 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Feature Distillation for Network Quantization
Jul 20, 2023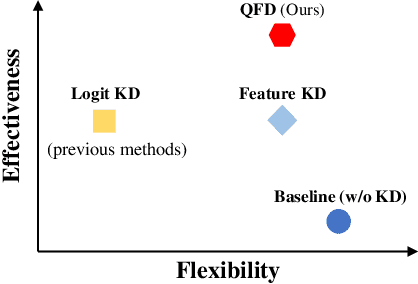
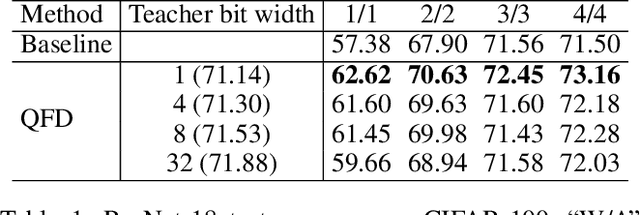
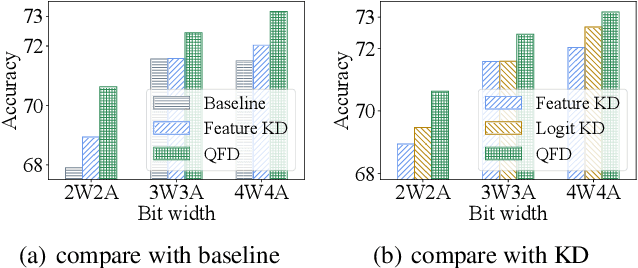
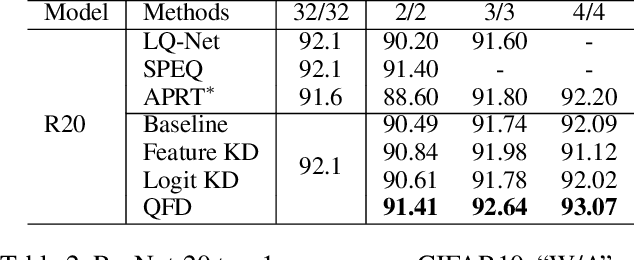
Neural network quantization aims to accelerate and trim full-precision neural network models by using low bit approximations. Methods adopting the quantization aware training (QAT) paradigm have recently seen a rapid growth, but are often conceptually complicated. This paper proposes a novel and highly effective QAT method, quantized feature distillation (QFD). QFD first trains a quantized (or binarized) representation as the teacher, then quantize the network using knowledge distillation (KD). Quantitative results show that QFD is more flexible and effective (i.e., quantization friendly) than previous quantization methods. QFD surpasses existing methods by a noticeable margin on not only image classification but also object detection, albeit being much simpler. Furthermore, QFD quantizes ViT and Swin-Transformer on MS-COCO detection and segmentation, which verifies its potential in real world deployment. To the best of our knowledge, this is the first time that vision transformers have been quantized in object detection and image segmentation tasks.
Coarse Is Better? A New Pipeline Towards Self-Supervised Learning with Uncurated Images
Jun 08, 2023Most self-supervised learning (SSL) methods often work on curated datasets where the object-centric assumption holds. This assumption breaks down in uncurated images. Existing scene image SSL methods try to find the two views from original scene images that are well matched or dense, which is both complex and computationally heavy. This paper proposes a conceptually different pipeline: first find regions that are coarse objects (with adequate objectness), crop them out as pseudo object-centric images, then any SSL method can be directly applied as in a real object-centric dataset. That is, coarse crops benefits scene images SSL. A novel cropping strategy that produces coarse object box is proposed. The new pipeline and cropping strategy successfully learn quality features from uncurated datasets without ImageNet. Experiments show that our pipeline outperforms existing SSL methods (MoCo-v2, DenseCL and MAE) on classification, detection and segmentation tasks. We further conduct extensively ablations to verify that: 1) the pipeline do not rely on pretrained models; 2) the cropping strategy is better than existing object discovery methods; 3) our method is not sensitive to hyperparameters and data augmentations.
Relieving Long-tailed Instance Segmentation via Pairwise Class Balance
Jan 08, 2022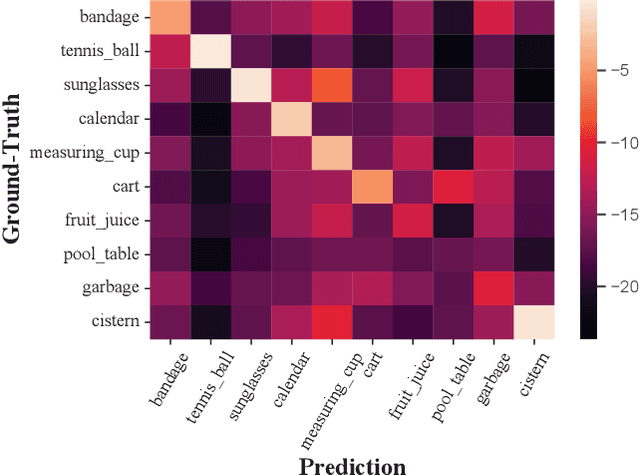
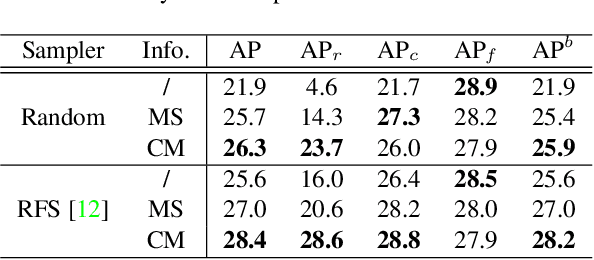
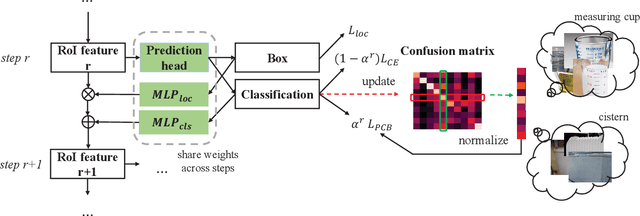
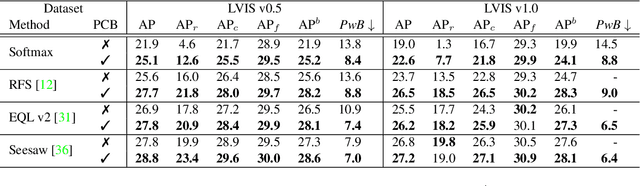
Long-tailed instance segmentation is a challenging task due to the extreme imbalance of training samples among classes. It causes severe biases of the head classes (with majority samples) against the tailed ones. This renders "how to appropriately define and alleviate the bias" one of the most important issues. Prior works mainly use label distribution or mean score information to indicate a coarse-grained bias. In this paper, we explore to excavate the confusion matrix, which carries the fine-grained misclassification details, to relieve the pairwise biases, generalizing the coarse one. To this end, we propose a novel Pairwise Class Balance (PCB) method, built upon a confusion matrix which is updated during training to accumulate the ongoing prediction preferences. PCB generates fightback soft labels for regularization during training. Besides, an iterative learning paradigm is developed to support a progressive and smooth regularization in such debiasing. PCB can be plugged and played to any existing method as a complement. Experimental results on LVIS demonstrate that our method achieves state-of-the-art performance without bells and whistles. Superior results across various architectures show the generalization ability.
Distilling Virtual Examples for Long-tailed Recognition
Mar 28, 2021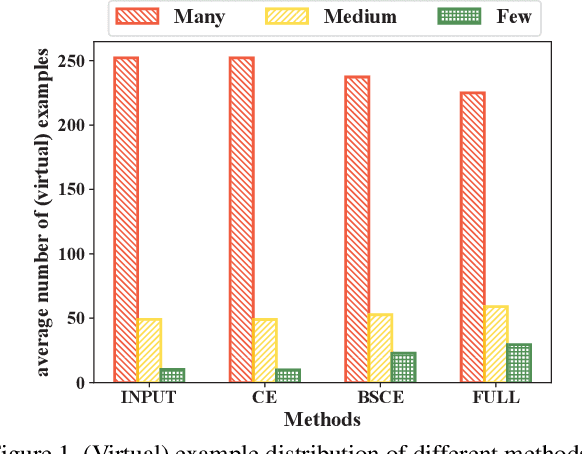
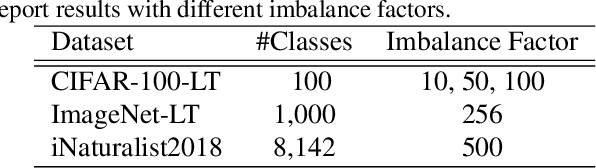
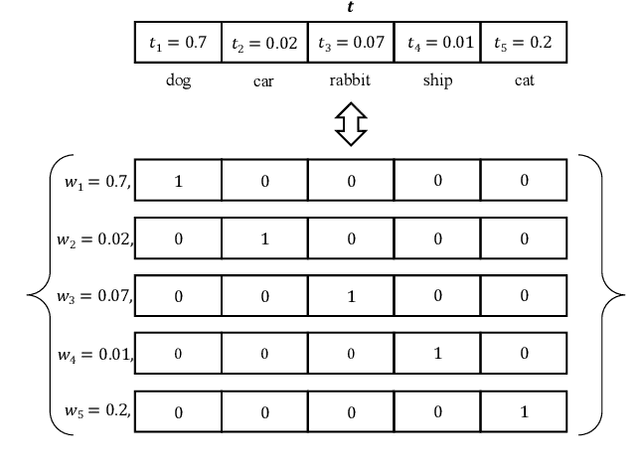
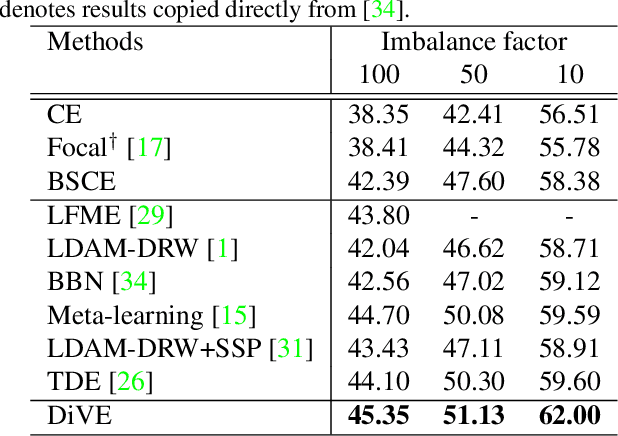
In this paper, we tackle the long-tailed visual recognition problem from the knowledge distillation perspective by proposing a Distill the Virtual Examples (DiVE) method. Specifically, by treating the predictions of a teacher model as virtual examples, we prove that distilling from these virtual examples is equivalent to label distribution learning under certain constraints. We show that when the virtual example distribution becomes flatter than the original input distribution, the under-represented tail classes will receive significant improvements, which is crucial in long-tailed recognition. The proposed DiVE method can explicitly tune the virtual example distribution to become flat. Extensive experiments on three benchmark datasets, including the large-scale iNaturalist ones, justify that the proposed DiVE method can significantly outperform state-of-the-art methods. Furthermore, additional analyses and experiments verify the virtual example interpretation, and demonstrate the effectiveness of tailored designs in DiVE for long-tailed problems.