 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIMP: Contrastive Language-Image Mamba Pretraining
Jan 11, 2026Contrastive Language-Image Pre-training (CLIP) relies on Vision Transformers whose attention mechanism is susceptible to spurious correlations, and scales quadratically with resolution. To address these limitations, We present CLIMP, the first fully Mamba-based contrastive vision-language model that replaces both the vision and text encoders with Mamba. The new architecture encodes sequential structure in both vision and language, with VMamba capturing visual spatial inductive biases, reducing reliance on spurious correlations and producing an embedding space favorable for cross-modal retrieval and out-of-distribution robustness-surpassing OpenAI's CLIP-ViT-B by 7.5% on ImageNet-O. CLIMP naturally supports variable input resolutions without positional encoding interpolation or specialized training, achieving up to 6.6% higher retrieval accuracy at 16x training resolution while using 5x less memory and 1.8x fewer FLOPs. The autoregressive text encoder further overcomes CLIP's fixed context limitation, enabling dense captioning retrieval. Our findings suggest that Mamba exhibits advantageous properties for vision-language learning, making it a compelling alternative to Transformer-based CLIP.
Spoken question answering for visual queries
May 29, 2025Question answering (QA) systems are designed to answer natural language questions. Visual QA (VQA) and Spoken QA (SQA) systems extend the textual QA system to accept visual and spoken input respectively. This work aims to create a system that enables user interaction through both speech and images. That is achieved through the fusion of text, speech, and image modalities to tackle the task of spoken VQA (SVQA). The resulting multi-modal model has textual, visual, and spoken inputs and can answer spoken questions on images. Training and evaluating SVQA models requires a dataset for all three modalities, but no such dataset currently exists. We address this problem by synthesizing VQA datasets using two zero-shot TTS models. Our initial findings indicate that a model trained only with synthesized speech nearly reaches the performance of the upper-bounding model trained on textual QAs. In addition, we show that the choice of the TTS model has a minor impact on accuracy.
Teaching VLMs to Localize Specific Objects from In-context Examples
Nov 20, 2024



Vision-Language Models (VLMs) have shown remarkable capabilities across diverse visual tasks, including image recognition, video understanding, and Visual Question Answering (VQA) when explicitly trained for these tasks. Despite these advances, we find that current VLMs lack a fundamental cognitive ability: learning to localize objects in a scene by taking into account the context. In this work, we focus on the task of few-shot personalized localization, where a model is given a small set of annotated images (in-context examples) -- each with a category label and bounding box -- and is tasked with localizing the same object type in a query image. To provoke personalized localization abilities in models, we present a data-centric solution that fine-tunes them using carefully curated data from video object tracking datasets. By leveraging sequences of frames tracking the same object across multiple shots, we simulate instruction-tuning dialogues that promote context awareness. To reinforce this, we introduce a novel regularization technique that replaces object labels with pseudo-names, ensuring the model relies on visual context rather than prior knowledge. Our method significantly enhances few-shot localization performance without sacrificing generalization, as demonstrated on several benchmarks tailored to personalized localization. This work is the first to explore and benchmark personalized few-shot localization for VLMs, laying a foundation for future research in context-driven vision-language applications. The code for our project is available at https://github.com/SivanDoveh/IPLoc
Continuous Speech Synthesis using per-token Latent Diffusion
Oct 21, 2024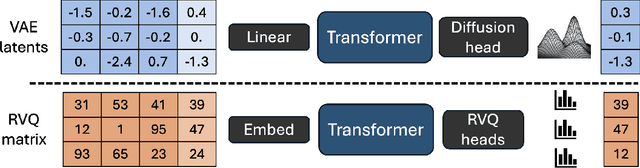
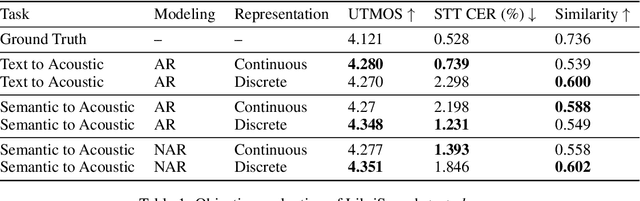
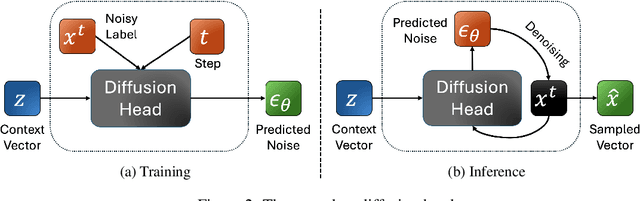

The success of autoregressive transformer models with discrete tokens has inspired quantization-based approaches for continuous modalities, though these often limit reconstruction quality. We therefore introduce SALAD, a per-token latent diffusion model for zero-shot text-to-speech, that operates on continuous representations. SALAD builds upon the recently proposed expressive diffusion head for image generation, and extends it to generate variable-length outputs. Our approach utilizes semantic tokens for providing contextual information and determining the stopping condition. We suggest three continuous variants for our method, extending popular discrete speech synthesis techniques. Additionally, we implement discrete baselines for each variant and conduct a comparative analysis of discrete versus continuous speech modeling techniques. Our results demonstrate that both continuous and discrete approaches are highly competent, and that SALAD achieves a superior intelligibility score while obtaining speech quality and speaker similarity on par with the ground-truth audio.
LiveXiv -- A Multi-Modal Live Benchmark Based on Arxiv Papers Content
Oct 15, 2024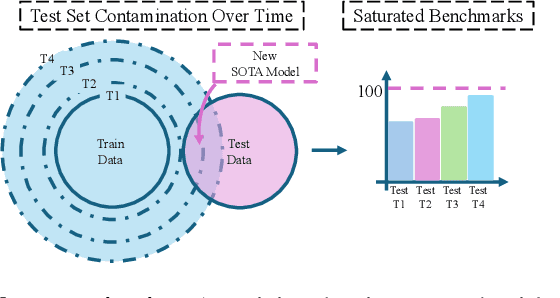



The large-scale training of multi-modal models on data scraped from the web has shown outstanding utility in infusing these models with the required world knowledge to perform effectively on multiple downstream tasks. However, one downside of scraping data from the web can be the potential sacrifice of the benchmarks on which the abilities of these models are often evaluated. To safeguard against test data contamination and to truly test the abilities of these foundation models we propose LiveXiv: A scalable evolving live benchmark based on scientific ArXiv papers. LiveXiv accesses domain-specific manuscripts at any given timestamp and proposes to automatically generate visual question-answer pairs (VQA). This is done without any human-in-the-loop, using the multi-modal content in the manuscripts, like graphs, charts, and tables. Moreover, we introduce an efficient evaluation approach that estimates the performance of all models on the evolving benchmark using evaluations of only a subset of models. This significantly reduces the overall evaluation cost. We benchmark multiple open and proprietary Large Multi-modal Models (LMMs) on the first version of our benchmark, showing its challenging nature and exposing the models true abilities, avoiding contamination. Lastly, in our commitment to high quality, we have collected and evaluated a manually verified subset. By comparing its overall results to our automatic annotations, we have found that the performance variance is indeed minimal (<2.5%). Our dataset is available online on HuggingFace, and our code will be available here.
Deep Phase Coded Image Prior
Apr 05, 2024



Phase-coded imaging is a computational imaging method designed to tackle tasks such as passive depth estimation and extended depth of field (EDOF) using depth cues inserted during image capture. Most of the current deep learning-based methods for depth estimation or all-in-focus imaging require a training dataset with high-quality depth maps and an optimal focus point at infinity for all-in-focus images. Such datasets are difficult to create, usually synthetic, and require external graphic programs. We propose a new method named "Deep Phase Coded Image Prior" (DPCIP) for jointly recovering the depth map and all-in-focus image from a coded-phase image using solely the captured image and the optical information of the imaging system. Our approach does not depend on any specific dataset and surpasses prior supervised techniques utilizing the same imaging system. This improvement is achieved through the utilization of a problem formulation based on implicit neural representation (INR) and deep image prior (DIP). Due to our zero-shot method, we overcome the barrier of acquiring accurate ground-truth data of depth maps and all-in-focus images for each new phase-coded system introduced. This allows focusing mainly on developing the imaging system, and not on ground-truth data collection.
PIP: Positional-encoding Image Prior
Nov 25, 2022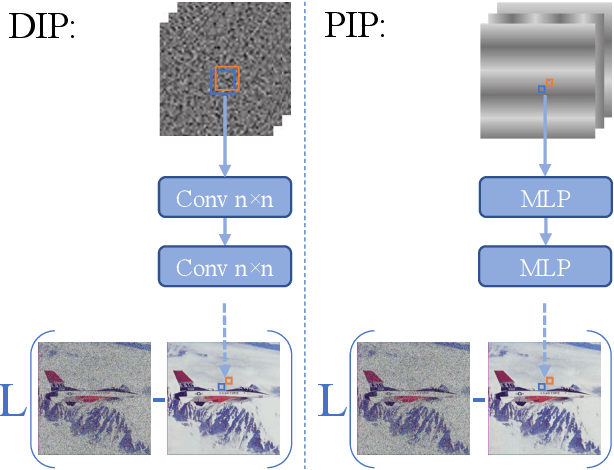

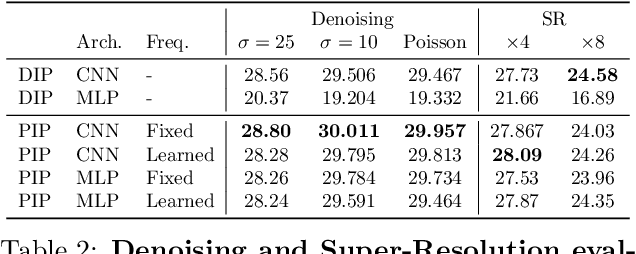

In Deep Image Prior (DIP), a Convolutional Neural Network (CNN) is fitted to map a latent space to a degraded (e.g. noisy) image but in the process learns to reconstruct the clean image. This phenomenon is attributed to CNN's internal image-prior. We revisit the DIP framework, examining it from the perspective of a neural implicit representation. Motivated by this perspective, we replace the random or learned latent with Fourier-Features (Positional Encoding). We show that thanks to the Fourier features properties, we can replace the convolution layers with simple pixel-level MLPs. We name this scheme ``Positional Encoding Image Prior" (PIP) and exhibit that it performs very similarly to DIP on various image-reconstruction tasks with much less parameters required. Additionally, we demonstrate that PIP can be easily extended to videos, where 3D-DIP struggles and suffers from instability. Code and additional examples for all tasks, including videos, are available on the project page https://nimrodshabtay.github.io/PIP/