 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelieving Long-tailed Instance Segmentation via Pairwise Class Balance
Jan 08, 2022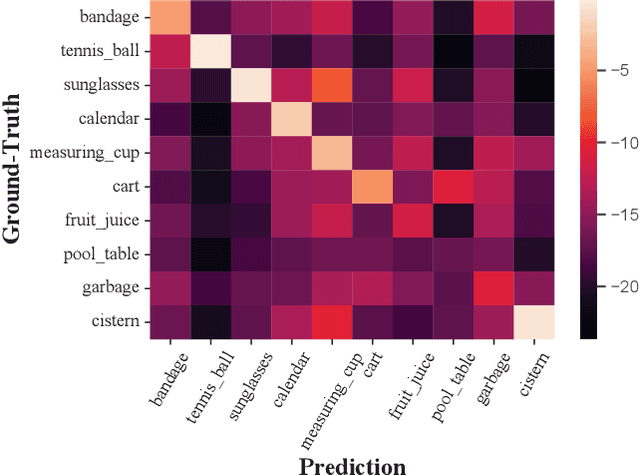
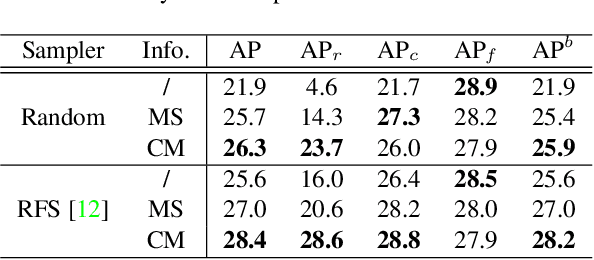
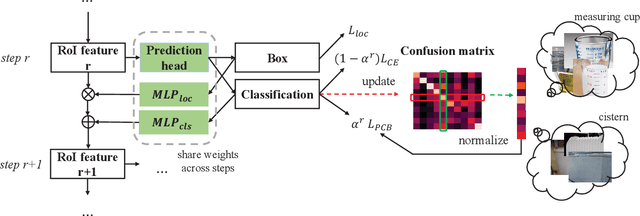
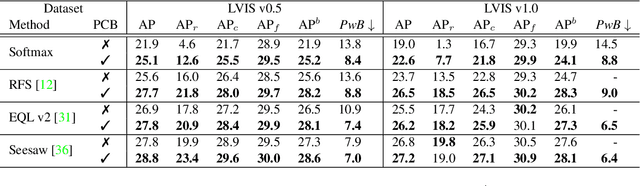
Long-tailed instance segmentation is a challenging task due to the extreme imbalance of training samples among classes. It causes severe biases of the head classes (with majority samples) against the tailed ones. This renders "how to appropriately define and alleviate the bias" one of the most important issues. Prior works mainly use label distribution or mean score information to indicate a coarse-grained bias. In this paper, we explore to excavate the confusion matrix, which carries the fine-grained misclassification details, to relieve the pairwise biases, generalizing the coarse one. To this end, we propose a novel Pairwise Class Balance (PCB) method, built upon a confusion matrix which is updated during training to accumulate the ongoing prediction preferences. PCB generates fightback soft labels for regularization during training. Besides, an iterative learning paradigm is developed to support a progressive and smooth regularization in such debiasing. PCB can be plugged and played to any existing method as a complement. Experimental results on LVIS demonstrate that our method achieves state-of-the-art performance without bells and whistles. Superior results across various architectures show the generalization ability.
Instance-Conditional Knowledge Distillation for Object Detection
Oct 25, 2021
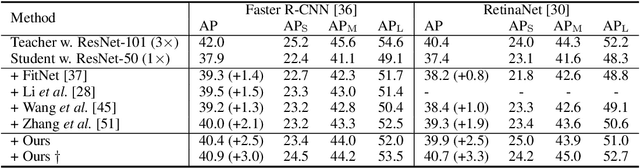
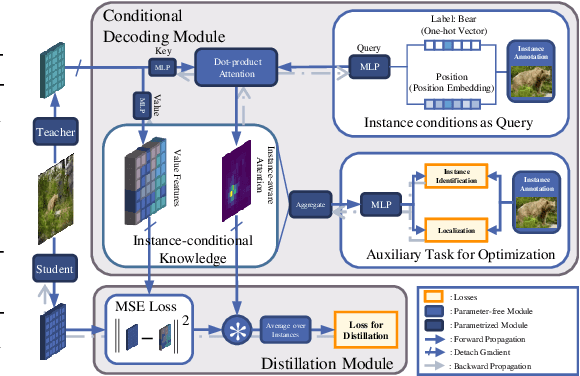
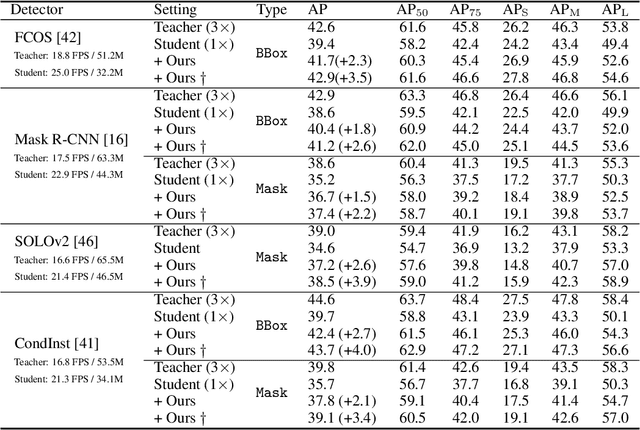
Despite the success of Knowledge Distillation (KD) on image classification, it is still challenging to apply KD on object detection due to the difficulty in locating knowledge. In this paper, we propose an instance-conditional distillation framework to find desired knowledge. To locate knowledge of each instance, we use observed instances as condition information and formulate the retrieval process as an instance-conditional decoding process. Specifically, information of each instance that specifies a condition is encoded as query, and teacher's information is presented as key, we use the attention between query and key to measure the correlation, formulated by the transformer decoder. To guide this module, we further introduce an auxiliary task that directs to instance localization and identification, which are fundamental for detection. Extensive experiments demonstrate the efficacy of our method: we observe impressive improvements under various settings. Notably, we boost RetinaNet with ResNet-50 backbone from 37.4 to 40.7 mAP (+3.3) under 1x schedule, that even surpasses the teacher (40.4 mAP) with ResNet-101 backbone under 3x schedule. Code will be released soon.
LGD: Label-guided Self-distillation for Object Detection
Sep 23, 2021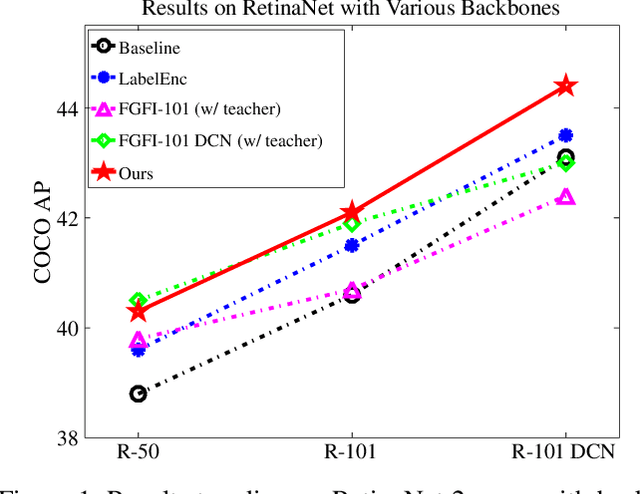
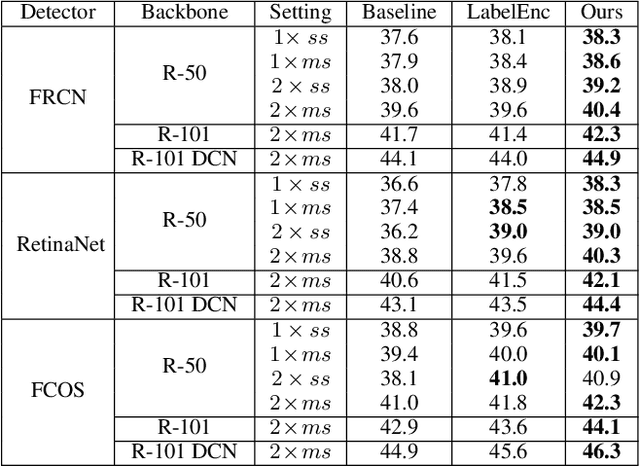
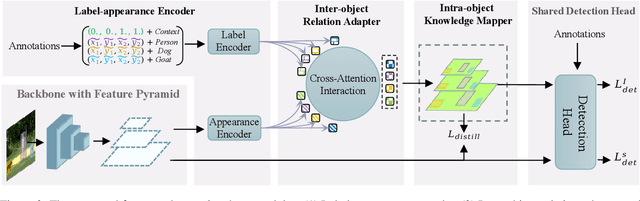
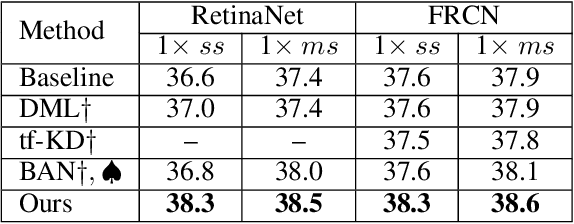
In this paper, we propose the first self-distillation framework for general object detection, termed LGD (Label-Guided self-Distillation). Previous studies rely on a strong pretrained teacher to provide instructive knowledge for distillation. However, this could be unavailable in real-world scenarios. Instead, we generate an instructive knowledge by inter-and-intra relation modeling among objects, requiring only student representations and regular labels. In detail, our framework involves sparse label-appearance encoding, inter-object relation adaptation and intra-object knowledge mapping to obtain the instructive knowledge. Modules in LGD are trained end-to-end with student detector and are discarded in inference. Empirically, LGD obtains decent results on various detectors, datasets, and extensive task like instance segmentation. For example in MS-COCO dataset, LGD improves RetinaNet with ResNet-50 under 2x single-scale training from 36.2% to 39.0% mAP (+ 2.8%). For much stronger detectors like FCOS with ResNeXt-101 DCN v2 under 2x multi-scale training (46.1%), LGD achieves 47.9% (+ 1.8%). For pedestrian detection in CrowdHuman dataset, LGD boosts mMR by 2.3% for Faster R-CNN with ResNet-50. Compared with a classical teacher-based method FGFI, LGD not only performs better without requiring pretrained teacher but also with 51% lower training cost beyond inherent student learning.
Stitcher: Feedback-driven Data Provider for Object Detection
Apr 26, 2020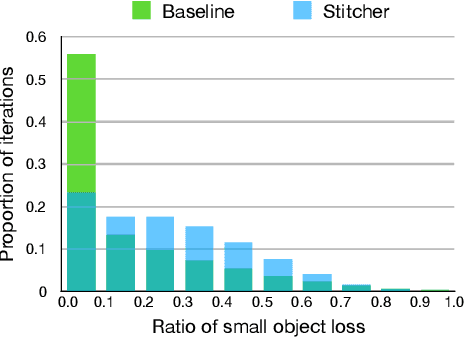

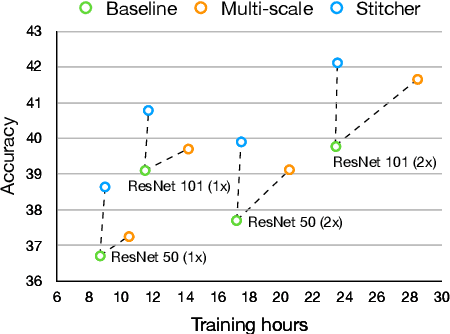
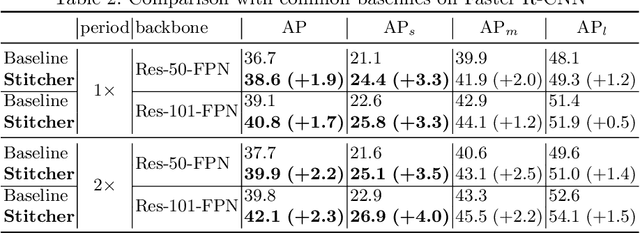
Object detectors commonly vary quality according to scales, where the performance on small objects is the least satisfying. In this paper, we investigate this phenomenon and discover that: in the majority of training iterations, small objects contribute barely to the total loss, causing poor performance with imbalanced optimization. Inspired by this finding, we present Stitcher, a feedback-driven data provider, which aims to train object detectors in a balanced way. In Stitcher, images are resized into smaller components and then stitched into the same size to regular images. Stitched images contain inevitable smaller objects, which would be beneficial with our core idea, to exploit the loss statistics as feedback to guide next-iteration update. Experiments have been conducted on various detectors, backbones, training periods, datasets, and even on instance segmentation. Stitcher steadily improves performance by a large margin in all settings, especially for small objects, with nearly no additional computation in both training and testing stages.
Latent Embeddings for Collective Activity Recognition
Sep 20, 2017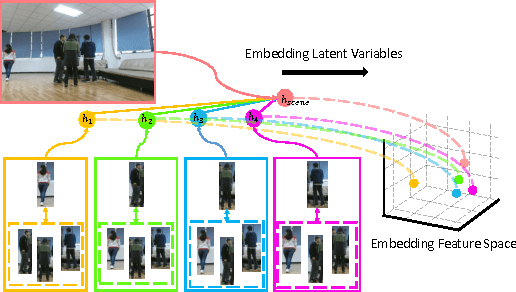

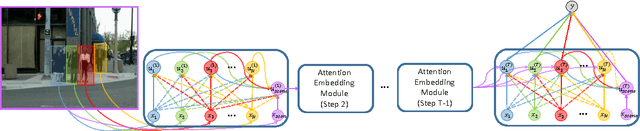

Rather than simply recognizing the action of a person individually, collective activity recognition aims to find out what a group of people is acting in a collective scene. Previ- ous state-of-the-art methods using hand-crafted potentials in conventional graphical model which can only define a limited range of relations. Thus, the complex structural de- pendencies among individuals involved in a collective sce- nario cannot be fully modeled. In this paper, we overcome these limitations by embedding latent variables into feature space and learning the feature mapping functions in a deep learning framework. The embeddings of latent variables build a global relation containing person-group interac- tions and richer contextual information by jointly modeling broader range of individuals. Besides, we assemble atten- tion mechanism during embedding for achieving more com- pact representations. We evaluate our method on three col- lective activity datasets, where we contribute a much larger dataset in this work. The proposed model has achieved clearly better performance as compared to the state-of-the- art methods in our experiments.