 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReward Shaping for Building Trustworthy Robots in Sequential Human-Robot Interaction
Aug 02, 2023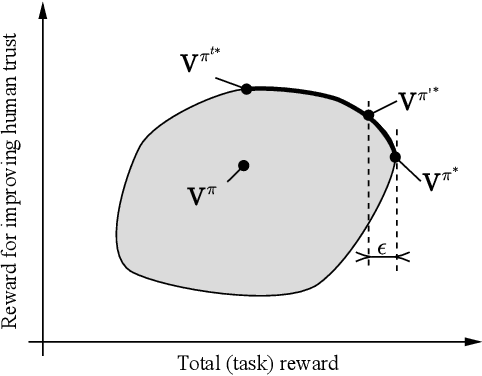
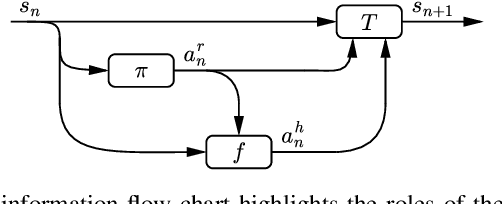
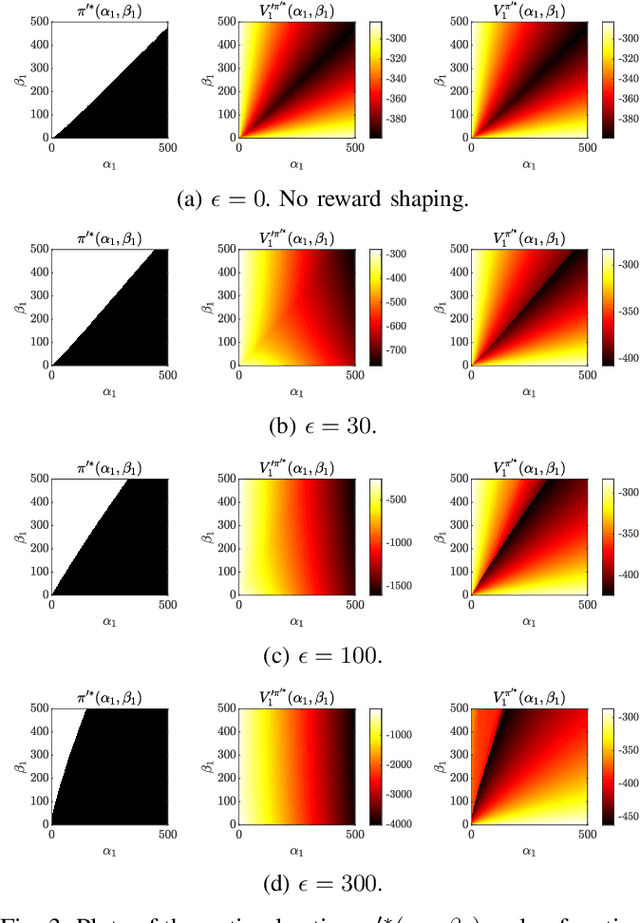
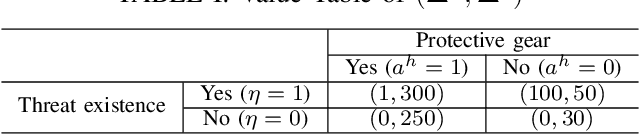
Trust-aware human-robot interaction (HRI) has received increasing research attention, as trust has been shown to be a crucial factor for effective HRI. Research in trust-aware HRI discovered a dilemma -- maximizing task rewards often leads to decreased human trust, while maximizing human trust would compromise task performance. In this work, we address this dilemma by formulating the HRI process as a two-player Markov game and utilizing the reward-shaping technique to improve human trust while limiting performance loss. Specifically, we show that when the shaping reward is potential-based, the performance loss can be bounded by the potential functions evaluated at the final states of the Markov game. We apply the proposed framework to the experience-based trust model, resulting in a linear program that can be efficiently solved and deployed in real-world applications. We evaluate the proposed framework in a simulation scenario where a human-robot team performs a search-and-rescue mission. The results demonstrate that the proposed framework successfully modifies the robot's optimal policy, enabling it to increase human trust at a minimal task performance cost.
Enabling Team of Teams: A Trust Inference and Propagation Model in Multi-Human Multi-Robot Teams
May 22, 2023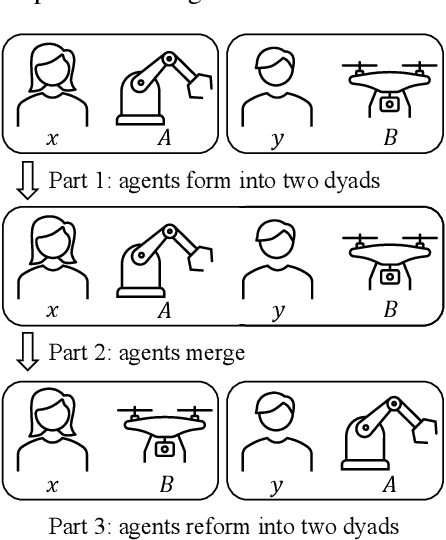
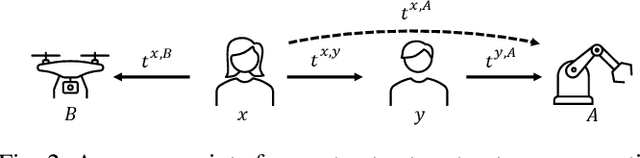
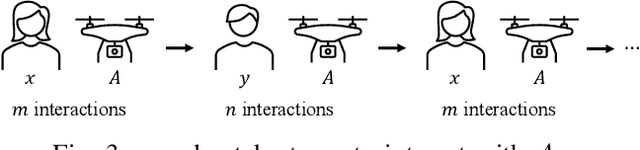
Trust has been identified as a central factor for effective human-robot teaming. Existing literature on trust modeling predominantly focuses on dyadic human-autonomy teams where one human agent interacts with one robot. There is little, if not no, research on trust modeling in teams consisting of multiple human agents and multiple robotic agents. To fill this research gap, we present the trust inference and propagation (TIP) model for trust modeling in multi-human multi-robot teams. In a multi-human multi-robot team, we postulate that there exist two types of experiences that a human agent has with a robot: direct and indirect experiences. The TIP model presents a novel mathematical framework that explicitly accounts for both types of experiences. To evaluate the model, we conducted a human-subject experiment with 15 pairs of participants (${N=30}$). Each pair performed a search and detection task with two drones. Results show that our TIP model successfully captured the underlying trust dynamics and significantly outperformed a baseline model. To the best of our knowledge, the TIP model is the first mathematical framework for computational trust modeling in multi-human multi-robot teams.
TIP: A Trust Inference and Propagation Model in Multi-Human Multi-Robot Teams
Jan 26, 2023



Trust has been identified as a central factor for effective human-robot teaming. Existing literature on trust modeling predominantly focuses on dyadic human-autonomy teams where one human agent interacts with one robot. There is little, if not no, research on trust modeling in teams consisting of multiple human agents and multiple robotic agents. To fill this research gap, we present the trust inference and propagation (TIP) model for trust modeling in multi-human multi-robot teams. We assert that in a multi-human multi-robot team, there exist two types of experiences that any human agent has with any robot: direct and indirect experiences. The TIP model presents a novel mathematical framework that explicitly accounts for both types of experiences. To evaluate the model, we conducted a human-subject experiment with 15 pairs of participants (N=30). Each pair performed a search and detection task with two drones. Results show that our TIP model successfully captured the underlying trust dynamics and significantly outperformed a baseline model. To the best of our knowledge, the TIP model is the first mathematical framework for computational trust modeling in multi-human multi-robot teams.
Reverse Psychology in Trust-Aware Human-Robot Interaction
Mar 18, 2021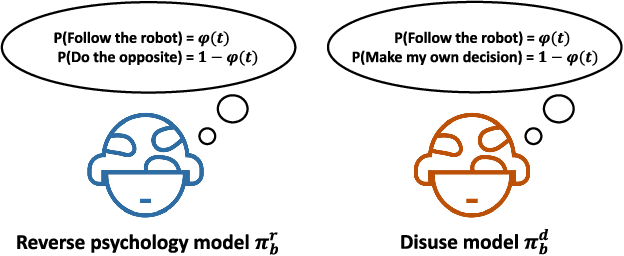



To facilitate effective human-robot interaction (HRI), trust-aware HRI has been proposed, wherein the robotic agent explicitly considers the human's trust during its planning and decision making. The success of trust-aware HRI depends on the specification of a trust dynamics model and a trust-behavior model. In this study, we proposed one novel trust-behavior model, namely the reverse psychology model, and compared it against the commonly used disuse model. We examined how the two models affect the robot's optimal policy and the human-robot team performance. Results indicate that the robot will deliberately "manipulate" the human's trust under the reverse psychology model. To correct this "manipulative" behavior, we proposed a trust-seeking reward function that facilitates trust establishment without significantly sacrificing the team performance.
Modeling and Predicting Trust Dynamics in Human-Robot Teaming: A Bayesian Inference Approach
Jul 26, 2020
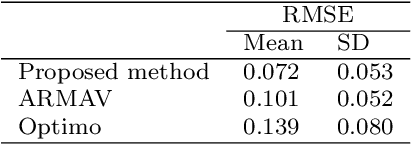

Trust in automation, or more recently trust in autonomy, has received extensive research attention in the past two decades. The majority of prior literature adopted a ``snapshot" view of trust and typically evaluated trust through questionnaires administered at the end of an experiment. This "snapshot" view, however, does not acknowledge that trust is a time-variant variable that can strengthen or decay over time. To fill the research gap, the present study aims to model trust dynamics when a human interacts with a robotic agent over time. The underlying premise of the study is that by interacting with a robotic agent and observing its performance over time, a rational human agent will update his/her trust in the robotic agent accordingly. Based on this premise, we develop a personalized trust prediction model based on Beta distribution and learn its parameters using Bayesian inference. Our proposed model adheres to three major properties of trust dynamics reported in prior empirical studies. We tested the proposed method using an existing dataset involving 39 human participants interacting with four drones in a simulated surveillance mission. The proposed method obtained a Root Mean Square Error (RMSE) of 0.072, significantly outperforming existing prediction methods. Moreover, we identified three distinctive types of trust dynamics, the Bayesian decision maker, the oscillator, and the disbeliever, respectively. This prediction model can be used for the design of individualized and adaptive technologies.
Modeling Multi-Vehicle Interaction Scenarios Using Gaussian Random Field
Jun 25, 2019



Autonomous vehicles (AV) are expected to navigate in complex traffic scenarios with multiple surrounding vehicles. The correlations between road users vary over time, the degree of which, in theory, could be infinitely large, and thus posing a great challenge in modeling and predicting the driving environment. In this research, we propose a method to reproduce such high-dimensional scenarios in a finitely tractable form by defining a stochastic vector field model in multi-vehicle interactions. We then apply non-parametric Bayesian learning to extract the underlying motion patterns from a large quantity of naturalistic traffic data. We use Gaussian process to model multi-vehicle motion, and Dirichlet process to assign each observation to a specific scenario. We implement the proposed method on NGSim highway and intersection data sets, in which complex multi-vehicle interactions are prevalent. The results show that the proposed method is capable of capturing motion patterns from both settings, without imposing heroic prior, hence can be applied for a wide array of traffic situations. The proposed modeling can enable simulation platforms and other testing methods designed for AV evaluation, to easily model and generate traffic scenarios emulating large scale driving data.
A Versatile Approach to Evaluating and Testing Automated Vehicles based on Kernel Methods
Oct 01, 2017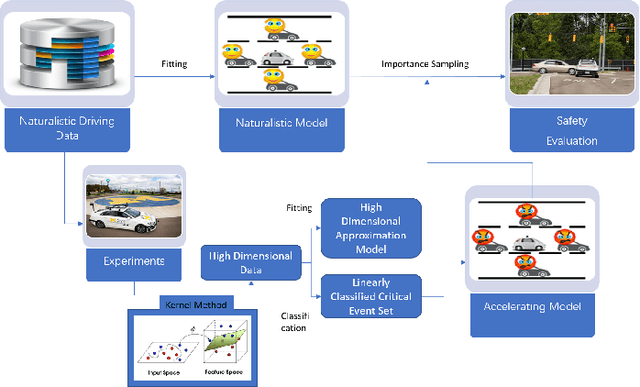
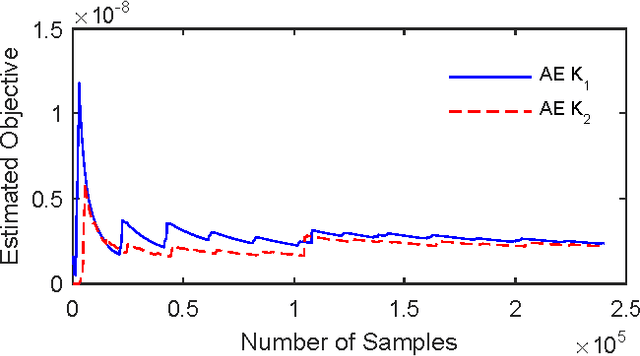


Evaluation and validation of complicated control systems are crucial to guarantee usability and safety. Usually, failure happens in some very rarely encountered situations, but once triggered, the consequence is disastrous. Accelerated Evaluation is a methodology that efficiently tests those rarely-occurring yet critical failures via smartly-sampled test cases. The distribution used in sampling is pivotal to the performance of the method, but building a suitable distribution requires case-by-case analysis. This paper proposes a versatile approach for constructing sampling distribution using kernel method. The approach uses statistical learning tools to approximate the critical event sets and constructs distributions based on the unique properties of Gaussian distributions. We applied the method to evaluate the automated vehicles. Numerical experiments show proposed approach can robustly identify the rare failures and significantly reduce the evaluation time.