 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for Building Trustworthy Robots in Sequential Human-Robot Interaction
Paper and Code
Aug 02, 2023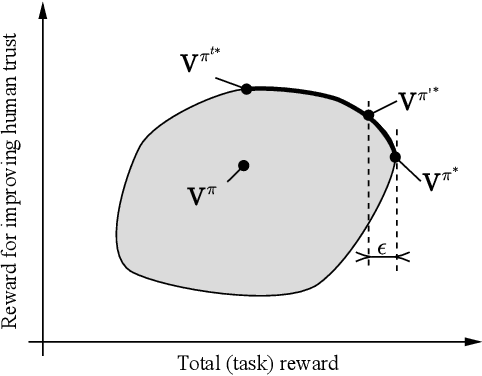
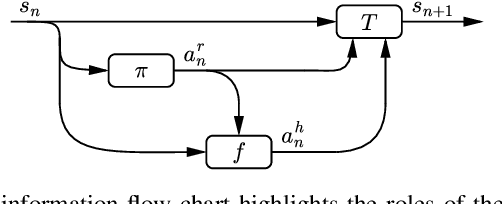
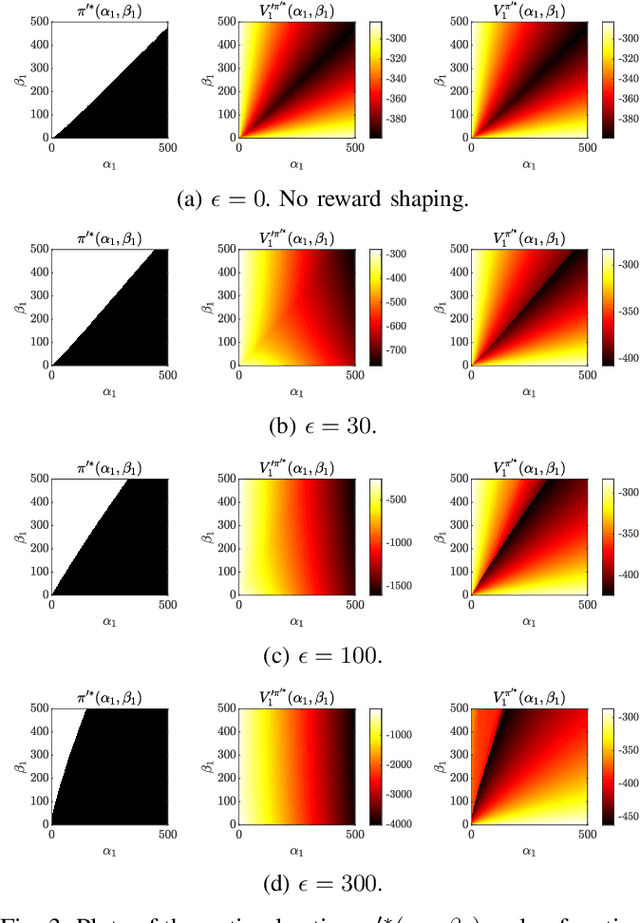
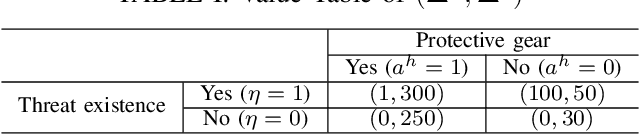
Trust-aware human-robot interaction (HRI) has received increasing research attention, as trust has been shown to be a crucial factor for effective HRI. Research in trust-aware HRI discovered a dilemma -- maximizing task rewards often leads to decreased human trust, while maximizing human trust would compromise task performance. In this work, we address this dilemma by formulating the HRI process as a two-player Markov game and utilizing the reward-shaping technique to improve human trust while limiting performance loss. Specifically, we show that when the shaping reward is potential-based, the performance loss can be bounded by the potential functions evaluated at the final states of the Markov game. We apply the proposed framework to the experience-based trust model, resulting in a linear program that can be efficiently solved and deployed in real-world applications. We evaluate the proposed framework in a simulation scenario where a human-robot team performs a search-and-rescue mission. The results demonstrate that the proposed framework successfully modifies the robot's optimal policy, enabling it to increase human trust at a minimal task performance cost.