 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust inference for risk heterogeneity under group imbalance
May 30, 2026Population-level heterogeneity is ubiquitous in biomedical data, where differences across demographic or clinical subgroups can substantially alter risk patterns. For example, in intensive care unit (ICU) studies, the mortality risk associated with specific admission diagnoses can vary across ethnic groups. Existing approaches for detecting risk heterogeneity are often sensitive to baseline model misspecification and regularization bias, both of which commonly arise in practice. In this paper, we propose a robust framework for inferring risk heterogeneity between two populations using Neyman orthogonality, which yields estimators that are locally insensitive to nuisance parameter estimation error. The proposed estimator is consistent and asymptotically normal, and simulation studies demonstrate that in finite samples our method substantially reduces bias and improves inferential stability compared with standard likelihood-based approaches. In an application to the eICU Collaborative Research Database, our method reveals clinically meaningful ethnicity-specific heterogeneity in admission diagnoses for in-hospital mortality that standard likelihood-based methods fail to detect.
Limitations of refinement methods for weak to strong generalization
Aug 23, 2025



Standard techniques for aligning large language models (LLMs) utilize human-produced data, which could limit the capability of any aligned LLM to human level. Label refinement and weak training have emerged as promising strategies to address this superalignment problem. In this work, we adopt probabilistic assumptions commonly used to study label refinement and analyze whether refinement can be outperformed by alternative approaches, including computationally intractable oracle methods. We show that both weak training and label refinement suffer from irreducible error, leaving a performance gap between label refinement and the oracle. These results motivate future research into developing alternative methods for weak to strong generalization that synthesize the practicality of label refinement or weak training and the optimality of the oracle procedure.
CARROT: A Cost Aware Rate Optimal Router
Feb 05, 2025



With the rapid growth in the number of Large Language Models (LLMs), there has been a recent interest in LLM routing, or directing queries to the cheapest LLM that can deliver a suitable response. Following this line of work, we introduce CARROT, a Cost AwaRe Rate Optimal rouTer that can select models based on any desired trade-off between performance and cost. Given a query, CARROT selects a model based on estimates of models' cost and performance. Its simplicity lends CARROT computational efficiency, while our theoretical analysis demonstrates minimax rate-optimality in its routing performance. Alongside CARROT, we also introduce the Smart Price-aware Routing (SPROUT) dataset to facilitate routing on a wide spectrum of queries with the latest state-of-the-art LLMs. Using SPROUT and prior benchmarks such as Routerbench and open-LLM-leaderboard-v2 we empirically validate CARROT's performance against several alternative routers.
Microfoundation Inference for Strategic Prediction
Nov 13, 2024



Often in prediction tasks, the predictive model itself can influence the distribution of the target variable, a phenomenon termed performative prediction. Generally, this influence stems from strategic actions taken by stakeholders with a vested interest in predictive models. A key challenge that hinders the widespread adaptation of performative prediction in machine learning is that practitioners are generally unaware of the social impacts of their predictions. To address this gap, we propose a methodology for learning the distribution map that encapsulates the long-term impacts of predictive models on the population. Specifically, we model agents' responses as a cost-adjusted utility maximization problem and propose estimates for said cost. Our approach leverages optimal transport to align pre-model exposure (ex ante) and post-model exposure (ex post) distributions. We provide a rate of convergence for this proposed estimate and assess its quality through empirical demonstrations on a credit-scoring dataset.
Learning the Distribution Map in Reverse Causal Performative Prediction
May 24, 2024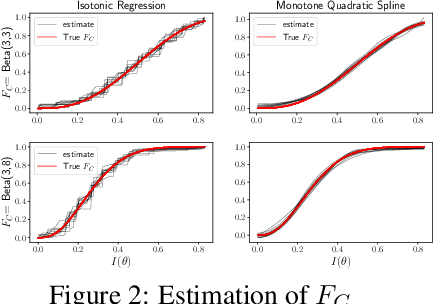
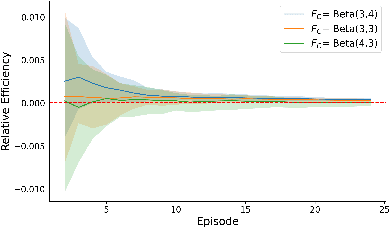
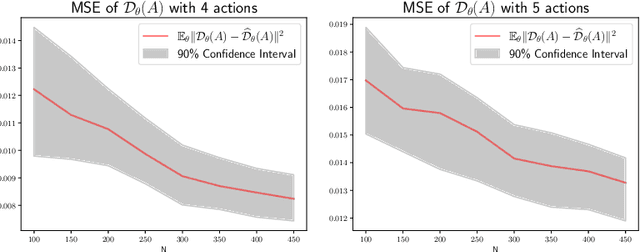
In numerous predictive scenarios, the predictive model affects the sampling distribution; for example, job applicants often meticulously craft their resumes to navigate through a screening systems. Such shifts in distribution are particularly prevalent in the realm of social computing, yet, the strategies to learn these shifts from data remain remarkably limited. Inspired by a microeconomic model that adeptly characterizes agents' behavior within labor markets, we introduce a novel approach to learn the distribution shift. Our method is predicated on a reverse causal model, wherein the predictive model instigates a distribution shift exclusively through a finite set of agents' actions. Within this framework, we employ a microfoundation model for the agents' actions and develop a statistically justified methodology to learn the distribution shift map, which we demonstrate to be effective in minimizing the performative prediction risk.
Aligners: Decoupling LLMs and Alignment
Mar 11, 2024

Large Language Models (LLMs) need to be aligned with human expectations to ensure their safety and utility in most applications. Alignment is challenging, costly, and needs to be repeated for every LLM and alignment criterion. We propose to decouple LLMs and alignment by training aligner models that can be used to align any LLM for a given criteria on an as-needed basis, thus also reducing the potential negative impacts of alignment on performance. Our recipe for training the aligner models solely relies on synthetic data generated with a (prompted) LLM and can be easily adjusted for a variety of alignment criteria. We illustrate our method by training an "ethical" aligner and verify its efficacy empirically.
Estimating Fréchet bounds for validating programmatic weak supervision
Dec 07, 2023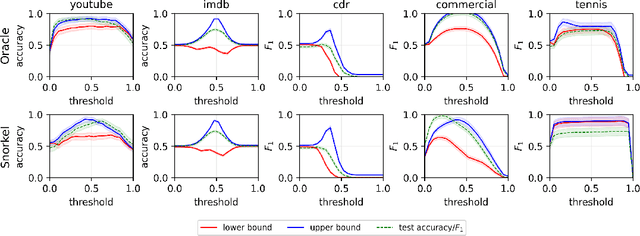

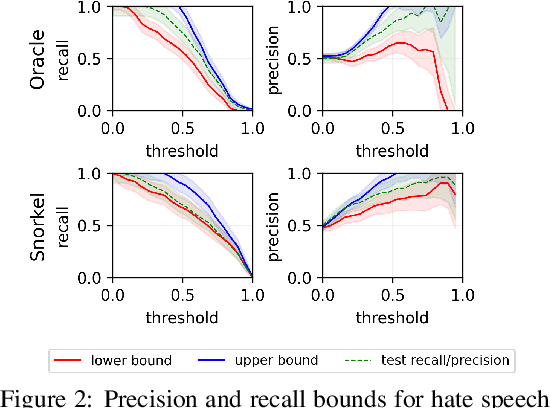

We develop methods for estimating Fr\'echet bounds on (possibly high-dimensional) distribution classes in which some variables are continuous-valued. We establish the statistical correctness of the computed bounds under uncertainty in the marginal constraints and demonstrate the usefulness of our algorithms by evaluating the performance of machine learning (ML) models trained with programmatic weak supervision (PWS). PWS is a framework for principled learning from weak supervision inputs (e.g., crowdsourced labels, knowledge bases, pre-trained models on related tasks, etc), and it has achieved remarkable success in many areas of science and engineering. Unfortunately, it is generally difficult to validate the performance of ML models trained with PWS due to the absence of labeled data. Our algorithms address this issue by estimating sharp lower and upper bounds for performance metrics such as accuracy/recall/precision/F1 score.
An Investigation of Representation and Allocation Harms in Contrastive Learning
Oct 02, 2023



The effect of underrepresentation on the performance of minority groups is known to be a serious problem in supervised learning settings; however, it has been underexplored so far in the context of self-supervised learning (SSL). In this paper, we demonstrate that contrastive learning (CL), a popular variant of SSL, tends to collapse representations of minority groups with certain majority groups. We refer to this phenomenon as representation harm and demonstrate it on image and text datasets using the corresponding popular CL methods. Furthermore, our causal mediation analysis of allocation harm on a downstream classification task reveals that representation harm is partly responsible for it, thus emphasizing the importance of studying and mitigating representation harm. Finally, we provide a theoretical explanation for representation harm using a stochastic block model that leads to a representational neural collapse in a contrastive learning setting.
Bayes classifier cannot be learned from noisy responses with unknown noise rates
Apr 13, 2023
Training a classifier with noisy labels typically requires the learner to specify the distribution of label noise, which is often unknown in practice. Although there have been some recent attempts to relax that requirement, we show that the Bayes decision rule is unidentified in most classification problems with noisy labels. This suggests it is generally not possible to bypass/relax the requirement. In the special cases in which the Bayes decision rule is identified, we develop a simple algorithm to learn the Bayes decision rule, that does not require knowledge of the noise distribution.
Simple Disentanglement of Style and Content in Visual Representations
Feb 20, 2023



Learning visual representations with interpretable features, i.e., disentangled representations, remains a challenging problem. Existing methods demonstrate some success but are hard to apply to large-scale vision datasets like ImageNet. In this work, we propose a simple post-processing framework to disentangle content and style in learned representations from pre-trained vision models. We model the pre-trained features probabilistically as linearly entangled combinations of the latent content and style factors and develop a simple disentanglement algorithm based on the probabilistic model. We show that the method provably disentangles content and style features and verify its efficacy empirically. Our post-processed features yield significant domain generalization performance improvements when the distribution shift occurs due to style changes or style-related spurious correlations.