 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPD-Agents: A Large Language Model-Driven Multi-Agents Collaborative Framework for Automated Page Design
Nov 18, 2025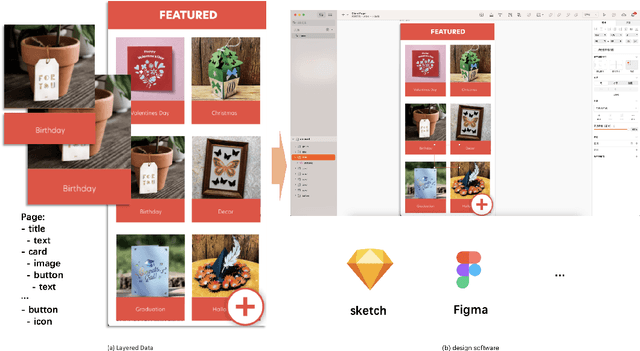
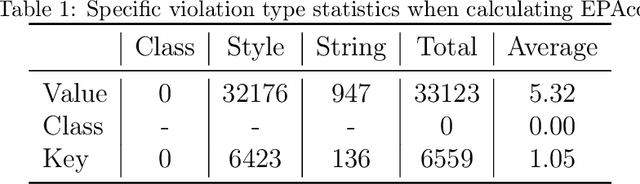
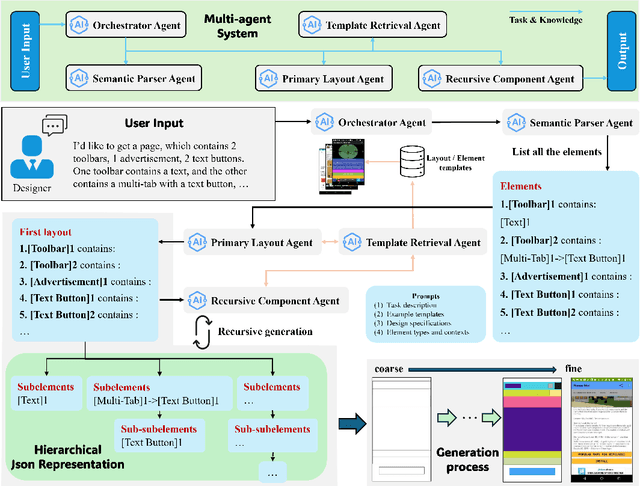
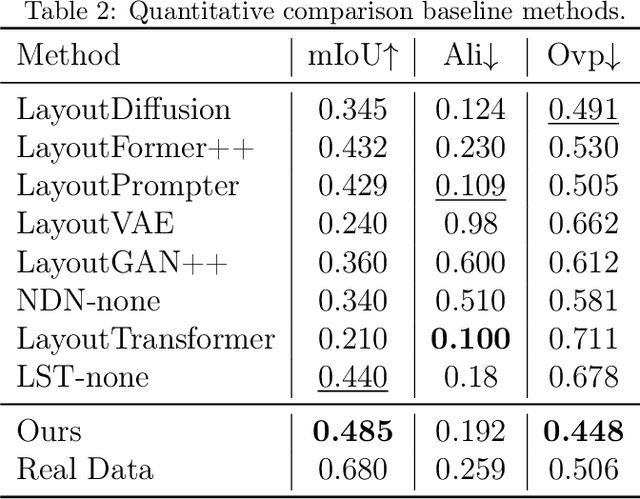
Layout design is a crucial step in developing mobile app pages. However, crafting satisfactory designs is time-intensive for designers: they need to consider which controls and content to present on the page, and then repeatedly adjust their size, position, and style for better aesthetics and structure. Although many design software can now help to perform these repetitive tasks, extensive training is needed to use them effectively. Moreover, collaborative design across app pages demands extra time to align standards and ensure consistent styling. In this work, we propose APD-agents, a large language model (LLM) driven multi-agent framework for automated page design in mobile applications. Our framework contains OrchestratorAgent, SemanticParserAgent, PrimaryLayoutAgent, TemplateRetrievalAgent, and RecursiveComponentAgent. Upon receiving the user's description of the page, the OrchestratorAgent can dynamically can direct other agents to accomplish users' design task. To be specific, the SemanticParserAgent is responsible for converting users' descriptions of page content into structured data. The PrimaryLayoutAgent can generate an initial coarse-grained layout of this page. The TemplateRetrievalAgent can fetch semantically relevant few-shot examples and enhance the quality of layout generation. Besides, a RecursiveComponentAgent can be used to decide how to recursively generate all the fine-grained sub-elements it contains for each element in the layout. Our work fully leverages the automatic collaboration capabilities of large-model-driven multi-agent systems. Experimental results on the RICO dataset show that our APD-agents achieve state-of-the-art performance.
Real-Time Referring Expression Comprehension by Single-Stage Grounding Network
Dec 09, 2018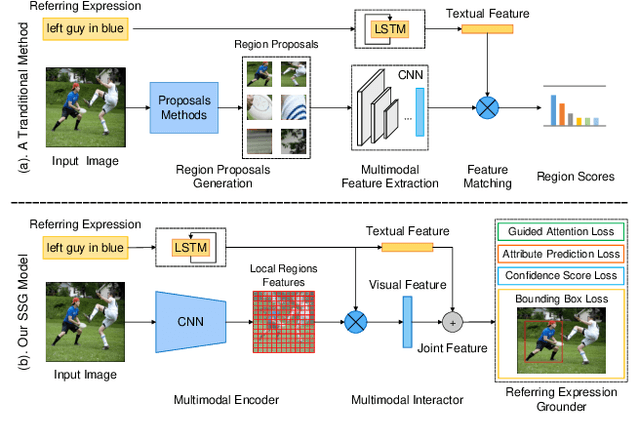
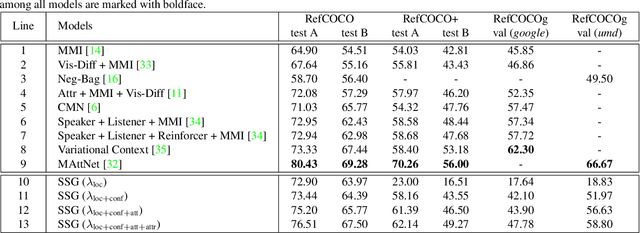
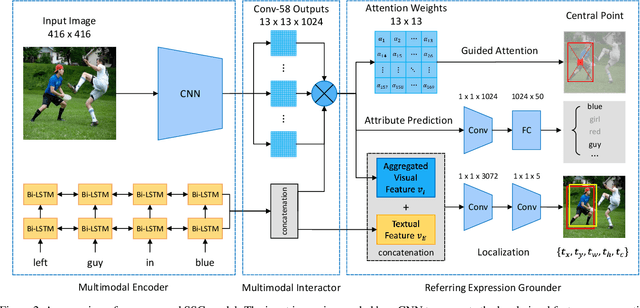
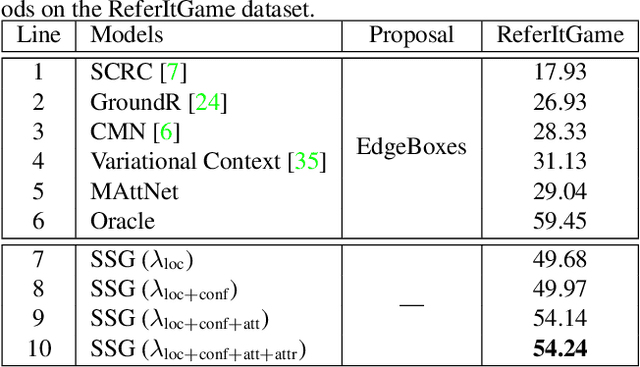
In this paper, we propose a novel end-to-end model, namely Single-Stage Grounding network (SSG), to localize the referent given a referring expression within an image. Different from previous multi-stage models which rely on object proposals or detected regions, our proposed model aims to comprehend a referring expression through one single stage without resorting to region proposals as well as the subsequent region-wise feature extraction. Specifically, a multimodal interactor is proposed to summarize the local region features regarding the referring expression attentively. Subsequently, a grounder is proposed to localize the referring expression within the given image directly. For further improving the localization accuracy, a guided attention mechanism is proposed to enforce the grounder to focus on the central region of the referent. Moreover, by exploiting and predicting visual attribute information, the grounder can further distinguish the referent objects within an image and thereby improve the model performance. Experiments on RefCOCO, RefCOCO+, and RefCOCOg datasets demonstrate that our proposed SSG without relying on any region proposals can achieve comparable performance with other advanced models. Furthermore, our SSG outperforms the previous models and achieves the state-of-art performance on the ReferItGame dataset. More importantly, our SSG is time efficient and can ground a referring expression in a 416*416 image from the RefCOCO dataset in 25ms (40 referents per second) on average with a Nvidia Tesla P40, accomplishing more than 9* speedups over the existing multi-stage models.
Regularizing RNNs for Caption Generation by Reconstructing The Past with The Present
Apr 07, 2018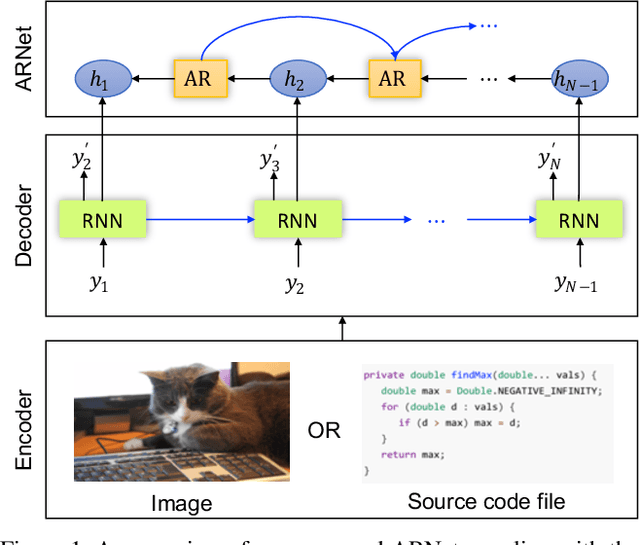



Recently, caption generation with an encoder-decoder framework has been extensively studied and applied in different domains, such as image captioning, code captioning, and so on. In this paper, we propose a novel architecture, namely Auto-Reconstructor Network (ARNet), which, coupling with the conventional encoder-decoder framework, works in an end-to-end fashion to generate captions. ARNet aims at reconstructing the previous hidden state with the present one, besides behaving as the input-dependent transition operator. Therefore, ARNet encourages the current hidden state to embed more information from the previous one, which can help regularize the transition dynamics of recurrent neural networks (RNNs). Extensive experimental results show that our proposed ARNet boosts the performance over the existing encoder-decoder models on both image captioning and source code captioning tasks. Additionally, ARNet remarkably reduces the discrepancy between training and inference processes for caption generation. Furthermore, the performance on permuted sequential MNIST demonstrates that ARNet can effectively regularize RNN, especially on modeling long-term dependencies. Our code is available at: https://github.com/chenxinpeng/ARNet
Fine-grained Video Attractiveness Prediction Using Multimodal Deep Learning on a Large Real-world Dataset
Apr 07, 2018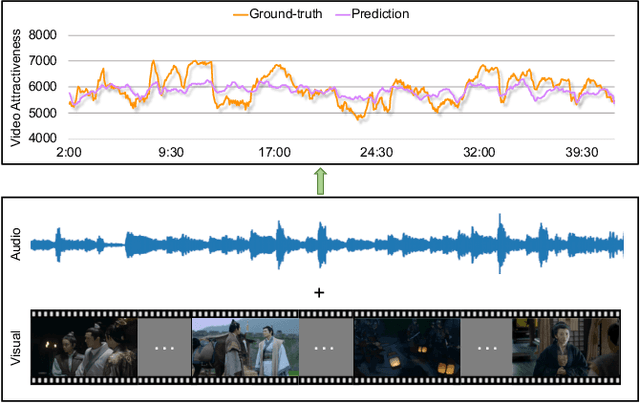
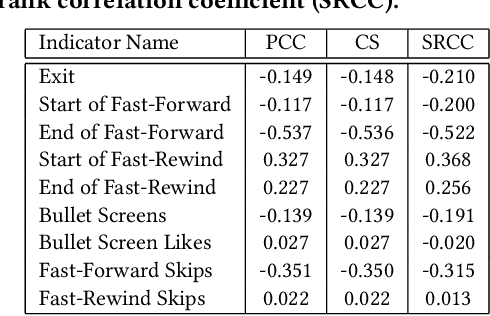
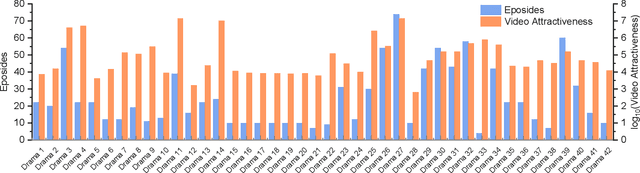
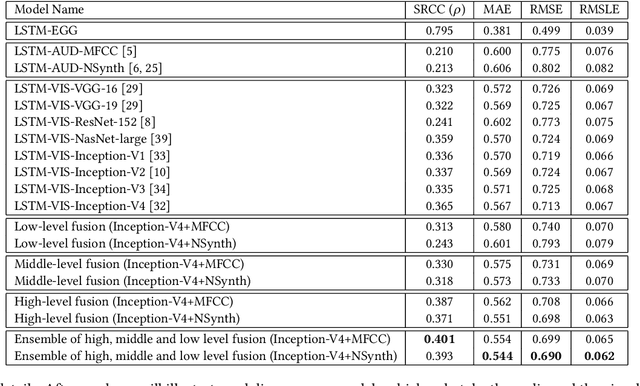
Nowadays, billions of videos are online ready to be viewed and shared. Among an enormous volume of videos, some popular ones are widely viewed by online users while the majority attract little attention. Furthermore, within each video, different segments may attract significantly different numbers of views. This phenomenon leads to a challenging yet important problem, namely fine-grained video attractiveness prediction. However, one major obstacle for such a challenging problem is that no suitable benchmark dataset currently exists. To this end, we construct the first fine-grained video attractiveness dataset, which is collected from one of the most popular video websites in the world. In total, the constructed FVAD consists of 1,019 drama episodes with 780.6 hours covering different categories and a wide variety of video contents. Apart from the large amount of videos, hundreds of millions of user behaviors during watching videos are also included, such as "view counts", "fast-forward", "fast-rewind", and so on, where "view counts" reflects the video attractiveness while other engagements capture the interactions between the viewers and videos. First, we demonstrate that video attractiveness and different engagements present different relationships. Second, FVAD provides us an opportunity to study the fine-grained video attractiveness prediction problem. We design different sequential models to perform video attractiveness prediction by relying solely on video contents. The sequential models exploit the multimodal relationships between visual and audio components of the video contents at different levels. Experimental results demonstrate the effectiveness of our proposed sequential models with different visual and audio representations, the necessity of incorporating the two modalities, and the complementary behaviors of the sequential prediction models at different levels.
Learning to Guide Decoding for Image Captioning
Apr 03, 2018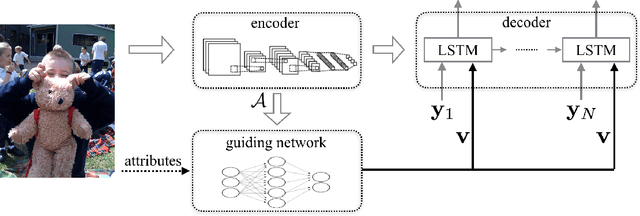
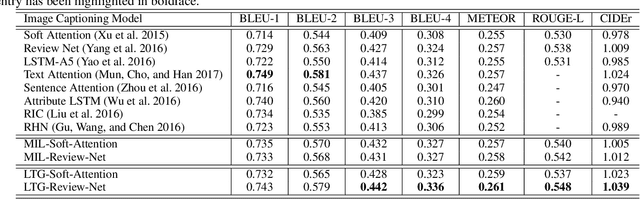
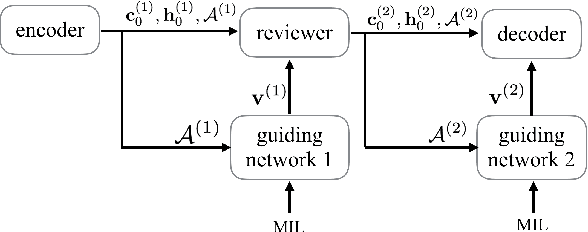
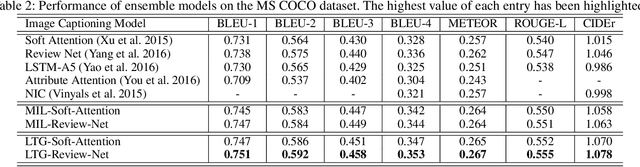
Recently, much advance has been made in image captioning, and an encoder-decoder framework has achieved outstanding performance for this task. In this paper, we propose an extension of the encoder-decoder framework by adding a component called guiding network. The guiding network models the attribute properties of input images, and its output is leveraged to compose the input of the decoder at each time step. The guiding network can be plugged into the current encoder-decoder framework and trained in an end-to-end manner. Hence, the guiding vector can be adaptively learned according to the signal from the decoder, making itself to embed information from both image and language. Additionally, discriminative supervision can be employed to further improve the quality of guidance. The advantages of our proposed approach are verified by experiments carried out on the MS COCO dataset.
Aggregating Frame-level Features for Large-Scale Video Classification
Jul 04, 2017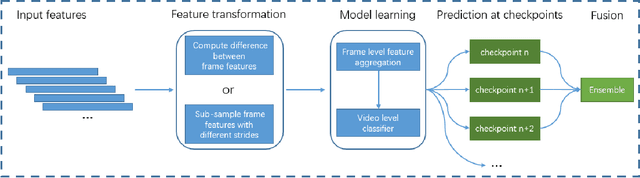
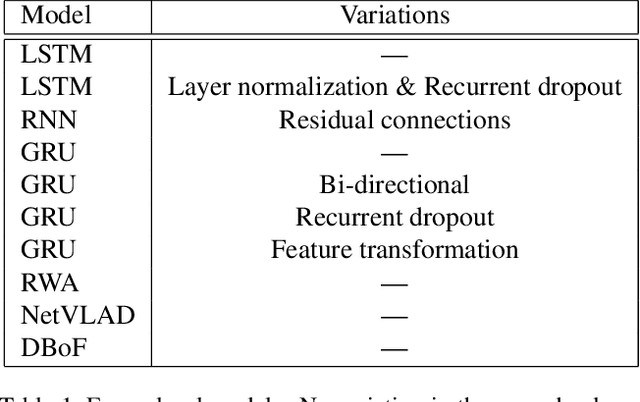
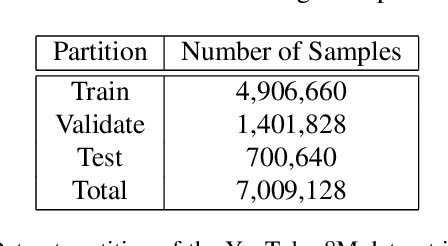
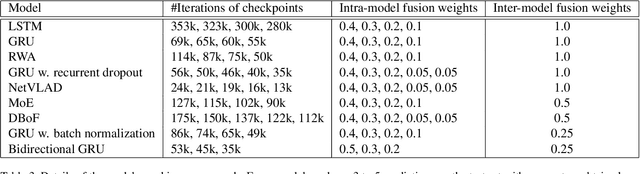
This paper introduces the system we developed for the Google Cloud & YouTube-8M Video Understanding Challenge, which can be considered as a multi-label classification problem defined on top of the large scale YouTube-8M Dataset. We employ a large set of techniques to aggregate the provided frame-level feature representations and generate video-level predictions, including several variants of recurrent neural networks (RNN) and generalized VLAD. We also adopt several fusion strategies to explore the complementarity among the models. In terms of the official metric GAP@20 (global average precision at 20), our best fusion model attains 0.84198 on the public 50\% of test data and 0.84193 on the private 50\% of test data, ranking 4th out of 650 teams worldwide in the competition.