 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext-Based Semantic-Aware Alignment for Semi-Supervised Multi-Label Learning
Dec 25, 2024



Due to the lack of extensive precisely-annotated multi-label data in real word, semi-supervised multi-label learning (SSMLL) has gradually gained attention. Abundant knowledge embedded in vision-language models (VLMs) pre-trained on large-scale image-text pairs could alleviate the challenge of limited labeled data under SSMLL setting.Despite existing methods based on fine-tuning VLMs have achieved advances in weakly-supervised multi-label learning, they failed to fully leverage the information from labeled data to enhance the learning of unlabeled data. In this paper, we propose a context-based semantic-aware alignment method to solve the SSMLL problem by leveraging the knowledge of VLMs. To address the challenge of handling multiple semantics within an image, we introduce a novel framework design to extract label-specific image features. This design allows us to achieve a more compact alignment between text features and label-specific image features, leading the model to generate high-quality pseudo-labels. To incorporate the model with comprehensive understanding of image, we design a semi-supervised context identification auxiliary task to enhance the feature representation by capturing co-occurrence information. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our proposed method.
Dual-Decoupling Learning and Metric-Adaptive Thresholding for Semi-Supervised Multi-Label Learning
Jul 26, 2024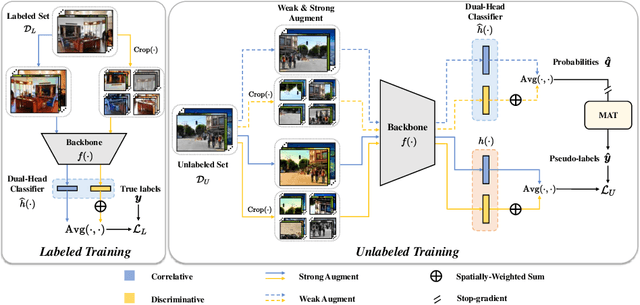
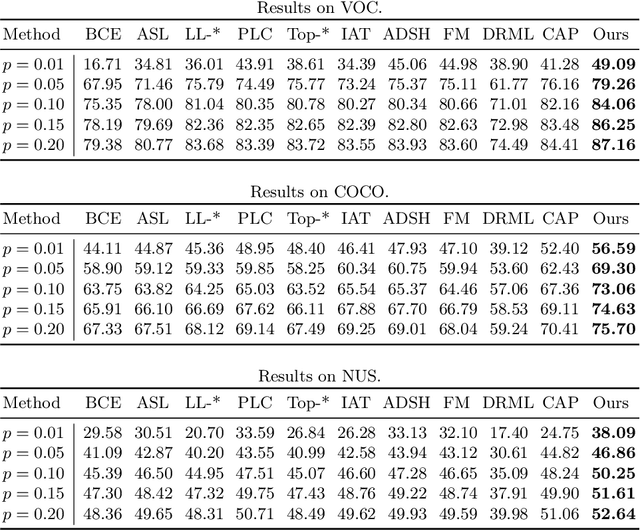
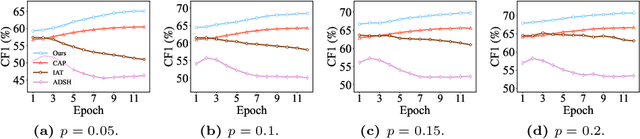
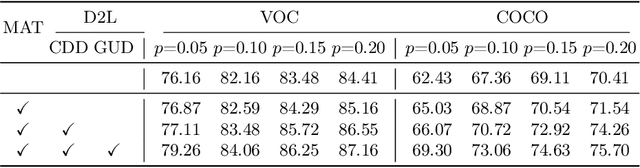
Semi-supervised multi-label learning (SSMLL) is a powerful framework for leveraging unlabeled data to reduce the expensive cost of collecting precise multi-label annotations. Unlike semi-supervised learning, one cannot select the most probable label as the pseudo-label in SSMLL due to multiple semantics contained in an instance. To solve this problem, the mainstream method developed an effective thresholding strategy to generate accurate pseudo-labels. Unfortunately, the method neglected the quality of model predictions and its potential impact on pseudo-labeling performance. In this paper, we propose a dual-perspective method to generate high-quality pseudo-labels. To improve the quality of model predictions, we perform dual-decoupling to boost the learning of correlative and discriminative features, while refining the generation and utilization of pseudo-labels. To obtain proper class-wise thresholds, we propose the metric-adaptive thresholding strategy to estimate the thresholds, which maximize the pseudo-label performance for a given metric on labeled data. Experiments on multiple benchmark datasets show the proposed method can achieve the state-of-the-art performance and outperform the comparative methods with a significant margin.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.