 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Mediating Effects of Emotions on Trust through Risk Perception and System Performance in Automated Driving
Apr 06, 2025Trust in automated vehicles (AVs) has traditionally been explored through a cognitive lens, but growing evidence highlights the significant role emotions play in shaping trust. This study investigates how risk perception and AV performance (error vs. no error) influence emotional responses and trust in AVs, using mediation analysis to examine the indirect effects of emotions. In this study, 70 participants (42 male, 28 female) watched real-life recorded videos of AVs operating with or without errors, coupled with varying levels of risk information (high, low, or none). They reported their anticipated emotional responses using 19 discrete emotion items, and trust was assessed through dispositional, learned, and situational trust measures. Factor analysis identified four key emotional components, namely hostility, confidence, anxiety, and loneliness, that were influenced by risk perception and AV performance. The linear mixed model showed that risk perception was not a significant predictor of trust, while performance and individual differences were. Mediation analysis revealed that confidence was a strong positive mediator, while hostile and anxious emotions negatively impacted trust. However, lonely emotions did not significantly mediate the relationship between AV performance and trust. The results show that real-time AV behavior is more influential on trust than pre-existing risk perceptions, indicating trust in AVs might be more experience-based than shaped by prior beliefs. Our findings also underscore the importance of fostering positive emotional responses for trust calibration, which has important implications for user experience design in automated driving.
Learning Implicit Social Navigation Behavior using Deep Inverse Reinforcement Learning
Jan 12, 2025This paper reports on learning a reward map for social navigation in dynamic environments where the robot can reason about its path at any time, given agents' trajectories and scene geometry. Humans navigating in dense and dynamic indoor environments often work with several implied social rules. A rule-based approach fails to model all possible interactions between humans, robots, and scenes. We propose a novel Smooth Maximum Entropy Deep Inverse Reinforcement Learning (S-MEDIRL) algorithm that can extrapolate beyond expert demos to better encode scene navigability from few-shot demonstrations. The agent learns to predict the cost maps reasoning on trajectory data and scene geometry. The agent samples a trajectory that is then executed using a local crowd navigation controller. We present results in a photo-realistic simulation environment, with a robot and a human navigating a narrow crossing scenario. The robot implicitly learns to exhibit social behaviors such as yielding to oncoming traffic and avoiding deadlocks. We compare the proposed approach to the popular model-based crowd navigation algorithm ORCA and a rule-based agent that exhibits yielding.
Value Alignment and Trust in Human-Robot Interaction: Insights from Simulation and User Study
May 28, 2024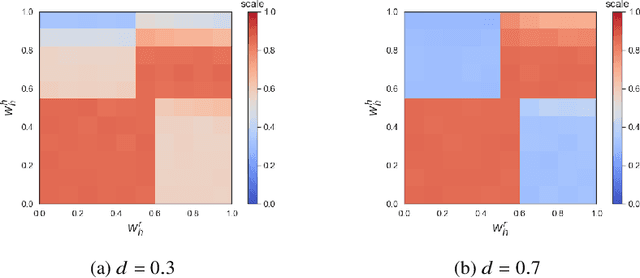
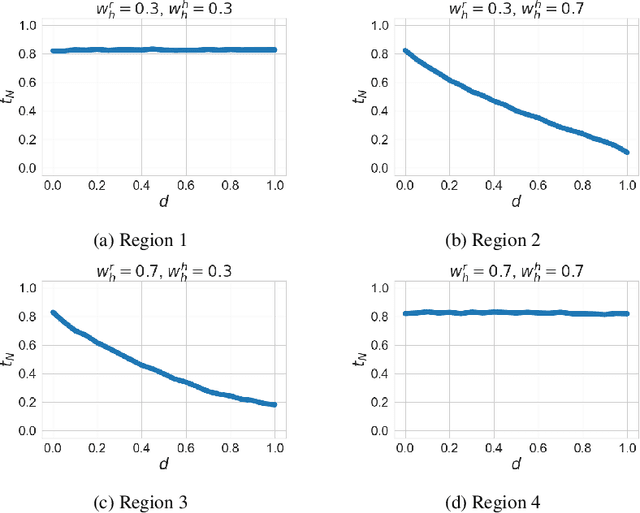
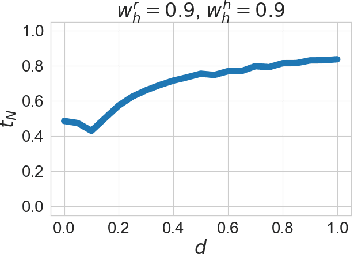
With the advent of AI technologies, humans and robots are increasingly teaming up to perform collaborative tasks. To enable smooth and effective collaboration, the topic of value alignment (operationalized herein as the degree of dynamic goal alignment within a task) between the robot and the human is gaining increasing research attention. Prior literature on value alignment makes an inherent assumption that aligning the values of the robot with that of the human benefits the team. This assumption, however, has not been empirically verified. Moreover, prior literature does not account for human's trust in the robot when analyzing human-robot value alignment. Thus, a research gap needs to be bridged by answering two questions: How does alignment of values affect trust? Is it always beneficial to align the robot's values with that of the human? We present a simulation study and a human-subject study to answer these questions. Results from the simulation study show that alignment of values is important for trust when the overall risk level of the task is high. We also present an adaptive strategy for the robot that uses Inverse Reinforcement Learning (IRL) to match the values of the robot with those of the human during interaction. Our simulations suggest that such an adaptive strategy is able to maintain trust across the full spectrum of human values. We also present results from an empirical study that validate these findings from simulation. Results indicate that real-time personalized value alignment is beneficial to trust and perceived performance by the human when the robot does not have a good prior on the human's values.
Evaluating the Impact of Personalized Value Alignment in Human-Robot Interaction: Insights into Trust and Team Performance Outcomes
Nov 27, 2023



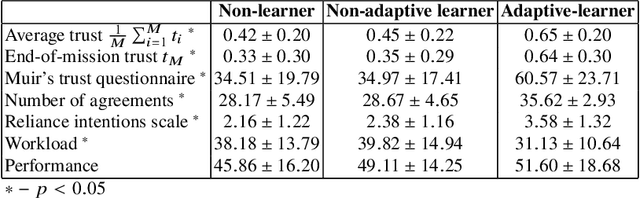
This paper examines the effect of real-time, personalized alignment of a robot's reward function to the human's values on trust and team performance. We present and compare three distinct robot interaction strategies: a non-learner strategy where the robot presumes the human's reward function mirrors its own, a non-adaptive-learner strategy in which the robot learns the human's reward function for trust estimation and human behavior modeling, but still optimizes its own reward function, and an adaptive-learner strategy in which the robot learns the human's reward function and adopts it as its own. Two human-subject experiments with a total number of 54 participants were conducted. In both experiments, the human-robot team searches for potential threats in a town. The team sequentially goes through search sites to look for threats. We model the interaction between the human and the robot as a trust-aware Markov Decision Process (trust-aware MDP) and use Bayesian Inverse Reinforcement Learning (IRL) to estimate the reward weights of the human as they interact with the robot. In Experiment 1, we start our learning algorithm with an informed prior of the human's values/goals. In Experiment 2, we start the learning algorithm with an uninformed prior. Results indicate that when starting with a good informed prior, personalized value alignment does not seem to benefit trust or team performance. On the other hand, when an informed prior is unavailable, alignment to the human's values leads to high trust and higher perceived performance while maintaining the same objective team performance.
Human-robot Matching and Routing for Multi-robot Tour Guiding under Time Uncertainty
Sep 27, 2023



This work presents a framework for multi-robot tour guidance in a partially known environment with uncertainty, such as a museum. A simultaneous matching and routing problem (SMRP) is formulated to match the humans with robot guides according to their requested places of interest (POIs) and generate the routes for the robots according to uncertain time estimation. A large neighborhood search algorithm is developed to efficiently find sub-optimal low-cost solutions for the SMRP. The scalability and optimality of the multi-robot planner are evaluated computationally. The largest case tested involves 50 robots, 250 humans, and 50 POIs. A photo-realistic multi-robot simulation was developed to verify the tour guiding performance in an uncertain indoor environment.
May I Ask a Follow-up Question? Understanding the Benefits of Conversations in Neural Network Explainability
Sep 25, 2023Research in explainable AI (XAI) aims to provide insights into the decision-making process of opaque AI models. To date, most XAI methods offer one-off and static explanations, which cannot cater to the diverse backgrounds and understanding levels of users. With this paper, we investigate if free-form conversations can enhance users' comprehension of static explanations, improve acceptance and trust in the explanation methods, and facilitate human-AI collaboration. Participants are presented with static explanations, followed by a conversation with a human expert regarding the explanations. We measure the effect of the conversation on participants' ability to choose, from three machine learning models, the most accurate one based on explanations and their self-reported comprehension, acceptance, and trust. Empirical results show that conversations significantly improve comprehension, acceptance, trust, and collaboration. Our findings highlight the importance of customized model explanations in the format of free-form conversations and provide insights for the future design of conversational explanations.
Effect of Adapting to Human Preferences on Trust in Human-Robot Teaming
Sep 11, 2023



We present the effect of adapting to human preferences on trust in a human-robot teaming task. The team performs a task in which the robot acts as an action recommender to the human. It is assumed that the behavior of the human and the robot is based on some reward function they try to optimize. We use a new human trust-behavior model that enables the robot to learn and adapt to the human's preferences in real-time during their interaction using Bayesian Inverse Reinforcement Learning. We present three strategies for the robot to interact with a human: a non-learner strategy, in which the robot assumes that the human's reward function is the same as the robot's, a non-adaptive learner strategy that learns the human's reward function for performance estimation, but still optimizes its own reward function, and an adaptive-learner strategy that learns the human's reward function for performance estimation and also optimizes this learned reward function. Results show that adapting to the human's reward function results in the highest trust in the robot.
Reward Shaping for Building Trustworthy Robots in Sequential Human-Robot Interaction
Aug 02, 2023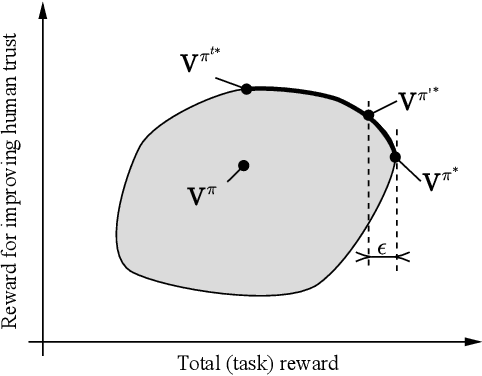
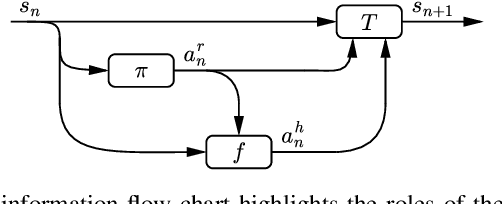
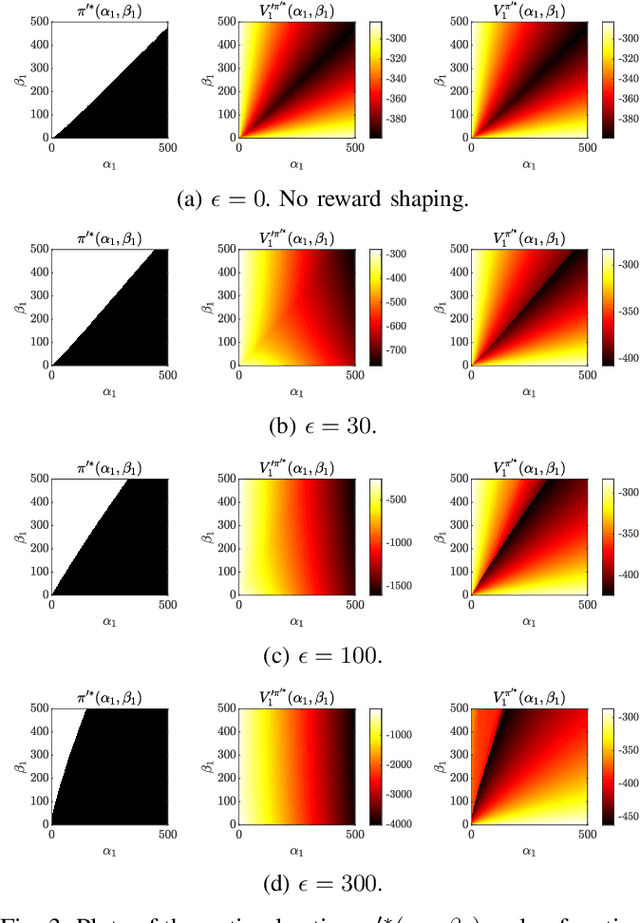
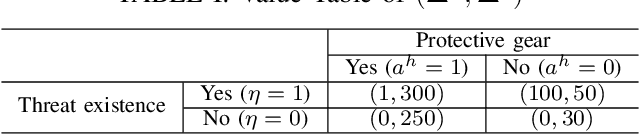
Trust-aware human-robot interaction (HRI) has received increasing research attention, as trust has been shown to be a crucial factor for effective HRI. Research in trust-aware HRI discovered a dilemma -- maximizing task rewards often leads to decreased human trust, while maximizing human trust would compromise task performance. In this work, we address this dilemma by formulating the HRI process as a two-player Markov game and utilizing the reward-shaping technique to improve human trust while limiting performance loss. Specifically, we show that when the shaping reward is potential-based, the performance loss can be bounded by the potential functions evaluated at the final states of the Markov game. We apply the proposed framework to the experience-based trust model, resulting in a linear program that can be efficiently solved and deployed in real-world applications. We evaluate the proposed framework in a simulation scenario where a human-robot team performs a search-and-rescue mission. The results demonstrate that the proposed framework successfully modifies the robot's optimal policy, enabling it to increase human trust at a minimal task performance cost.
Building Trust Profiles in Conditionally Automated Driving
Jun 28, 2023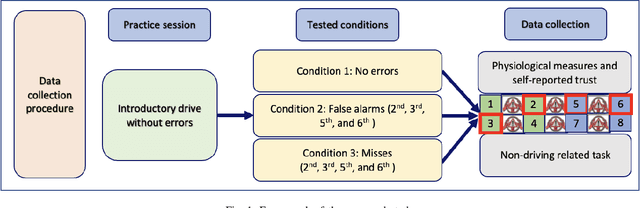
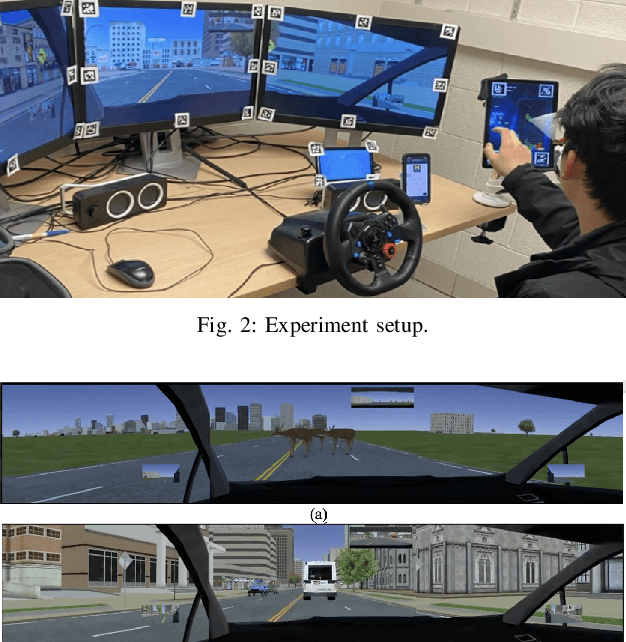
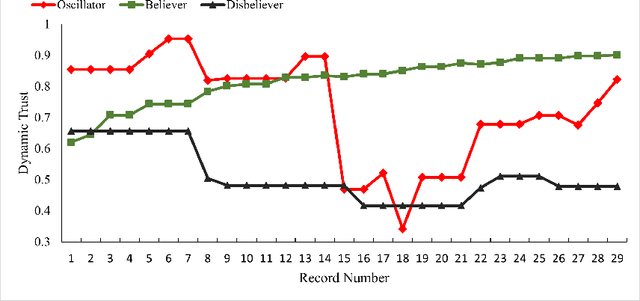
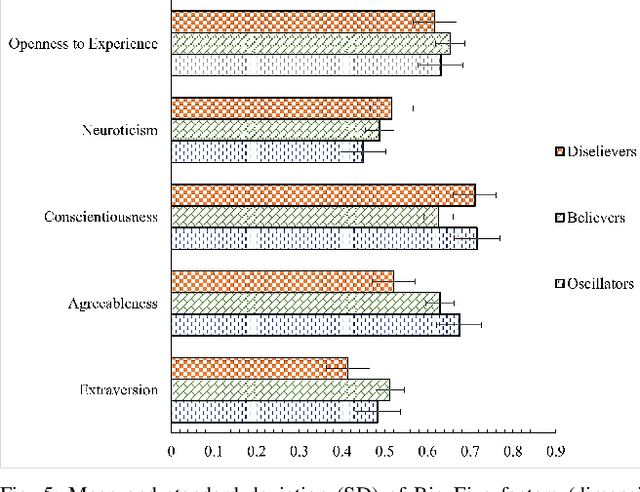
Trust is crucial for ensuring the safety, security, and widespread adoption of automated vehicles (AVs), and if trust is lacking, drivers and the public may not be willing to use them. This research seeks to investigate trust profiles in order to create personalized experiences for drivers in AVs. This technique helps in better understanding drivers' dynamic trust from a persona's perspective. The study was conducted in a driving simulator where participants were requested to take over control from automated driving in three conditions that included a control condition, a false alarm condition, and a miss condition with eight takeover requests (TORs) in different scenarios. Drivers' dispositional trust, initial learned trust, dynamic trust, personality, and emotions were measured. We identified three trust profiles (i.e., believers, oscillators, and disbelievers) using a K-means clustering model. In order to validate this model, we built a multinomial logistic regression model based on SHAP explainer that selected the most important features to predict the trust profiles with an F1-score of 0.90 and accuracy of 0.89. We also discussed how different individual factors influenced trust profiles which helped us understand trust dynamics better from a persona's perspective. Our findings have important implications for designing a personalized in-vehicle trust monitoring and calibrating system to adjust drivers' trust levels in order to improve safety and experience in automated driving.
Enabling Team of Teams: A Trust Inference and Propagation Model in Multi-Human Multi-Robot Teams
May 22, 2023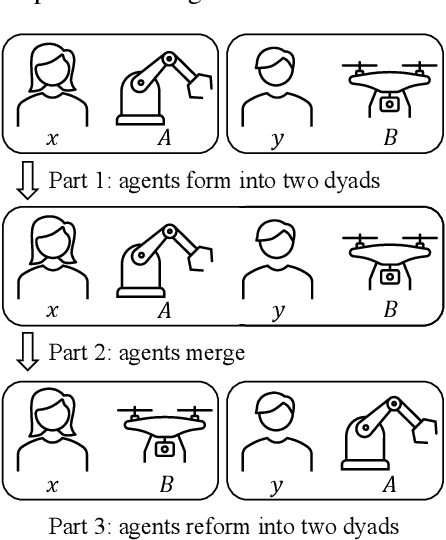
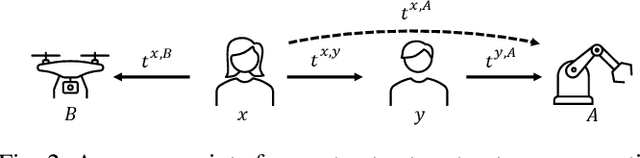
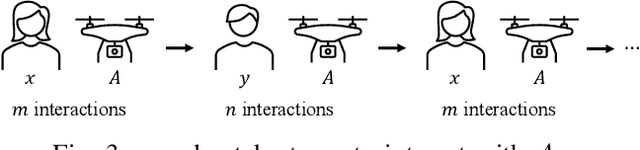
Trust has been identified as a central factor for effective human-robot teaming. Existing literature on trust modeling predominantly focuses on dyadic human-autonomy teams where one human agent interacts with one robot. There is little, if not no, research on trust modeling in teams consisting of multiple human agents and multiple robotic agents. To fill this research gap, we present the trust inference and propagation (TIP) model for trust modeling in multi-human multi-robot teams. In a multi-human multi-robot team, we postulate that there exist two types of experiences that a human agent has with a robot: direct and indirect experiences. The TIP model presents a novel mathematical framework that explicitly accounts for both types of experiences. To evaluate the model, we conducted a human-subject experiment with 15 pairs of participants (${N=30}$). Each pair performed a search and detection task with two drones. Results show that our TIP model successfully captured the underlying trust dynamics and significantly outperformed a baseline model. To the best of our knowledge, the TIP model is the first mathematical framework for computational trust modeling in multi-human multi-robot teams.