 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Alignment and Trust in Human-Robot Interaction: Insights from Simulation and User Study
May 28, 2024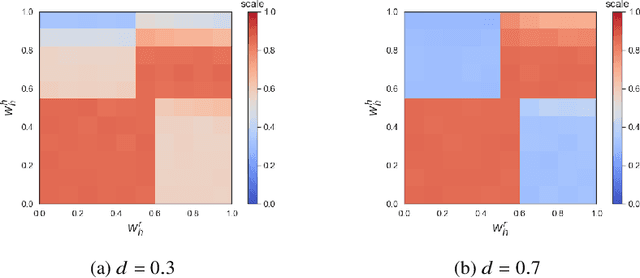
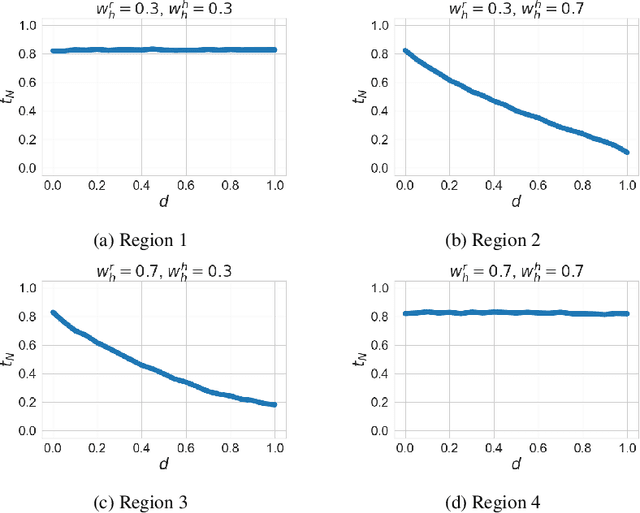
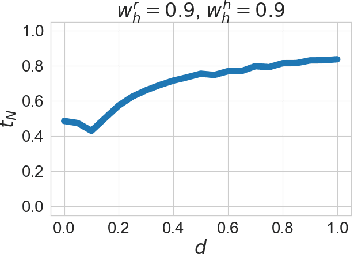
With the advent of AI technologies, humans and robots are increasingly teaming up to perform collaborative tasks. To enable smooth and effective collaboration, the topic of value alignment (operationalized herein as the degree of dynamic goal alignment within a task) between the robot and the human is gaining increasing research attention. Prior literature on value alignment makes an inherent assumption that aligning the values of the robot with that of the human benefits the team. This assumption, however, has not been empirically verified. Moreover, prior literature does not account for human's trust in the robot when analyzing human-robot value alignment. Thus, a research gap needs to be bridged by answering two questions: How does alignment of values affect trust? Is it always beneficial to align the robot's values with that of the human? We present a simulation study and a human-subject study to answer these questions. Results from the simulation study show that alignment of values is important for trust when the overall risk level of the task is high. We also present an adaptive strategy for the robot that uses Inverse Reinforcement Learning (IRL) to match the values of the robot with those of the human during interaction. Our simulations suggest that such an adaptive strategy is able to maintain trust across the full spectrum of human values. We also present results from an empirical study that validate these findings from simulation. Results indicate that real-time personalized value alignment is beneficial to trust and perceived performance by the human when the robot does not have a good prior on the human's values.
Evaluating the Impact of Personalized Value Alignment in Human-Robot Interaction: Insights into Trust and Team Performance Outcomes
Nov 27, 2023



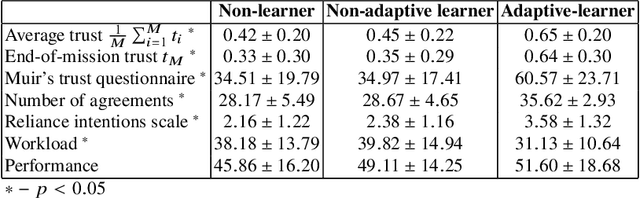
This paper examines the effect of real-time, personalized alignment of a robot's reward function to the human's values on trust and team performance. We present and compare three distinct robot interaction strategies: a non-learner strategy where the robot presumes the human's reward function mirrors its own, a non-adaptive-learner strategy in which the robot learns the human's reward function for trust estimation and human behavior modeling, but still optimizes its own reward function, and an adaptive-learner strategy in which the robot learns the human's reward function and adopts it as its own. Two human-subject experiments with a total number of 54 participants were conducted. In both experiments, the human-robot team searches for potential threats in a town. The team sequentially goes through search sites to look for threats. We model the interaction between the human and the robot as a trust-aware Markov Decision Process (trust-aware MDP) and use Bayesian Inverse Reinforcement Learning (IRL) to estimate the reward weights of the human as they interact with the robot. In Experiment 1, we start our learning algorithm with an informed prior of the human's values/goals. In Experiment 2, we start the learning algorithm with an uninformed prior. Results indicate that when starting with a good informed prior, personalized value alignment does not seem to benefit trust or team performance. On the other hand, when an informed prior is unavailable, alignment to the human's values leads to high trust and higher perceived performance while maintaining the same objective team performance.
Effect of Adapting to Human Preferences on Trust in Human-Robot Teaming
Sep 11, 2023



We present the effect of adapting to human preferences on trust in a human-robot teaming task. The team performs a task in which the robot acts as an action recommender to the human. It is assumed that the behavior of the human and the robot is based on some reward function they try to optimize. We use a new human trust-behavior model that enables the robot to learn and adapt to the human's preferences in real-time during their interaction using Bayesian Inverse Reinforcement Learning. We present three strategies for the robot to interact with a human: a non-learner strategy, in which the robot assumes that the human's reward function is the same as the robot's, a non-adaptive learner strategy that learns the human's reward function for performance estimation, but still optimizes its own reward function, and an adaptive-learner strategy that learns the human's reward function for performance estimation and also optimizes this learned reward function. Results show that adapting to the human's reward function results in the highest trust in the robot.
Clustering Trust Dynamics in a Human-Robot Sequential Decision-Making Task
Jun 03, 2022



In this paper, we present a framework for trust-aware sequential decision-making in a human-robot team. We model the problem as a finite-horizon Markov Decision Process with a reward-based performance metric, allowing the robotic agent to make trust-aware recommendations. Results of a human-subject experiment show that the proposed trust update model is able to accurately capture the human agent's moment-to-moment trust changes. Moreover, we cluster the participants' trust dynamics into three categories, namely, Bayesian decision makers, oscillators, and disbelievers, and identify personal characteristics that could be used to predict which type of trust dynamics a person will belong to. We find that the disbelievers are less extroverted, less agreeable, and have lower expectations toward the robotic agent, compared to the Bayesian decision makers and oscillators. The oscillators are significantly more frustrated than the Bayesian decision makers.