 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Weight Uncertainty in Neural Networks
Paper and Code
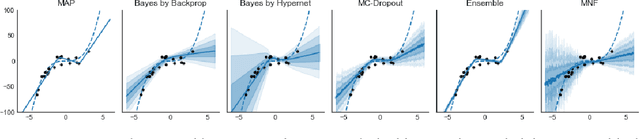

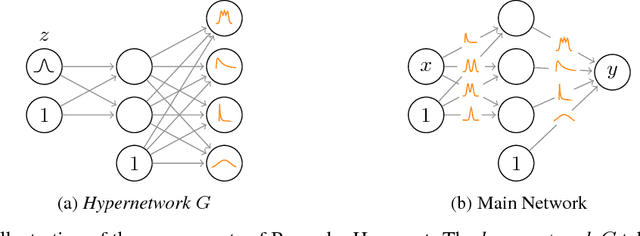

Modern neural networks tend to be overconfident on unseen, noisy or incorrectly labelled data and do not produce meaningful uncertainty measures. Bayesian deep learning aims to address this shortcoming with variational approximations (such as Bayes by Backprop or Multiplicative Normalising Flows). However, current approaches have limitations regarding flexibility and scalability. We introduce Bayes by Hypernet (BbH), a new method of variational approximation that interprets hypernetworks as implicit distributions. It naturally uses neural networks to model arbitrarily complex distributions and scales to modern deep learning architectures. In our experiments, we demonstrate that our method achieves competitive accuracies and predictive uncertainties on MNIST and a CIFAR5 task, while being the most robust against adversarial attacks.