 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning World Models with Identifiable Factorization
Jun 27, 2023



Extracting a stable and compact representation of the environment is crucial for efficient reinforcement learning in high-dimensional, noisy, and non-stationary environments. Different categories of information coexist in such environments -- how to effectively extract and disentangle these information remains a challenging problem. In this paper, we propose IFactor, a general framework to model four distinct categories of latent state variables that capture various aspects of information within the RL system, based on their interactions with actions and rewards. Our analysis establishes block-wise identifiability of these latent variables, which not only provides a stable and compact representation but also discloses that all reward-relevant factors are significant for policy learning. We further present a practical approach to learning the world model with identifiable blocks, ensuring the removal of redundants but retaining minimal and sufficient information for policy optimization. Experiments in synthetic worlds demonstrate that our method accurately identifies the ground-truth latent variables, substantiating our theoretical findings. Moreover, experiments in variants of the DeepMind Control Suite and RoboDesk showcase the superior performance of our approach over baselines.
Sparsity Prior Regularized Q-learning for Sparse Action Tasks
May 19, 2021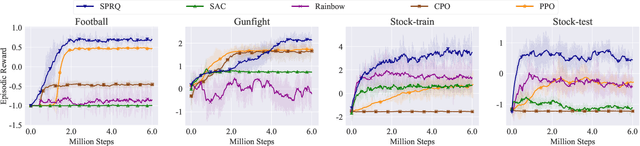

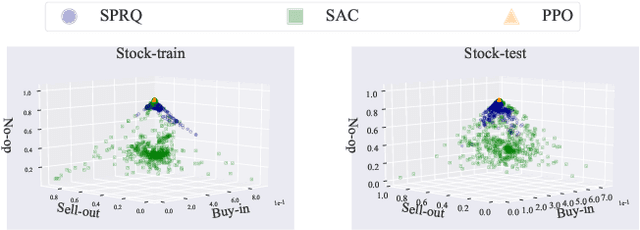
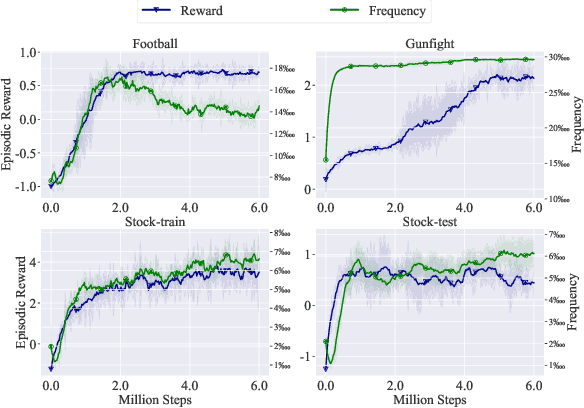
In many decision-making tasks, some specific actions are limited in their frequency or total amounts, such as "fire" in the gunfight game and "buy/sell" in the stock trading. We name such actions as "sparse action". Sparse action often plays a crucial role in achieving good performance. However, their Q-values, estimated by \emph{classical Bellman update}, usually suffer from a large estimation error due to the sparsity of their samples. The \emph{greedy} policy could be greatly misled by the biased Q-function and takes sparse action aggressively, which leads to a huge sub-optimality. This paper constructs a reference distribution that assigns a low probability to sparse action and proposes a regularized objective with an explicit constraint to the reference distribution. Furthermore, we derive a regularized Bellman operator and a regularized optimal policy that can slow down the propagation of error and guide the agent to take sparse action more carefully. The experiment results demonstrate that our method achieves state-of-the-art performance on typical sparse action tasks.
ZOOpt: Toolbox for Derivative-Free Optimization
Feb 06, 2018
Recent advances of derivative-free optimization allow efficient approximating the global optimal solutions of sophisticated functions, such as functions with many local optima, non-differentiable and non-continuous functions. This article describes the ZOOpt (https://github.com/eyounx/ZOOpt) toolbox that provides efficient derivative-free solvers and are designed easy to use. ZOOpt provides a Python package for single-thread optimization, and a light-weighted distributed version with the help of the Julia language for Python described functions. ZOOpt toolbox particularly focuses on optimization problems in machine learning, addressing high-dimensional, noisy, and large-scale problems. The toolbox is being maintained toward ready-to-use tool in real-world machine learning tasks.