 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Universal Style Transfer on High-resolution Images via Zero-channel Pruning
Jun 23, 2020
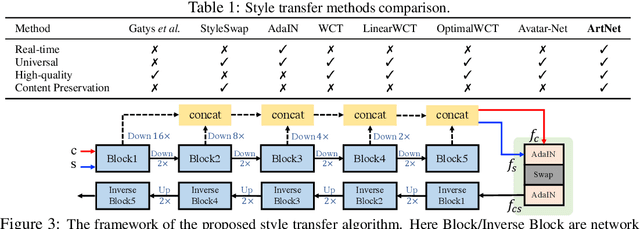


Extracting effective deep features to represent content and style information is the key to universal style transfer. Most existing algorithms use VGG19 as the feature extractor, which incurs a high computational cost and impedes real-time style transfer on high-resolution images. In this work, we propose a lightweight alternative architecture - ArtNet, which is based on GoogLeNet, and later pruned by a novel channel pruning method named Zero-channel Pruning specially designed for style transfer approaches. Besides, we propose a theoretically sound sandwich swap transform (S2) module to transfer deep features, which can create a pleasing holistic appearance and good local textures with an improved content preservation ability. By using ArtNet and S2, our method is 2.3 to 107.4 times faster than state-of-the-art approaches. The comprehensive experiments demonstrate that ArtNet can achieve universal, real-time, and high-quality style transfer on high-resolution images simultaneously, (68.03 FPS on 512 times 512 images).
Hallucinating Optical Flow Features for Video Classification
May 28, 2019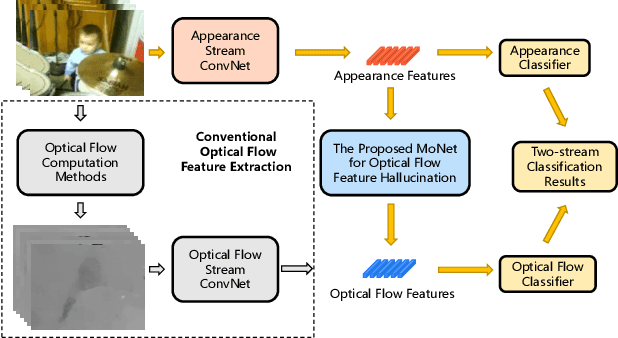
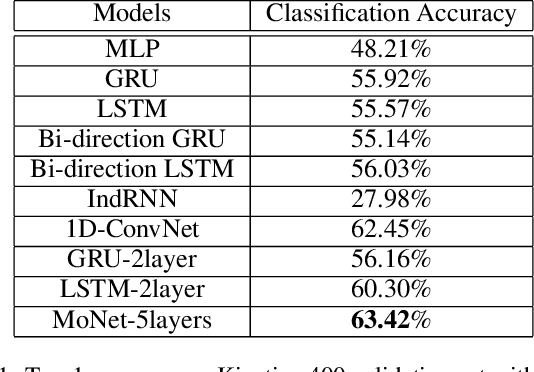
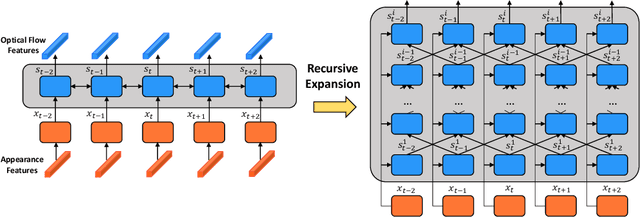
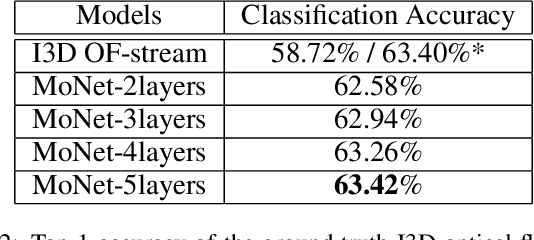
Appearance and motion are two key components to depict and characterize the video content. Currently, the two-stream models have achieved state-of-the-art performances on video classification. However, extracting motion information, specifically in the form of optical flow features, is extremely computationally expensive, especially for large-scale video classification. In this paper, we propose a motion hallucination network, namely MoNet, to imagine the optical flow features from the appearance features, with no reliance on the optical flow computation. Specifically, MoNet models the temporal relationships of the appearance features and exploits the contextual relationships of the optical flow features with concurrent connections. Extensive experimental results demonstrate that the proposed MoNet can effectively and efficiently hallucinate the optical flow features, which together with the appearance features consistently improve the video classification performances. Moreover, MoNet can help cutting down almost a half of computational and data-storage burdens for the two-stream video classification. Our code is available at: https://github.com/YongyiTang92/MoNet-Features.
Non-local NetVLAD Encoding for Video Classification
Sep 29, 2018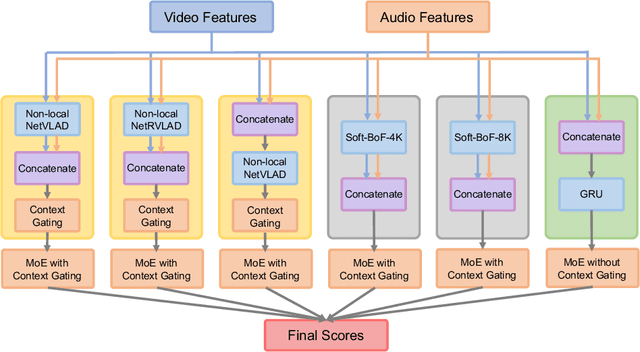
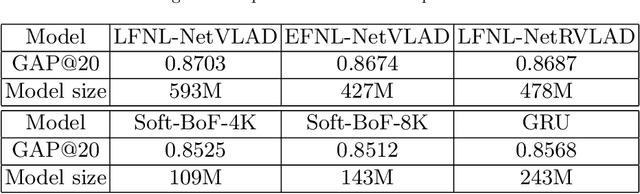

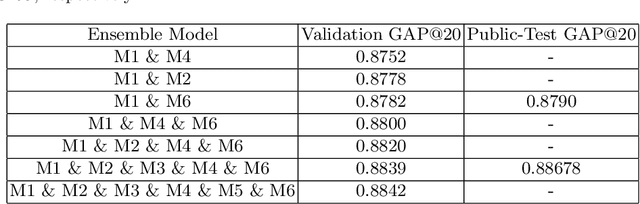
This paper describes our solution for the 2$^\text{nd}$ YouTube-8M video understanding challenge organized by Google AI. Unlike the video recognition benchmarks, such as Kinetics and Moments, the YouTube-8M challenge provides pre-extracted visual and audio features instead of raw videos. In this challenge, the submitted model is restricted to 1GB, which encourages participants focus on constructing one powerful single model rather than incorporating of the results from a bunch of models. Our system fuses six different sub-models into one single computational graph, which are categorized into three families. More specifically, the most effective family is the model with non-local operations following the NetVLAD encoding. The other two family models are Soft-BoF and GRU, respectively. In order to further boost single models performance, the model parameters of different checkpoints are averaged. Experimental results demonstrate that our proposed system can effectively perform the video classification task, achieving 0.88763 on the public test set and 0.88704 on the private set in terms of GAP@20, respectively. We finally ranked at the fourth place in the YouTube-8M video understanding challenge.
Long-Term Human Motion Prediction by Modeling Motion Context and Enhancing Motion Dynamic
May 07, 2018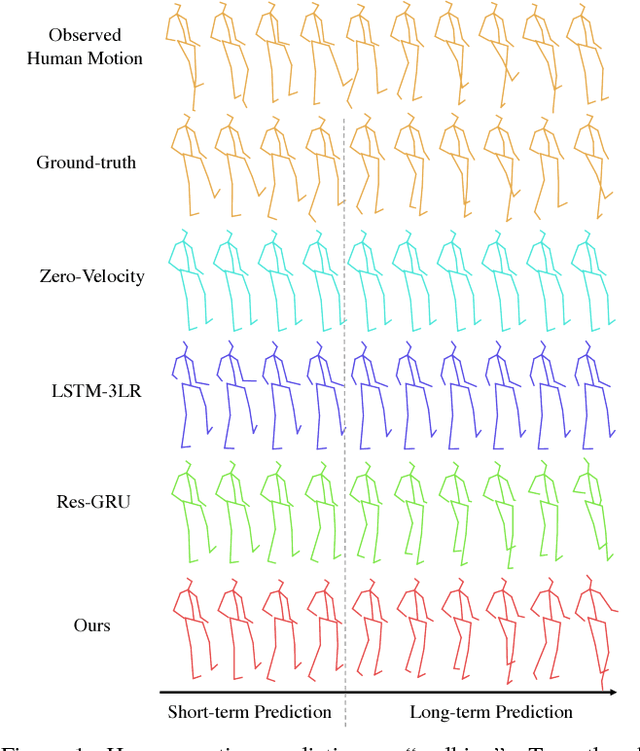

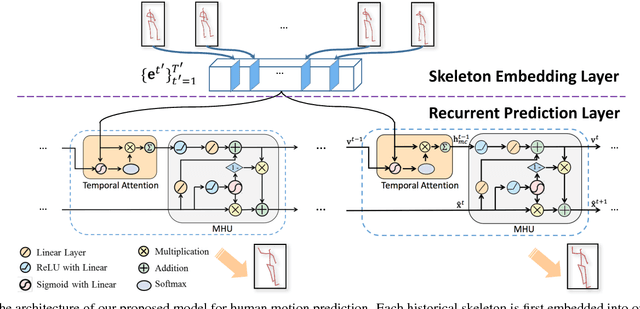
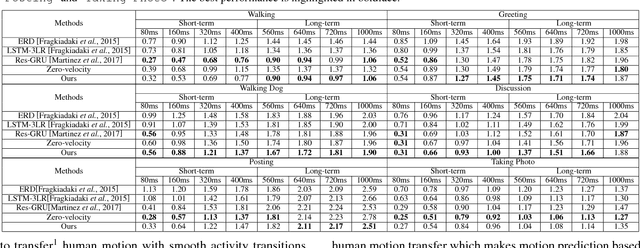
Human motion prediction aims at generating future frames of human motion based on an observed sequence of skeletons. Recent methods employ the latest hidden states of a recurrent neural network (RNN) to encode the historical skeletons, which can only address short-term prediction. In this work, we propose a motion context modeling by summarizing the historical human motion with respect to the current prediction. A modified highway unit (MHU) is proposed for efficiently eliminating motionless joints and estimating next pose given the motion context. Furthermore, we enhance the motion dynamic by minimizing the gram matrix loss for long-term motion prediction. Experimental results show that the proposed model can promisingly forecast the human future movements, which yields superior performances over related state-of-the-art approaches. Moreover, specifying the motion context with the activity labels enables our model to perform human motion transfer.
Latent Embeddings for Collective Activity Recognition
Sep 20, 2017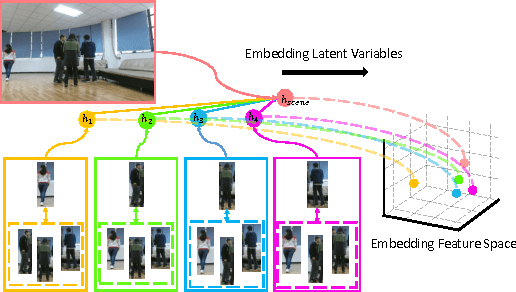

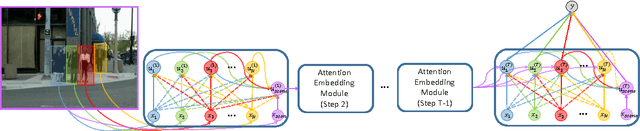

Rather than simply recognizing the action of a person individually, collective activity recognition aims to find out what a group of people is acting in a collective scene. Previ- ous state-of-the-art methods using hand-crafted potentials in conventional graphical model which can only define a limited range of relations. Thus, the complex structural de- pendencies among individuals involved in a collective sce- nario cannot be fully modeled. In this paper, we overcome these limitations by embedding latent variables into feature space and learning the feature mapping functions in a deep learning framework. The embeddings of latent variables build a global relation containing person-group interac- tions and richer contextual information by jointly modeling broader range of individuals. Besides, we assemble atten- tion mechanism during embedding for achieving more com- pact representations. We evaluate our method on three col- lective activity datasets, where we contribute a much larger dataset in this work. The proposed model has achieved clearly better performance as compared to the state-of-the- art methods in our experiments.
Aggregating Frame-level Features for Large-Scale Video Classification
Jul 04, 2017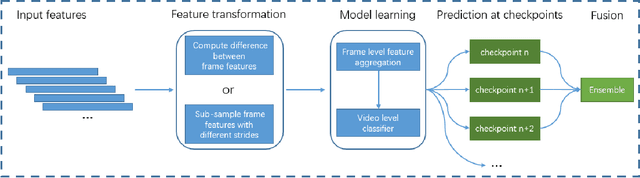
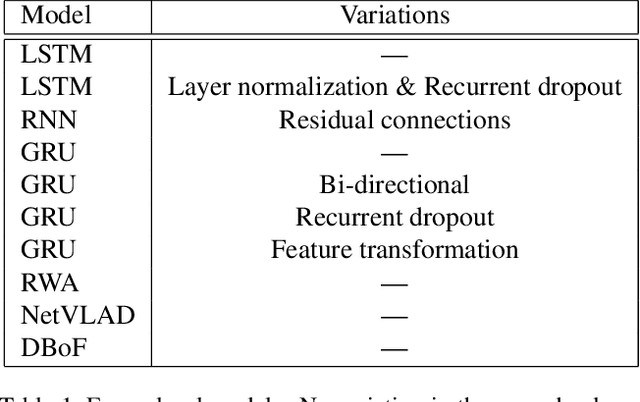
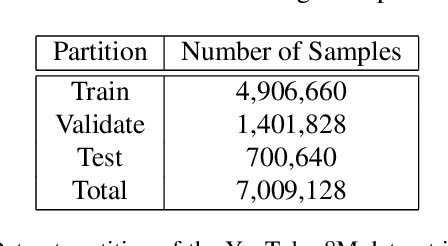
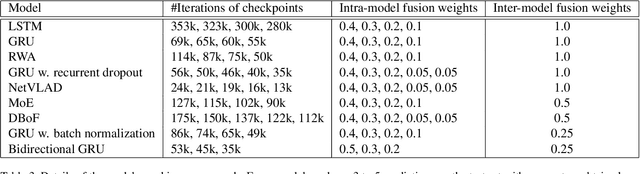
This paper introduces the system we developed for the Google Cloud & YouTube-8M Video Understanding Challenge, which can be considered as a multi-label classification problem defined on top of the large scale YouTube-8M Dataset. We employ a large set of techniques to aggregate the provided frame-level feature representations and generate video-level predictions, including several variants of recurrent neural networks (RNN) and generalized VLAD. We also adopt several fusion strategies to explore the complementarity among the models. In terms of the official metric GAP@20 (global average precision at 20), our best fusion model attains 0.84198 on the public 50\% of test data and 0.84193 on the private 50\% of test data, ranking 4th out of 650 teams worldwide in the competition.