 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal forecasting for surgical instrument trajectory
Mar 06, 2025


Forecasting surgical instrument trajectories and predicting the next surgical action recently started to attract attention from the research community. Both these tasks are crucial for automation and assistance in endoscopy surgery. Given the safety-critical nature of these tasks, reliable uncertainty quantification is essential. Conformal prediction is a fast-growing and widely recognized framework for uncertainty estimation in machine learning and computer vision, offering distribution-free, theoretically valid prediction intervals. In this work, we explore the application of standard conformal prediction and conformalized quantile regression to estimate uncertainty in forecasting surgical instrument motion, i.e., predicting direction and magnitude of surgical instruments' future motion. We analyze and compare their coverage and interval sizes, assessing the impact of multiple hypothesis testing and correction methods. Additionally, we show how these techniques can be employed to produce useful uncertainty heatmaps. To the best of our knowledge, this is the first study applying conformal prediction to surgical guidance, marking an initial step toward constructing principled prediction intervals with formal coverage guarantees in this domain.
Expert load matters: operating networks at high accuracy and low manual effort
Aug 09, 2023In human-AI collaboration systems for critical applications, in order to ensure minimal error, users should set an operating point based on model confidence to determine when the decision should be delegated to human experts. Samples for which model confidence is lower than the operating point would be manually analysed by experts to avoid mistakes. Such systems can become truly useful only if they consider two aspects: models should be confident only for samples for which they are accurate, and the number of samples delegated to experts should be minimized. The latter aspect is especially crucial for applications where available expert time is limited and expensive, such as healthcare. The trade-off between the model accuracy and the number of samples delegated to experts can be represented by a curve that is similar to an ROC curve, which we refer to as confidence operating characteristic (COC) curve. In this paper, we argue that deep neural networks should be trained by taking into account both accuracy and expert load and, to that end, propose a new complementary loss function for classification that maximizes the area under this COC curve. This promotes simultaneously the increase in network accuracy and the reduction in number of samples delegated to humans. We perform experiments on multiple computer vision and medical image datasets for classification. Our results demonstrate that the proposed loss improves classification accuracy and delegates less number of decisions to experts, achieves better out-of-distribution samples detection and on par calibration performance compared to existing loss functions.
Constrained Optimization for Training Deep Neural Networks Under Class Imbalance
Feb 21, 2021
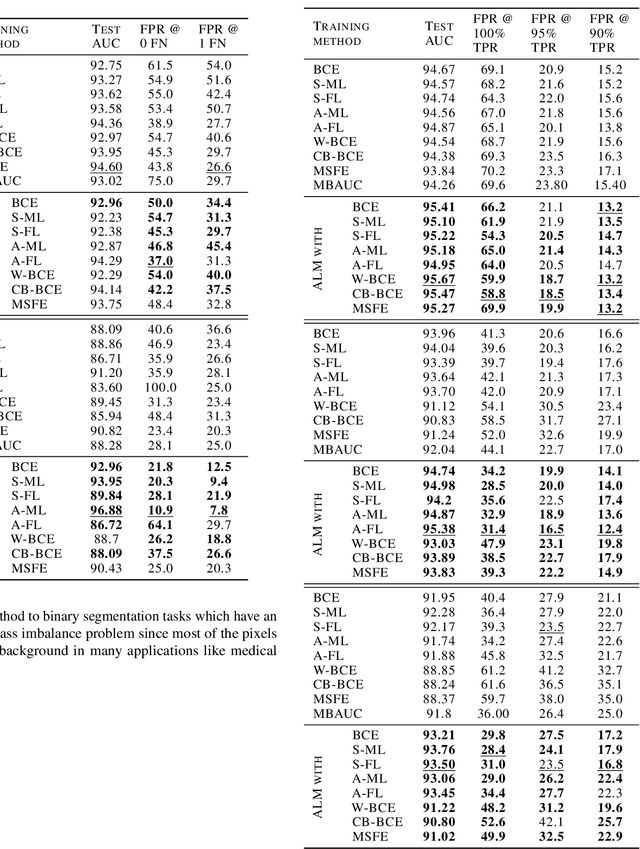
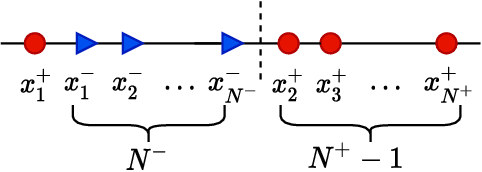
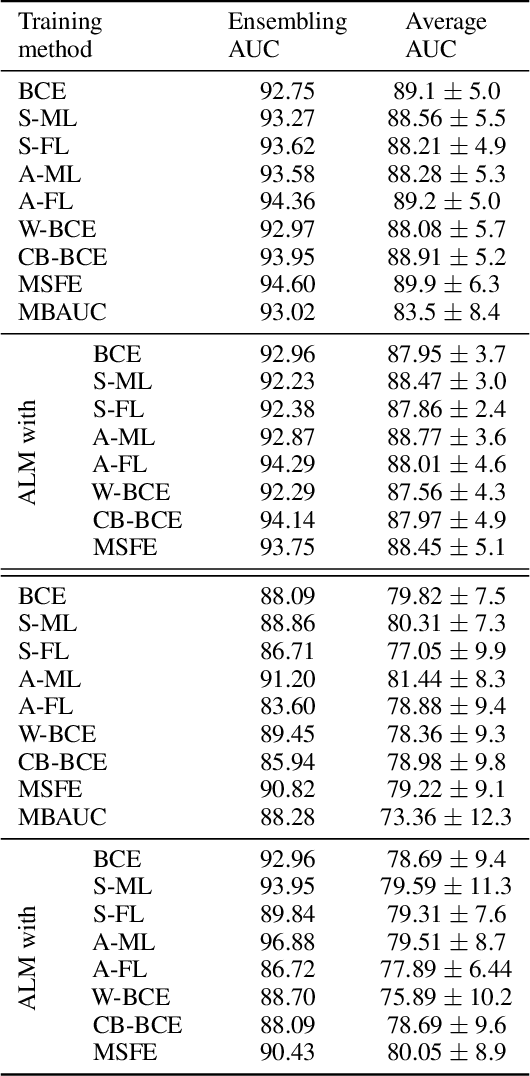
Deep neural networks (DNNs) are notorious for making more mistakes for the classes that have substantially fewer samples than the others during training. Such class imbalance is ubiquitous in clinical applications and very crucial to handle because the classes with fewer samples most often correspond to critical cases (e.g., cancer) where misclassifications can have severe consequences. Not to miss such cases, binary classifiers need to be operated at high True Positive Rates (TPR) by setting a higher threshold but this comes at the cost of very high False Positive Rates (FPR) for problems with class imbalance. Existing methods for learning under class imbalance most often do not take this into account. We argue that prediction accuracy should be improved by emphasizing reducing FPRs at high TPRs for problems where misclassification of the positive samples are associated with higher cost. To this end, we pose the training of a DNN for binary classification as a constrained optimization problem and introduce a novel constraint that can be used with existing loss functions to enforce maximal area under the ROC curve (AUC). We solve the resulting constrained optimization problem using an Augmented Lagrangian method (ALM), where the constraint emphasizes reduction of FPR at high TPR. We present experimental results for image-based classification applications using the CIFAR10 and an in-house medical imaging dataset. Our results demonstrate that the proposed method almost always improves the loss functions it is used with by attaining lower FPR at high TPR and higher or equal AUC.