 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Multimodal Large Language Models Good Annotators for Image Tagging?
Feb 24, 2026Image tagging, a fundamental vision task, traditionally relies on human-annotated datasets to train multi-label classifiers, which incurs significant labor and costs. While Multimodal Large Language Models (MLLMs) offer promising potential to automate annotation, their capability to replace human annotators remains underexplored. This paper aims to analyze the gap between MLLM-generated and human annotations and to propose an effective solution that enables MLLM-based annotation to replace manual labeling. Our analysis of MLLM annotations reveals that, under a conservative estimate, MLLMs can reduce annotation cost to as low as one-thousandth of the human cost, mainly accounting for GPU usage, which is nearly negligible compared to manual efforts. Their annotation quality reaches about 50\% to 80\% of human performance, while achieving over 90\% performance on downstream training tasks.Motivated by these findings, we propose TagLLM, a novel framework for image tagging, which aims to narrow the gap between MLLM-generated and human annotations. TagLLM comprises two components: Candidates generation, which employs structured group-wise prompting to efficiently produce a compact candidate set that covers as many true labels as possible while reducing subsequent annotation workload; and label disambiguation, which interactively calibrates the semantic concept of categories in the prompts and effectively refines the candidate labels. Extensive experiments show that TagLLM substantially narrows the gap between MLLM-generated and human annotations, especially in downstream training performance, where it closes about 60\% to 80\% of the difference.
Context-Based Semantic-Aware Alignment for Semi-Supervised Multi-Label Learning
Dec 25, 2024



Due to the lack of extensive precisely-annotated multi-label data in real word, semi-supervised multi-label learning (SSMLL) has gradually gained attention. Abundant knowledge embedded in vision-language models (VLMs) pre-trained on large-scale image-text pairs could alleviate the challenge of limited labeled data under SSMLL setting.Despite existing methods based on fine-tuning VLMs have achieved advances in weakly-supervised multi-label learning, they failed to fully leverage the information from labeled data to enhance the learning of unlabeled data. In this paper, we propose a context-based semantic-aware alignment method to solve the SSMLL problem by leveraging the knowledge of VLMs. To address the challenge of handling multiple semantics within an image, we introduce a novel framework design to extract label-specific image features. This design allows us to achieve a more compact alignment between text features and label-specific image features, leading the model to generate high-quality pseudo-labels. To incorporate the model with comprehensive understanding of image, we design a semi-supervised context identification auxiliary task to enhance the feature representation by capturing co-occurrence information. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our proposed method.
Dual-Decoupling Learning and Metric-Adaptive Thresholding for Semi-Supervised Multi-Label Learning
Jul 26, 2024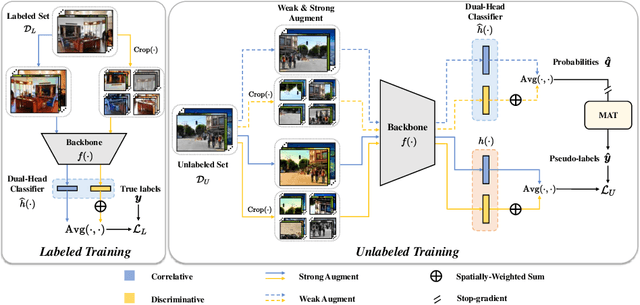
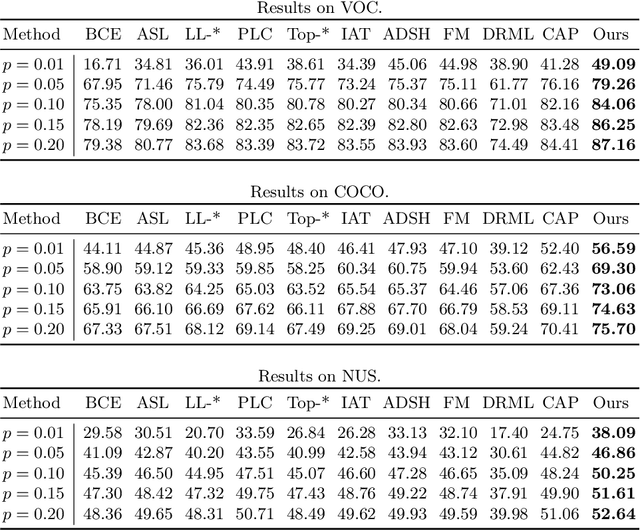
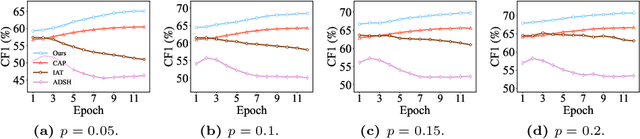
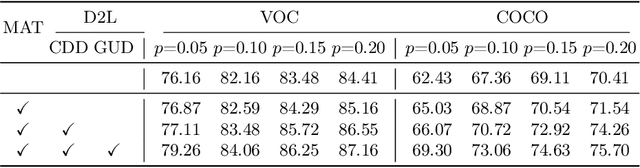
Semi-supervised multi-label learning (SSMLL) is a powerful framework for leveraging unlabeled data to reduce the expensive cost of collecting precise multi-label annotations. Unlike semi-supervised learning, one cannot select the most probable label as the pseudo-label in SSMLL due to multiple semantics contained in an instance. To solve this problem, the mainstream method developed an effective thresholding strategy to generate accurate pseudo-labels. Unfortunately, the method neglected the quality of model predictions and its potential impact on pseudo-labeling performance. In this paper, we propose a dual-perspective method to generate high-quality pseudo-labels. To improve the quality of model predictions, we perform dual-decoupling to boost the learning of correlative and discriminative features, while refining the generation and utilization of pseudo-labels. To obtain proper class-wise thresholds, we propose the metric-adaptive thresholding strategy to estimate the thresholds, which maximize the pseudo-label performance for a given metric on labeled data. Experiments on multiple benchmark datasets show the proposed method can achieve the state-of-the-art performance and outperform the comparative methods with a significant margin.
Counterfactual Reasoning for Multi-Label Image Classification via Patching-Based Training
Apr 09, 2024



The key to multi-label image classification (MLC) is to improve model performance by leveraging label correlations. Unfortunately, it has been shown that overemphasizing co-occurrence relationships can cause the overfitting issue of the model, ultimately leading to performance degradation. In this paper, we provide a causal inference framework to show that the correlative features caused by the target object and its co-occurring objects can be regarded as a mediator, which has both positive and negative impacts on model predictions. On the positive side, the mediator enhances the recognition performance of the model by capturing co-occurrence relationships; on the negative side, it has the harmful causal effect that causes the model to make an incorrect prediction for the target object, even when only co-occurring objects are present in an image. To address this problem, we propose a counterfactual reasoning method to measure the total direct effect, achieved by enhancing the direct effect caused only by the target object. Due to the unknown location of the target object, we propose patching-based training and inference to accomplish this goal, which divides an image into multiple patches and identifies the pivot patch that contains the target object. Experimental results on multiple benchmark datasets with diverse configurations validate that the proposed method can achieve state-of-the-art performance.
Empowering Language Models with Active Inquiry for Deeper Understanding
Feb 06, 2024The rise of large language models (LLMs) has revolutionized the way that we interact with artificial intelligence systems through natural language. However, LLMs often misinterpret user queries because of their uncertain intention, leading to less helpful responses. In natural human interactions, clarification is sought through targeted questioning to uncover obscure information. Thus, in this paper, we introduce LaMAI (Language Model with Active Inquiry), designed to endow LLMs with this same level of interactive engagement. LaMAI leverages active learning techniques to raise the most informative questions, fostering a dynamic bidirectional dialogue. This approach not only narrows the contextual gap but also refines the output of the LLMs, aligning it more closely with user expectations. Our empirical studies, across a variety of complex datasets where LLMs have limited conversational context, demonstrate the effectiveness of LaMAI. The method improves answer accuracy from 31.9% to 50.9%, outperforming other leading question-answering frameworks. Moreover, in scenarios involving human participants, LaMAI consistently generates responses that are superior or comparable to baseline methods in more than 82% of the cases. The applicability of LaMAI is further evidenced by its successful integration with various LLMs, highlighting its potential for the future of interactive language models.
Class-Distribution-Aware Pseudo Labeling for Semi-Supervised Multi-Label Learning
May 04, 2023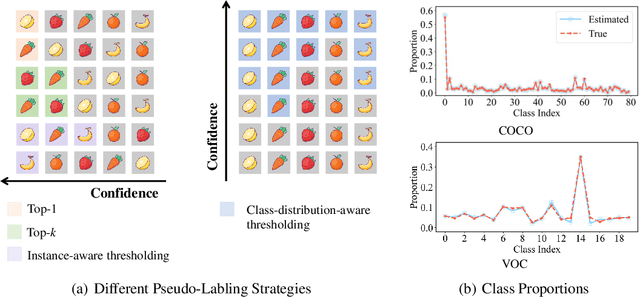
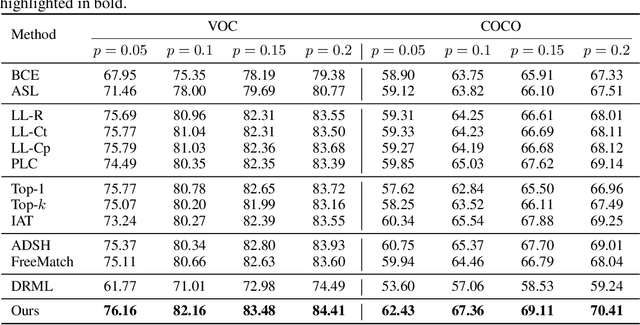

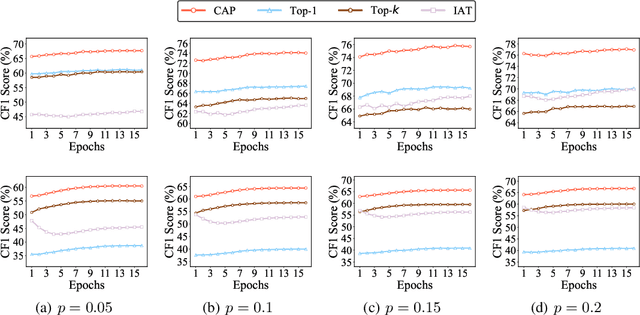
Pseudo labeling is a popular and effective method to leverage the information of unlabeled data. Conventional instance-aware pseudo labeling methods often assign each unlabeled instance with a pseudo label based on its predicted probabilities. However, due to the unknown number of true labels, these methods cannot generalize well to semi-supervised multi-label learning (SSMLL) scenarios, since they would suffer from the risk of either introducing false positive labels or neglecting true positive ones. In this paper, we propose to solve the SSMLL problems by performing Class-distribution-Aware Pseudo labeling (CAP), which encourages the class distribution of pseudo labels to approximate the true one. Specifically, we design a regularized learning framework consisting of the class-aware thresholds to control the number of pseudo labels for each class. Given that the labeled and unlabeled examples are sampled according to the same distribution, we determine the thresholds by exploiting the empirical class distribution, which can be treated as a tight approximation to the true one. Theoretically, we show that the generalization performance of the proposed method is dependent on the pseudo labeling error, which can be significantly reduced by the CAP strategy. Extensive experimental results on multiple benchmark datasets validate that CAP can effectively solve the SSMLL problems.