 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Condition Invariant Features for Retrieval-Based Localization from 1M Images
Aug 27, 2020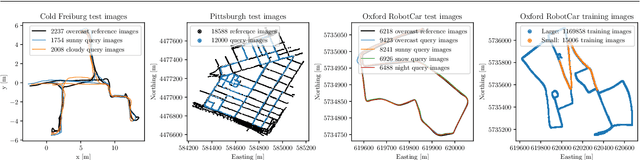

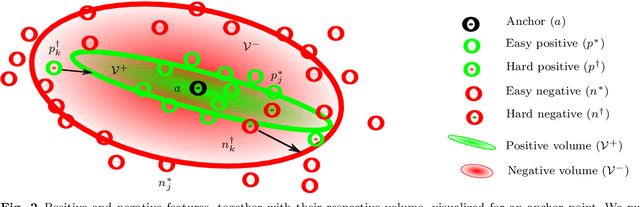
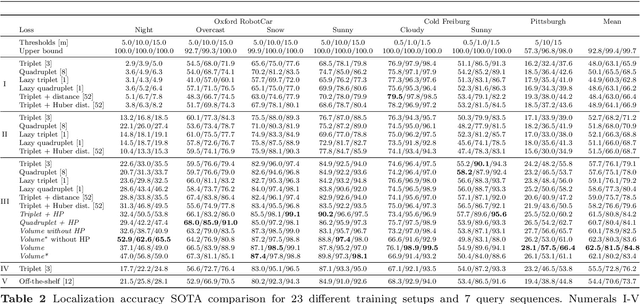
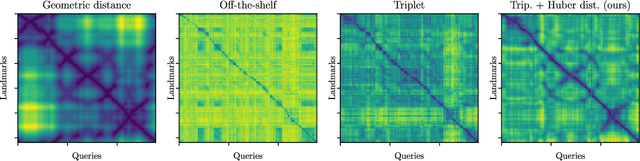
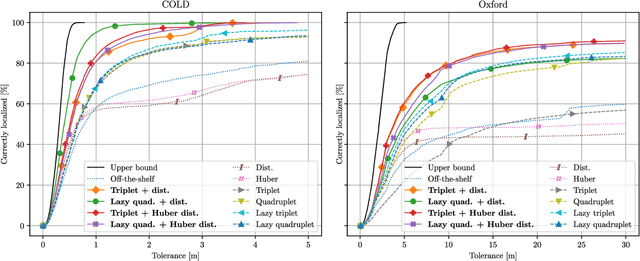
Image features for retrieval-based localization must be invariant to dynamic objects (e.g. cars) as well as seasonal and daytime changes. Such invariances are, up to some extent, learnable with existing methods using triplet-like losses, given a large number of diverse training images. However, due to the high algorithmic training complexity, there exists insufficient comparison between different loss functions on large datasets. In this paper, we train and evaluate several localization methods on three different benchmark datasets, including Oxford RobotCar with over one million images. This large scale evaluation yields valuable insights into the generalizability and performance of retrieval-based localization. Based on our findings, we develop a novel method for learning more accurate and better generalizing localization features. It consists of two main contributions: (i) a feature volume-based loss function, and (ii) hard positive and pairwise negative mining. On the challenging Oxford RobotCar night condition, our method outperforms the well-known triplet loss by 24.4% in localization accuracy within 5m.
Geometrically Mappable Image Features
Mar 21, 2020

Vision-based localization of an agent in a map is an important problem in robotics and computer vision. In that context, localization by learning matchable image features is gaining popularity due to recent advances in machine learning. Features that uniquely describe the visual contents of images have a wide range of applications, including image retrieval and understanding. In this work, we propose a method that learns image features targeted for image-retrieval-based localization. Retrieval-based localization has several benefits, such as easy maintenance and quick computation. However, the state-of-the-art features only provide visual similarity scores which do not explicitly reveal the geometric distance between query and retrieved images. Knowing this distance is highly desirable for accurate localization, especially when the reference images are sparsely distributed in the scene. Therefore, we propose a novel loss function for learning image features which are both visually representative and geometrically relatable. This is achieved by guiding the learning process such that the feature and geometric distances between images are directly proportional. In our experiments we show that our features not only offer significantly better localization accuracy, but also allow to estimate the trajectory of a query sequence in absence of the reference images.
* Implementation available at https://github.com/janinethoma/geometrically_mappable
Sliced Wasserstein Generative Models
Apr 13, 2019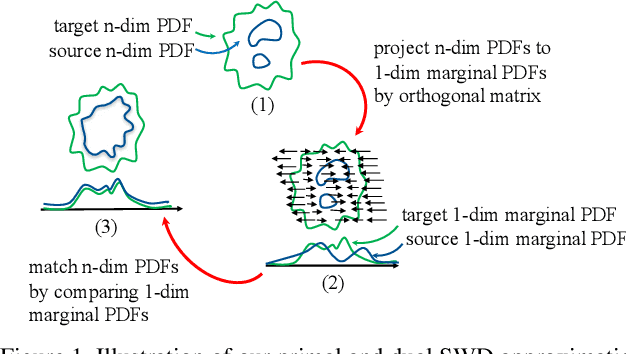
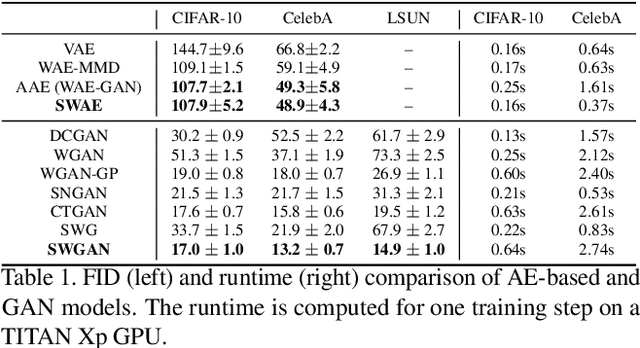
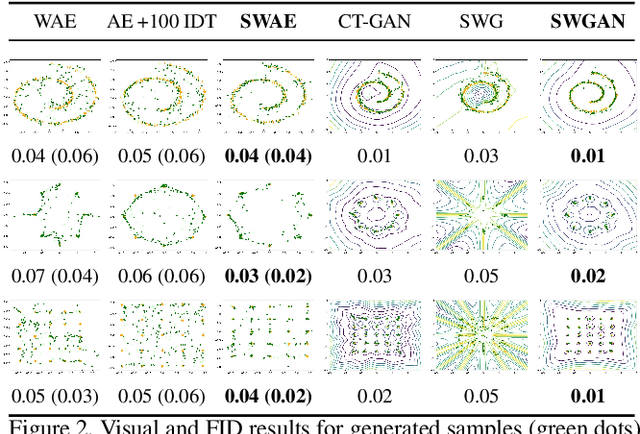
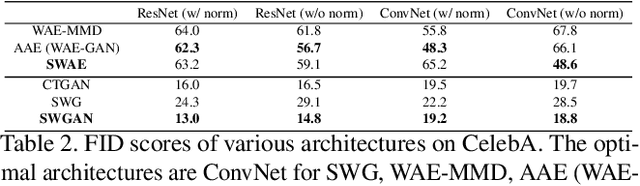
In generative modeling, the Wasserstein distance (WD) has emerged as a useful metric to measure the discrepancy between generated and real data distributions. Unfortunately, it is challenging to approximate the WD of high-dimensional distributions. In contrast, the sliced Wasserstein distance (SWD) factorizes high-dimensional distributions into their multiple one-dimensional marginal distributions and is thus easier to approximate. In this paper, we introduce novel approximations of the primal and dual SWD. Instead of using a large number of random projections, as it is done by conventional SWD approximation methods, we propose to approximate SWDs with a small number of parameterized orthogonal projections in an end-to-end deep learning fashion. As concrete applications of our SWD approximations, we design two types of differentiable SWD blocks to equip modern generative frameworks---Auto-Encoders (AE) and Generative Adversarial Networks (GAN). In the experiments, we not only show the superiority of the proposed generative models on standard image synthesis benchmarks, but also demonstrate the state-of-the-art performance on challenging high resolution image and video generation in an unsupervised manner.
Image-based Navigation using Visual Features and Map
Dec 10, 2018


Building on progress in feature representations for image retrieval, image-based localization has seen a surge of research interest. Image-based localization has the advantage of being inexpensive and efficient, often avoiding the use of 3D metric maps altogether. This said, the need to maintain a large number of reference images as an effective support of localization in a scene, nonetheless calls for them to be organized in a map structure of some kind. The problem of localization often arises as part of a navigation process. We are, therefore, interested in summarizing the reference images as a set of landmarks, which meet the requirements for image-based navigation. A contribution of the paper is to formulate such a set of requirements for the two sub-tasks involved: map construction and self localization. These requirements are then exploited for compact map representation and accurate self-localization, using the framework of a network flow problem. During this process, we formulate the map construction and self-localization problems as convex quadratic and second-order cone programs, respectively. We evaluate our methods on publicly available indoor and outdoor datasets, where they outperform existing methods significantly.
Wasserstein Divergence for GANs
Sep 05, 2018
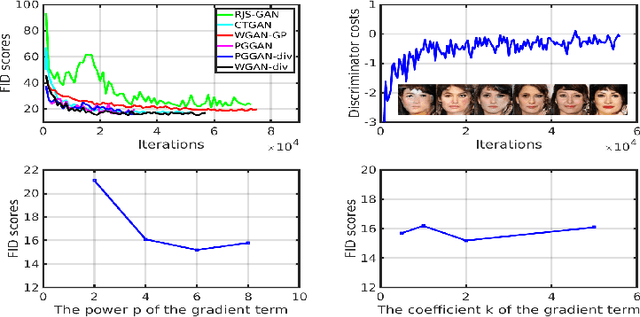
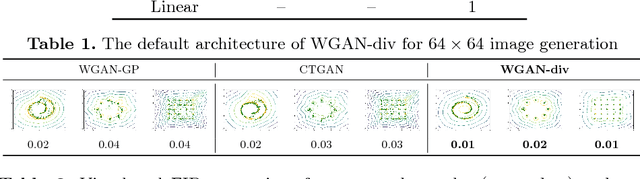

In many domains of computer vision, generative adversarial networks (GANs) have achieved great success, among which the family of Wasserstein GANs (WGANs) is considered to be state-of-the-art due to the theoretical contributions and competitive qualitative performance. However, it is very challenging to approximate the $k$-Lipschitz constraint required by the Wasserstein-1 metric~(W-met). In this paper, we propose a novel Wasserstein divergence~(W-div), which is a relaxed version of W-met and does not require the $k$-Lipschitz constraint. As a concrete application, we introduce a Wasserstein divergence objective for GANs~(WGAN-div), which can faithfully approximate W-div through optimization. Under various settings, including progressive growing training, we demonstrate the stability of the proposed WGAN-div owing to its theoretical and practical advantages over WGANs. Also, we study the quantitative and visual performance of WGAN-div on standard image synthesis benchmarks of computer vision, showing the superior performance of WGAN-div compared to the state-of-the-art methods.