 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Data Generation Using Diffusion Models
Feb 04, 2025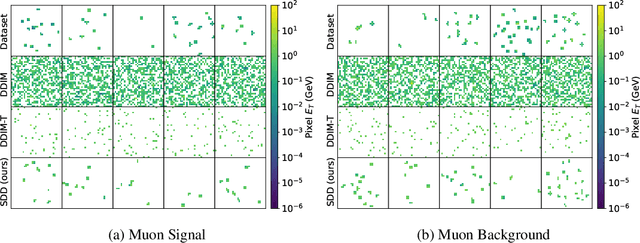
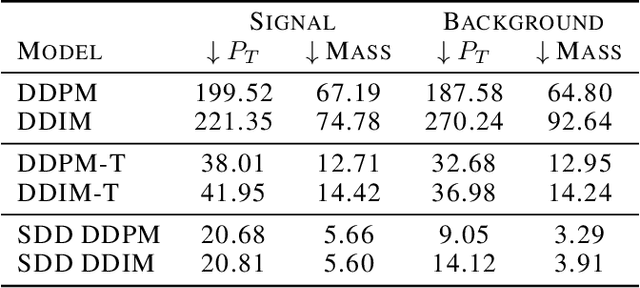
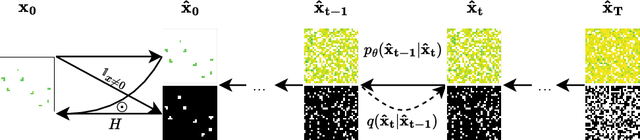
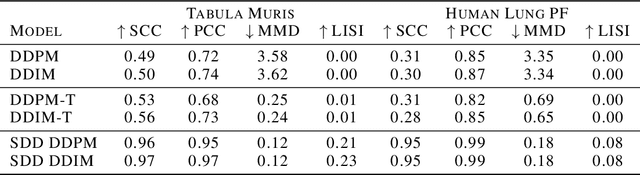
Sparse data is ubiquitous, appearing in numerous domains, from economics and recommender systems to astronomy and biomedical sciences. However, efficiently and realistically generating sparse data remains a significant challenge. We introduce Sparse Data Diffusion (SDD), a novel method for generating sparse data. SDD extends continuous state-space diffusion models by explicitly modeling sparsity through the introduction of Sparsity Bits. Empirical validation on image data from various domains-including two scientific applications, physics and biology-demonstrates that SDD achieves high fidelity in representing data sparsity while preserving the quality of the generated data.
Challenging Assumptions in Learning Generic Text Style Embeddings
Jan 27, 2025


Recent advancements in language representation learning primarily emphasize language modeling for deriving meaningful representations, often neglecting style-specific considerations. This study addresses this gap by creating generic, sentence-level style embeddings crucial for style-centric tasks. Our approach is grounded on the premise that low-level text style changes can compose any high-level style. We hypothesize that applying this concept to representation learning enables the development of versatile text style embeddings. By fine-tuning a general-purpose text encoder using contrastive learning and standard cross-entropy loss, we aim to capture these low-level style shifts, anticipating that they offer insights applicable to high-level text styles. The outcomes prompt us to reconsider the underlying assumptions as the results do not always show that the learned style representations capture high-level text styles.
BBPOS: BERT-based Part-of-Speech Tagging for Uzbek
Jan 17, 2025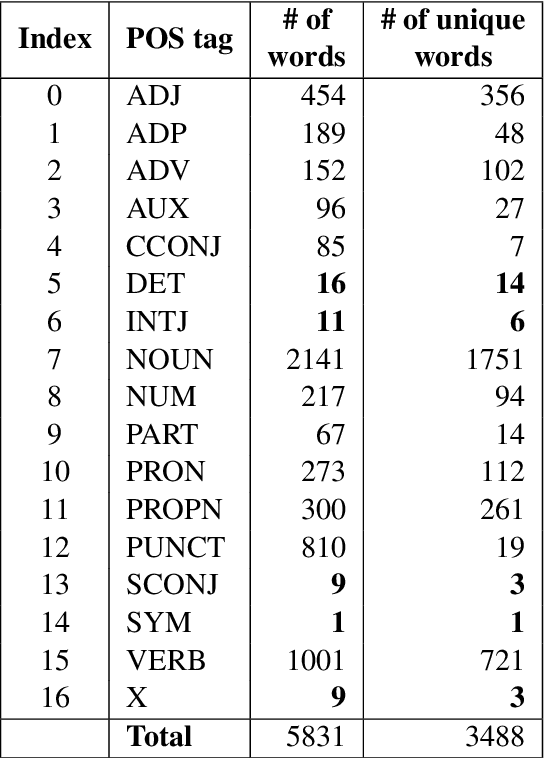
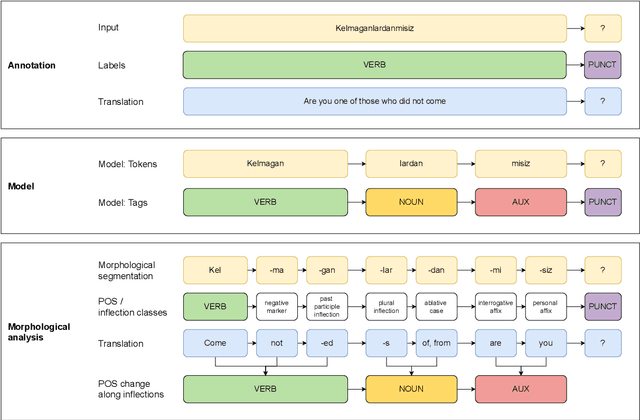

This paper advances NLP research for the low-resource Uzbek language by evaluating two previously untested monolingual Uzbek BERT models on the part-of-speech (POS) tagging task and introducing the first publicly available UPOS-tagged benchmark dataset for Uzbek. Our fine-tuned models achieve 91% average accuracy, outperforming the baseline multi-lingual BERT as well as the rule-based tagger. Notably, these models capture intermediate POS changes through affixes and demonstrate context sensitivity, unlike existing rule-based taggers.
Tethering Broken Themes: Aligning Neural Topic Models with Labels and Authors
Oct 22, 2024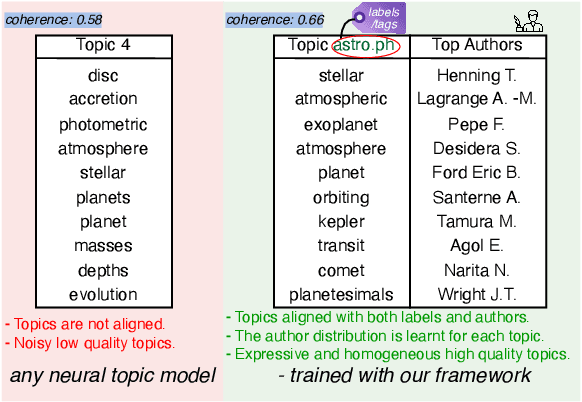
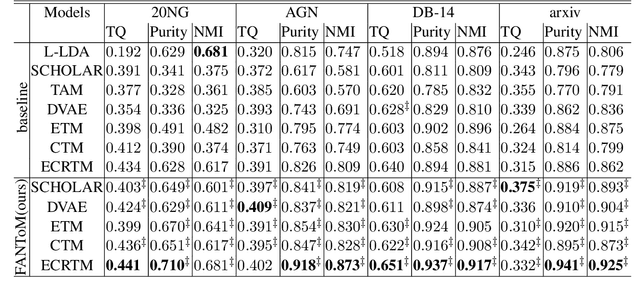
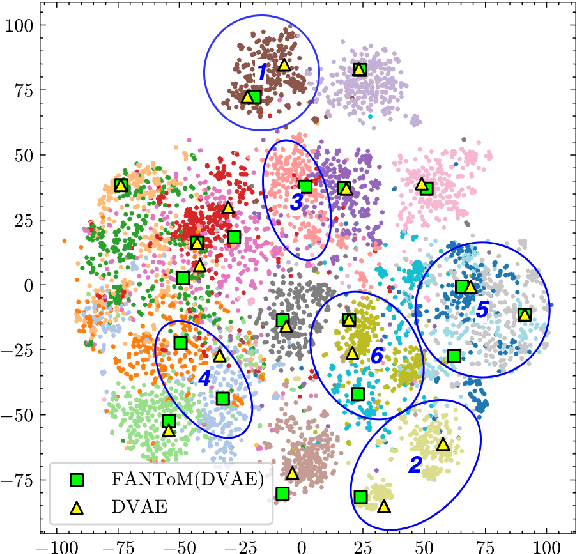
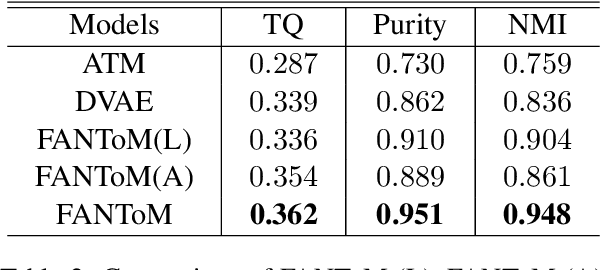
Topic models are a popular approach for extracting semantic information from large document collections. However, recent studies suggest that the topics generated by these models often do not align well with human intentions. While metadata such as labels and authorship information is available, it has not yet been effectively incorporated into neural topic models. To address this gap, we introduce FANToM, a novel method for aligning neural topic models with both labels and authorship information. FANToM allows for the inclusion of this metadata when available, producing interpretable topics and author distributions for each topic. Our approach demonstrates greater expressiveness than conventional topic models by learning the alignment between labels, topics, and authors. Experimental results show that FANToM improves upon existing models in terms of both topic quality and alignment. Additionally, it identifies author interests and similarities.
SetPINNs: Set-based Physics-informed Neural Networks
Sep 30, 2024Physics-Informed Neural Networks (PINNs) have emerged as a promising method for approximating solutions to partial differential equations (PDEs) using deep learning. However, PINNs, based on multilayer perceptrons (MLP), often employ point-wise predictions, overlooking the implicit dependencies within the physical system such as temporal or spatial dependencies. These dependencies can be captured using more complex network architectures, for example CNNs or Transformers. However, these architectures conventionally do not allow for incorporating physical constraints, as advancements in integrating such constraints within these frameworks are still lacking. Relying on point-wise predictions often results in trivial solutions. To address this limitation, we propose SetPINNs, a novel approach inspired by Finite Elements Methods from the field of Numerical Analysis. SetPINNs allow for incorporating the dependencies inherent in the physical system while at the same time allowing for incorporating the physical constraints. They accurately approximate PDE solutions of a region, thereby modeling the inherent dependencies between multiple neighboring points in that region. Our experiments show that SetPINNs demonstrate superior generalization performance and accuracy across diverse physical systems, showing that they mitigate failure modes and converge faster in comparison to existing approaches. Furthermore, we demonstrate the utility of SetPINNs on two real-world physical systems.
Text Style Transfer Evaluation Using Large Language Models
Aug 25, 2023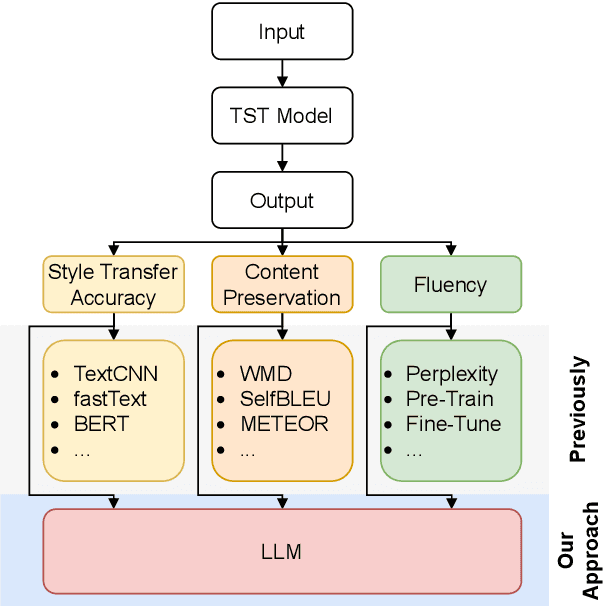
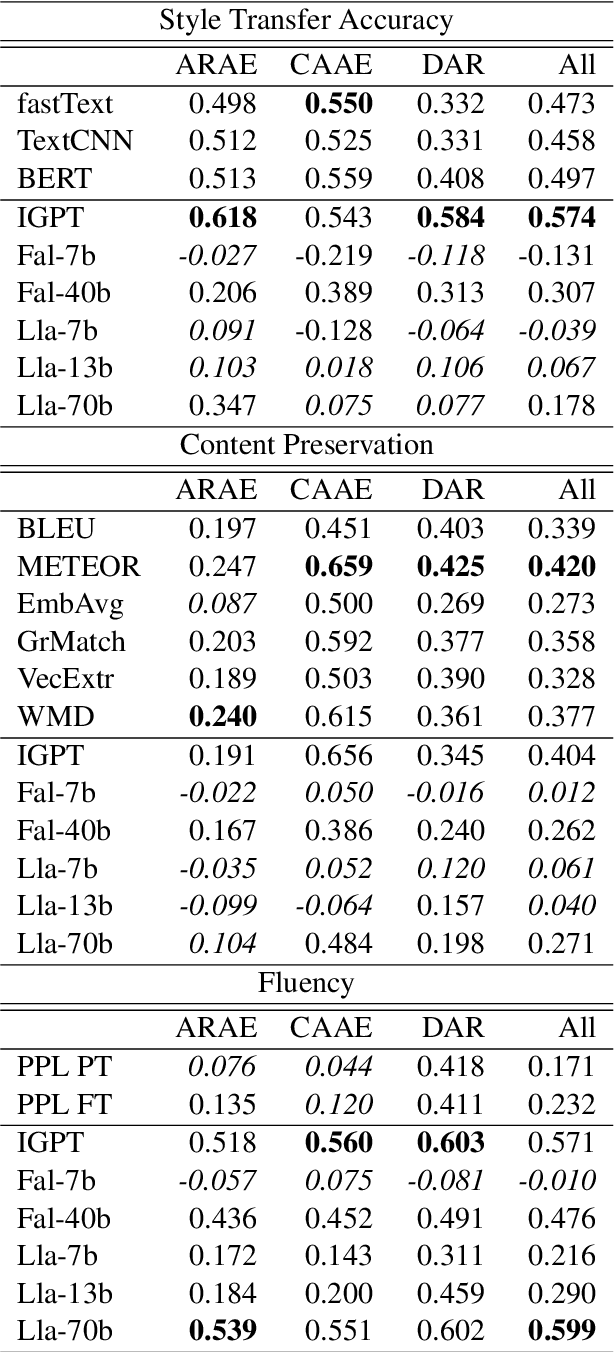

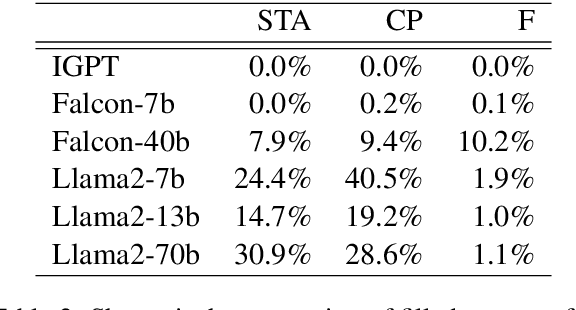
Text Style Transfer (TST) is challenging to evaluate because the quality of the generated text manifests itself in multiple aspects, each of which is hard to measure individually: style transfer accuracy, content preservation, and overall fluency of the text. Human evaluation is the gold standard in TST evaluation; however, it is expensive, and the results are difficult to reproduce. Numerous automated metrics are employed to assess performance in these aspects, serving as substitutes for human evaluation. However, the correlation between many of these automated metrics and human evaluations remains unclear, raising doubts about their effectiveness as reliable benchmarks. Recent advancements in Large Language Models (LLMs) have demonstrated their ability to not only match but also surpass the average human performance across a wide range of unseen tasks. This suggests that LLMs have the potential to serve as a viable alternative to human evaluation and other automated metrics. We assess the performance of different LLMs on TST evaluation by employing multiple input prompts and comparing their results. Our findings indicate that (even zero-shot) prompting correlates strongly with human evaluation and often surpasses the performance of (other) automated metrics. Additionally, we propose the ensembling of prompts and show it increases the robustness of TST evaluation.This work contributes to the ongoing efforts in evaluating LLMs on diverse tasks, which includes a discussion of failure cases and limitations.
A Call for Standardization and Validation of Text Style Transfer Evaluation
Jun 01, 2023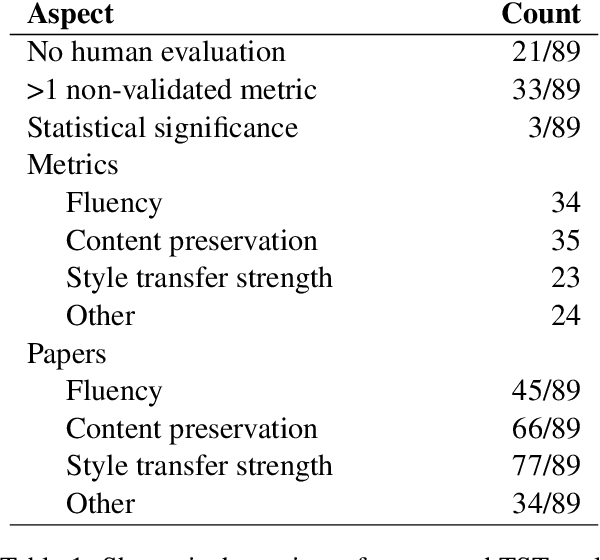
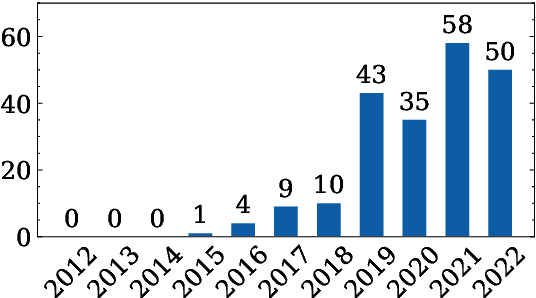


Text Style Transfer (TST) evaluation is, in practice, inconsistent. Therefore, we conduct a meta-analysis on human and automated TST evaluation and experimentation that thoroughly examines existing literature in the field. The meta-analysis reveals a substantial standardization gap in human and automated evaluation. In addition, we also find a validation gap: only few automated metrics have been validated using human experiments. To this end, we thoroughly scrutinize both the standardization and validation gap and reveal the resulting pitfalls. This work also paves the way to close the standardization and validation gap in TST evaluation by calling out requirements to be met by future research.