 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding new tasks through the lens of training data via exponential tilting
Paper and Code
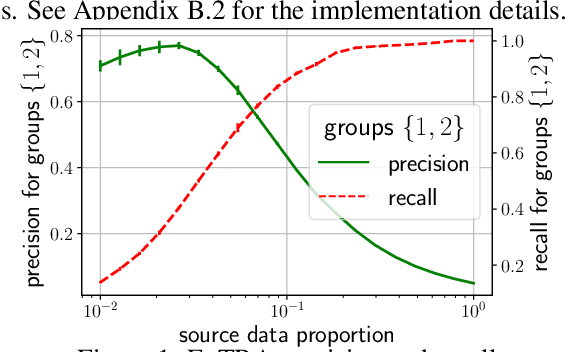
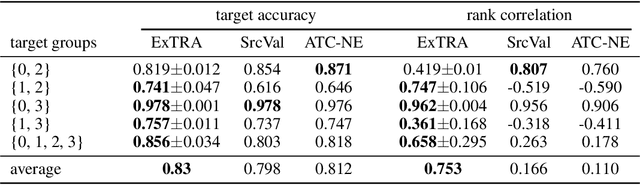
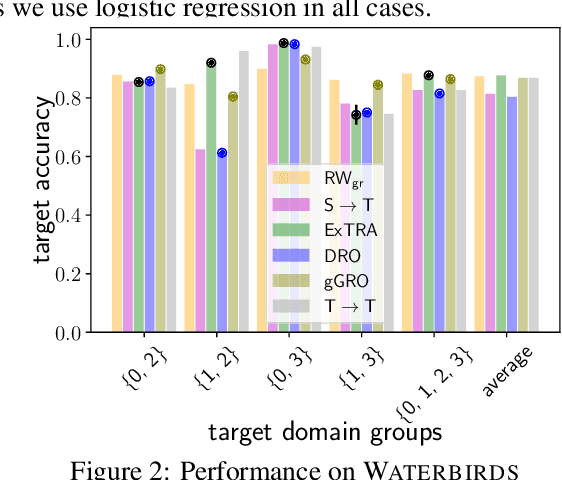
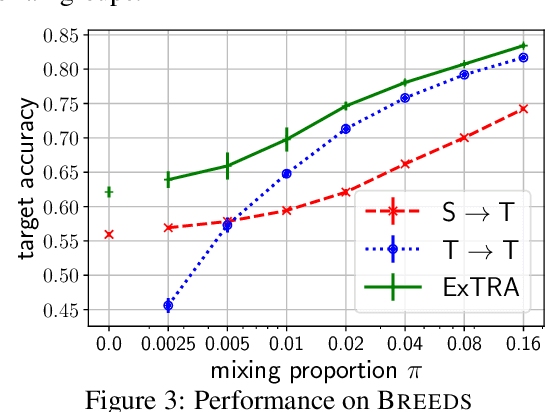
Deploying machine learning models to new tasks is a major challenge despite the large size of the modern training datasets. However, it is conceivable that the training data can be reweighted to be more representative of the new (target) task. We consider the problem of reweighing the training samples to gain insights into the distribution of the target task. Specifically, we formulate a distribution shift model based on the exponential tilt assumption and learn train data importance weights minimizing the KL divergence between labeled train and unlabeled target datasets. The learned train data weights can then be used for downstream tasks such as target performance evaluation, fine-tuning, and model selection. We demonstrate the efficacy of our method on Waterbirds and Breeds benchmarks.