 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Style Transfer Evaluation Using Large Language Models
Paper and Code
Aug 25, 2023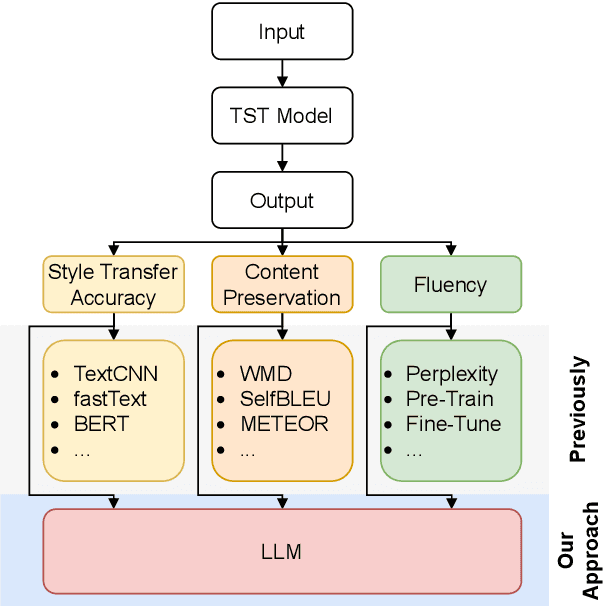
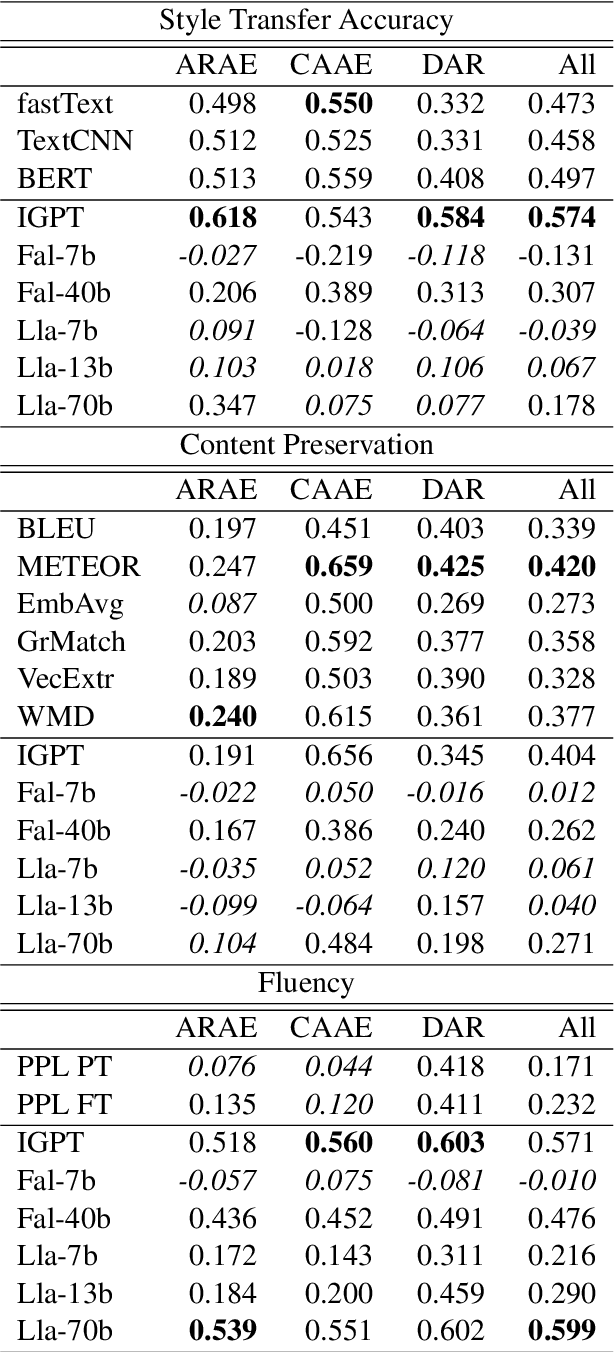

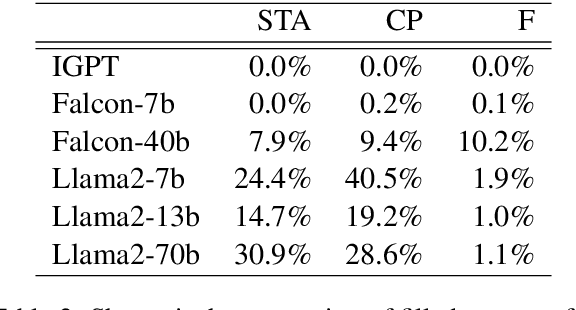
Text Style Transfer (TST) is challenging to evaluate because the quality of the generated text manifests itself in multiple aspects, each of which is hard to measure individually: style transfer accuracy, content preservation, and overall fluency of the text. Human evaluation is the gold standard in TST evaluation; however, it is expensive, and the results are difficult to reproduce. Numerous automated metrics are employed to assess performance in these aspects, serving as substitutes for human evaluation. However, the correlation between many of these automated metrics and human evaluations remains unclear, raising doubts about their effectiveness as reliable benchmarks. Recent advancements in Large Language Models (LLMs) have demonstrated their ability to not only match but also surpass the average human performance across a wide range of unseen tasks. This suggests that LLMs have the potential to serve as a viable alternative to human evaluation and other automated metrics. We assess the performance of different LLMs on TST evaluation by employing multiple input prompts and comparing their results. Our findings indicate that (even zero-shot) prompting correlates strongly with human evaluation and often surpasses the performance of (other) automated metrics. Additionally, we propose the ensembling of prompts and show it increases the robustness of TST evaluation.This work contributes to the ongoing efforts in evaluating LLMs on diverse tasks, which includes a discussion of failure cases and limitations.