 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deep Learning Models Resistant to Large Perturbations
Paper and Code
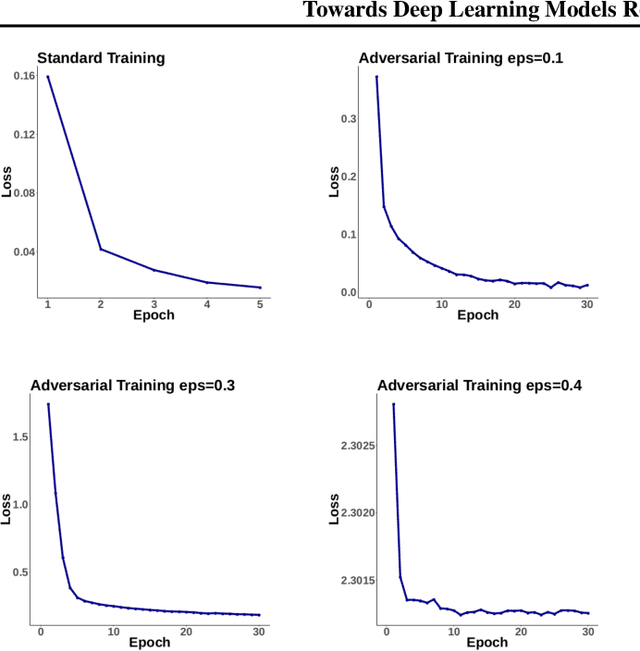
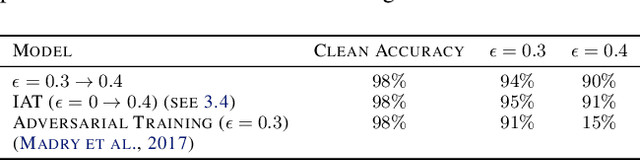
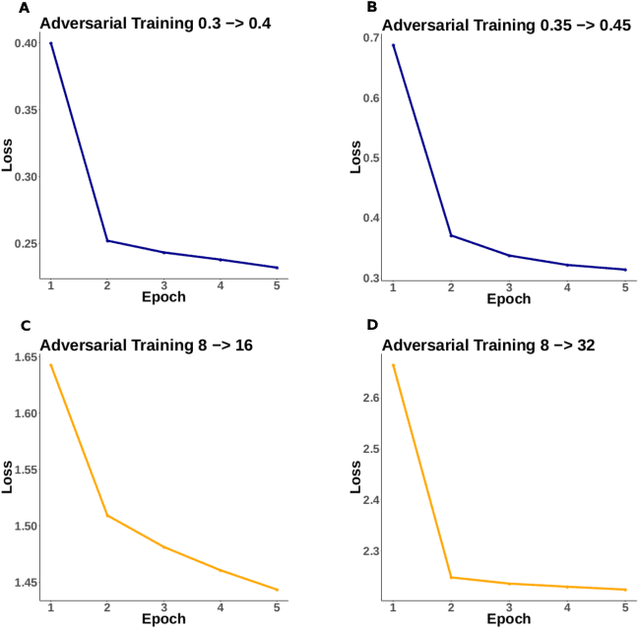

Adversarial robustness has proven to be a required property of machine learning algorithms. A key and often overlooked aspect of this problem is to try to make the adversarial noise magnitude as large as possible to enhance the benefits of the model robustness. We show that the well-established algorithm called "adversarial training" fails to train a deep neural network given a large, but reasonable, perturbation magnitude. In this paper, we propose a simple yet effective initialization of the network weights that makes learning on higher levels of noise possible. We next evaluate this idea rigorously on MNIST ($\epsilon$ up to $\approx 0.40$) and CIFAR10 ($\epsilon$ up to $\approx 32/255$) datasets assuming the $\ell_{\infty}$ attack model. Additionally, in order to establish the limits of $\epsilon$ in which the learning is feasible, we study the optimal robust classifier assuming full access to the joint data and label distribution. Then, we provide some theoretical results on the adversarial accuracy for a simple multi-dimensional Bernoulli distribution, which yields some insights on the range of feasible perturbations for the MNIST dataset.