 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-local NetVLAD Encoding for Video Classification
Paper and Code
Sep 29, 2018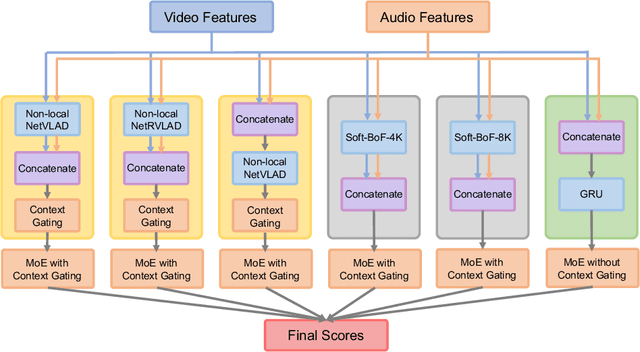
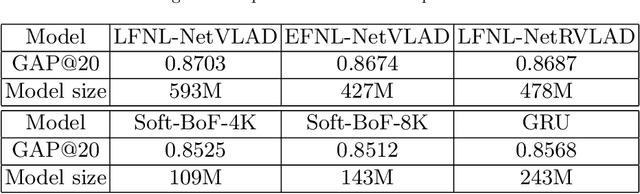

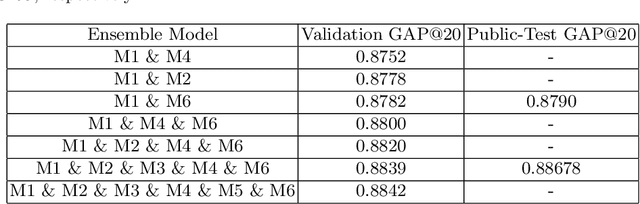
This paper describes our solution for the 2$^\text{nd}$ YouTube-8M video understanding challenge organized by Google AI. Unlike the video recognition benchmarks, such as Kinetics and Moments, the YouTube-8M challenge provides pre-extracted visual and audio features instead of raw videos. In this challenge, the submitted model is restricted to 1GB, which encourages participants focus on constructing one powerful single model rather than incorporating of the results from a bunch of models. Our system fuses six different sub-models into one single computational graph, which are categorized into three families. More specifically, the most effective family is the model with non-local operations following the NetVLAD encoding. The other two family models are Soft-BoF and GRU, respectively. In order to further boost single models performance, the model parameters of different checkpoints are averaged. Experimental results demonstrate that our proposed system can effectively perform the video classification task, achieving 0.88763 on the public test set and 0.88704 on the private set in terms of GAP@20, respectively. We finally ranked at the fourth place in the YouTube-8M video understanding challenge.