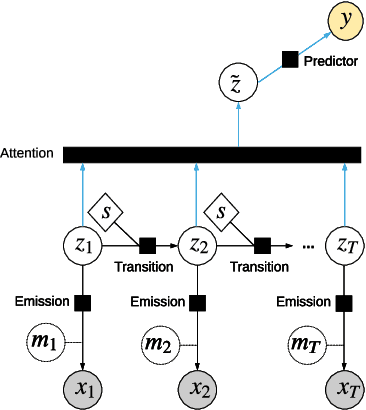

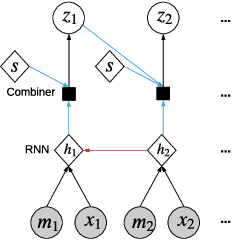

Clinical practice in intensive care units (ICUs) requires early warnings when a patient's condition is about to deteriorate so that preventive measures can be undertaken. To this end, prediction algorithms have been developed that estimate the risk of mortality in ICUs. In this work, we propose a novel generative deep probabilistic model for real-time risk scoring in ICUs. Specifically, we develop an attentive deep Markov model called AttDMM. To the best of our knowledge, AttDMM is the first ICU prediction model that jointly learns both long-term disease dynamics (via attention) and different disease states in health trajectory (via a latent variable model). Our evaluations were based on an established baseline dataset (MIMIC-III) with 53,423 ICU stays. The results confirm that compared to state-of-the-art baselines, our AttDMM was superior: AttDMM achieved an area under the receiver operating characteristic curve (AUROC) of 0.876, which yielded an improvement over the state-of-the-art method by 2.2%. In addition, the risk score from the AttDMM provided warnings several hours earlier. Thereby, our model shows a path towards identifying patients at risk so that health practitioners can intervene early and save patient lives.