 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic-Geometric Task Graph-Representations from Human Demonstrations
Jan 16, 2026Learning structured task representations from human demonstrations is essential for understanding long-horizon manipulation behaviors, particularly in bimanual settings where action ordering, object involvement, and interaction geometry can vary significantly. A key challenge lies in jointly capturing the discrete semantic structure of tasks and the temporal evolution of object-centric geometric relations in a form that supports reasoning over task progression. In this work, we introduce a semantic-geometric task graph-representation that encodes object identities, inter-object relations, and their temporal geometric evolution from human demonstrations. Building on this formulation, we propose a learning framework that combines a Message Passing Neural Network (MPNN) encoder with a Transformer-based decoder, decoupling scene representation learning from action-conditioned reasoning about task progression. The encoder operates solely on temporal scene graphs to learn structured representations, while the decoder conditions on action-context to predict future action sequences, associated objects, and object motions over extended time horizons. Through extensive evaluation on human demonstration datasets, we show that semantic-geometric task graph-representations are particularly beneficial for tasks with high action and object variability, where simpler sequence-based models struggle to capture task progression. Finally, we demonstrate that task graph representations can be transferred to a physical bimanual robot and used for online action selection, highlighting their potential as reusable task abstractions for downstream decision-making in manipulation systems.
Investigating the Effect of LED Signals and Emotional Displays in Human-Robot Shared Workspaces
Sep 18, 2025



Effective communication is essential for safety and efficiency in human-robot collaboration, particularly in shared workspaces. This paper investigates the impact of nonverbal communication on human-robot interaction (HRI) by integrating reactive light signals and emotional displays into a robotic system. We equipped a Franka Emika Panda robot with an LED strip on its end effector and an animated facial display on a tablet to convey movement intent through colour-coded signals and facial expressions. We conducted a human-robot collaboration experiment with 18 participants, evaluating three conditions: LED signals alone, LED signals with reactive emotional displays, and LED signals with pre-emptive emotional displays. We collected data through questionnaires and position tracking to assess anticipation of potential collisions, perceived clarity of communication, and task performance. The results indicate that while emotional displays increased the perceived interactivity of the robot, they did not significantly improve collision anticipation, communication clarity, or task efficiency compared to LED signals alone. These findings suggest that while emotional cues can enhance user engagement, their impact on task performance in shared workspaces is limited.
Grasp Diffusion Network: Learning Grasp Generators from Partial Point Clouds with Diffusion Models in SO(3)xR3
Dec 11, 2024



Grasping objects successfully from a single-view camera is crucial in many robot manipulation tasks. An approach to solve this problem is to leverage simulation to create large datasets of pairs of objects and grasp poses, and then learn a conditional generative model that can be prompted quickly during deployment. However, the grasp pose data is highly multimodal since there are several ways to grasp an object. Hence, in this work, we learn a grasp generative model with diffusion models to sample candidate grasp poses given a partial point cloud of an object. A novel aspect of our method is to consider diffusion in the manifold space of rotations and to propose a collision-avoidance cost guidance to improve the grasp success rate during inference. To accelerate grasp sampling we use recent techniques from the diffusion literature to achieve faster inference times. We show in simulation and real-world experiments that our approach can grasp several objects from raw depth images with $90\%$ success rate and benchmark it against several baselines.
MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations
Jul 10, 2024Shared dynamics models are important for capturing the complexity and variability inherent in Human-Robot Interaction (HRI). Therefore, learning such shared dynamics models can enhance coordination and adaptability to enable successful reactive interactions with a human partner. In this work, we propose a novel approach for learning a shared latent space representation for HRIs from demonstrations in a Mixture of Experts fashion for reactively generating robot actions from human observations. We train a Variational Autoencoder (VAE) to learn robot motions regularized using an informative latent space prior that captures the multimodality of the human observations via a Mixture Density Network (MDN). We show how our formulation derives from a Gaussian Mixture Regression formulation that is typically used approaches for learning HRI from demonstrations such as using an HMM/GMM for learning a joint distribution over the actions of the human and the robot. We further incorporate an additional regularization to prevent "mode collapse", a common phenomenon when using latent space mixture models with VAEs. We find that our approach of using an informative MDN prior from human observations for a VAE generates more accurate robot motions compared to previous HMM-based or recurrent approaches of learning shared latent representations, which we validate on various HRI datasets involving interactions such as handshakes, fistbumps, waving, and handovers. Further experiments in a real-world human-to-robot handover scenario show the efficacy of our approach for generating successful interactions with four different human interaction partners.
Transition State Clustering for Interaction Segmentation and Learning
Feb 22, 2024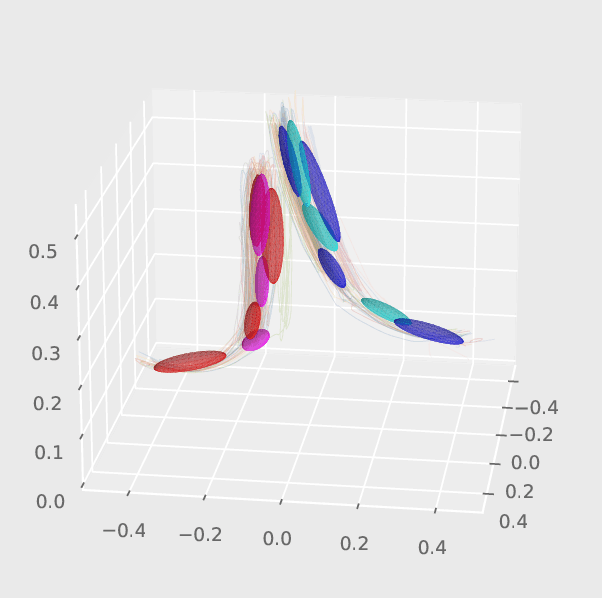

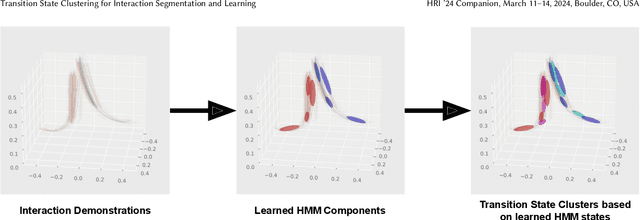

Hidden Markov Models with an underlying Mixture of Gaussian structure have proven effective in learning Human-Robot Interactions from demonstrations for various interactive tasks via Gaussian Mixture Regression. However, a mismatch occurs when segmenting the interaction using only the observed state of the human compared to the joint state of the human and the robot. To enhance this underlying segmentation and subsequently the predictive abilities of such Gaussian Mixture-based approaches, we take a hierarchical approach by learning an additional mixture distribution on the states at the transition boundary. This helps prevent misclassifications that usually occur in such states. We find that our framework improves the performance of the underlying Gaussian Mixture-based approach, which we evaluate on various interactive tasks such as handshaking and fistbumps.
Kinematically Constrained Human-like Bimanual Robot-to-Human Handovers
Feb 22, 2024

Bimanual handovers are crucial for transferring large, deformable or delicate objects. This paper proposes a framework for generating kinematically constrained human-like bimanual robot motions to ensure seamless and natural robot-to-human object handovers. We use a Hidden Semi-Markov Model (HSMM) to reactively generate suitable response trajectories for a robot based on the observed human partner's motion. The trajectories are adapted with task space constraints to ensure accurate handovers. Results from a pilot study show that our approach is perceived as more human--like compared to a baseline Inverse Kinematics approach.
Learning Multimodal Latent Dynamics for Human-Robot Interaction
Nov 27, 2023This article presents a method for learning well-coordinated Human-Robot Interaction (HRI) from Human-Human Interactions (HHI). We devise a hybrid approach using Hidden Markov Models (HMMs) as the latent space priors for a Variational Autoencoder to model a joint distribution over the interacting agents. We leverage the interaction dynamics learned from HHI to learn HRI and incorporate the conditional generation of robot motions from human observations into the training, thereby predicting more accurate robot trajectories. The generated robot motions are further adapted with Inverse Kinematics to ensure the desired physical proximity with a human, combining the ease of joint space learning and accurate task space reachability. For contact-rich interactions, we modulate the robot's stiffness using HMM segmentation for a compliant interaction. We verify the effectiveness of our approach deployed on a Humanoid robot via a user study. Our method generalizes well to various humans despite being trained on data from just two humans. We find that Users perceive our method as more human-like, timely, and accurate and rank our method with a higher degree of preference over other baselines.
Motion Planning Diffusion: Learning and Planning of Robot Motions with Diffusion Models
Aug 03, 2023Learning priors on trajectory distributions can help accelerate robot motion planning optimization. Given previously successful plans, learning trajectory generative models as priors for a new planning problem is highly desirable. Prior works propose several ways on utilizing this prior to bootstrapping the motion planning problem. Either sampling the prior for initializations or using the prior distribution in a maximum-a-posterior formulation for trajectory optimization. In this work, we propose learning diffusion models as priors. We then can sample directly from the posterior trajectory distribution conditioned on task goals, by leveraging the inverse denoising process of diffusion models. Furthermore, diffusion has been recently shown to effectively encode data multimodality in high-dimensional settings, which is particularly well-suited for large trajectory dataset. To demonstrate our method efficacy, we compare our proposed method - Motion Planning Diffusion - against several baselines in simulated planar robot and 7-dof robot arm manipulator environments. To assess the generalization capabilities of our method, we test it in environments with previously unseen obstacles. Our experiments show that diffusion models are strong priors to encode high-dimensional trajectory distributions of robot motions.
Residual Robot Learning for Object-Centric Probabilistic Movement Primitives
Mar 08, 2022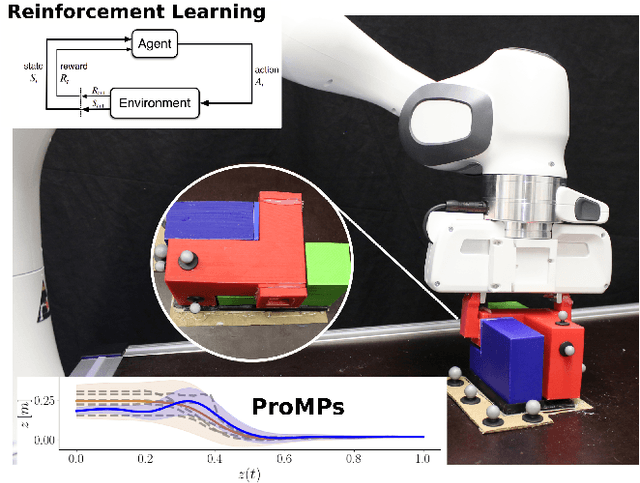
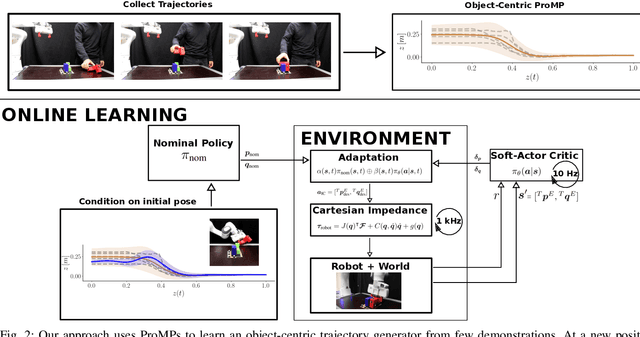
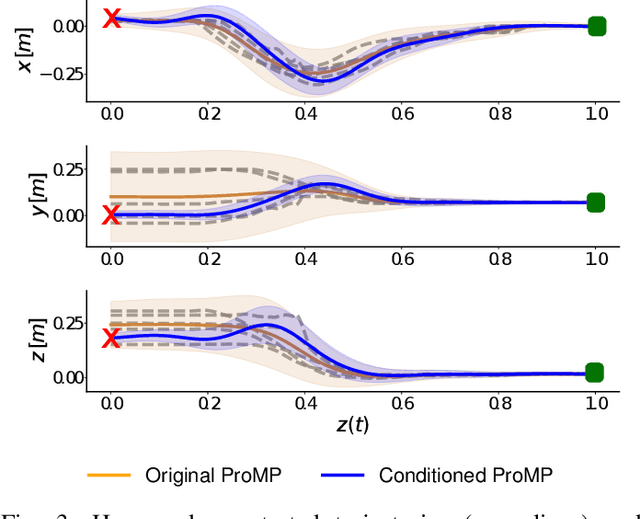

It is desirable for future robots to quickly learn new tasks and adapt learned skills to constantly changing environments. To this end, Probabilistic Movement Primitives (ProMPs) have shown to be a promising framework to learn generalizable trajectory generators from distributions over demonstrated trajectories. However, in practical applications that require high precision in the manipulation of objects, the accuracy of ProMPs is often insufficient, in particular when they are learned in cartesian space from external observations and executed with limited controller gains. Therefore, we propose to combine ProMPs with recently introduced Residual Reinforcement Learning (RRL), to account for both, corrections in position and orientation during task execution. In particular, we learn a residual on top of a nominal ProMP trajectory with Soft-Actor Critic and incorporate the variability in the demonstrations as a decision variable to reduce the search space for RRL. As a proof of concept, we evaluate our proposed method on a 3D block insertion task with a 7-DoF Franka Emika Panda robot. Experimental results show that the robot successfully learns to complete the insertion which was not possible before with using basic ProMPs.
Multimodal Uncertainty Reduction for Intention Recognition in Human-Robot Interaction
Jul 04, 2019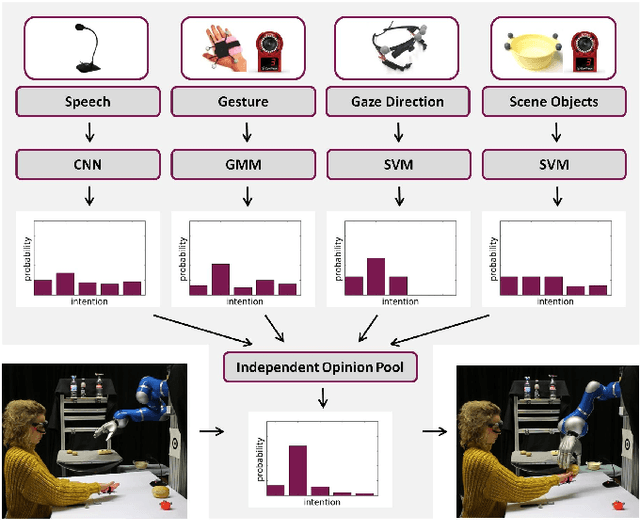
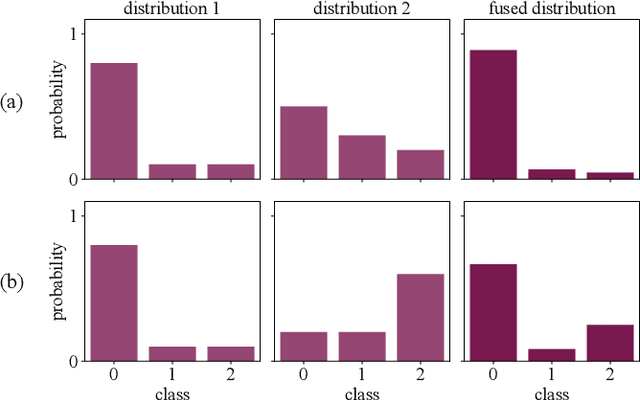

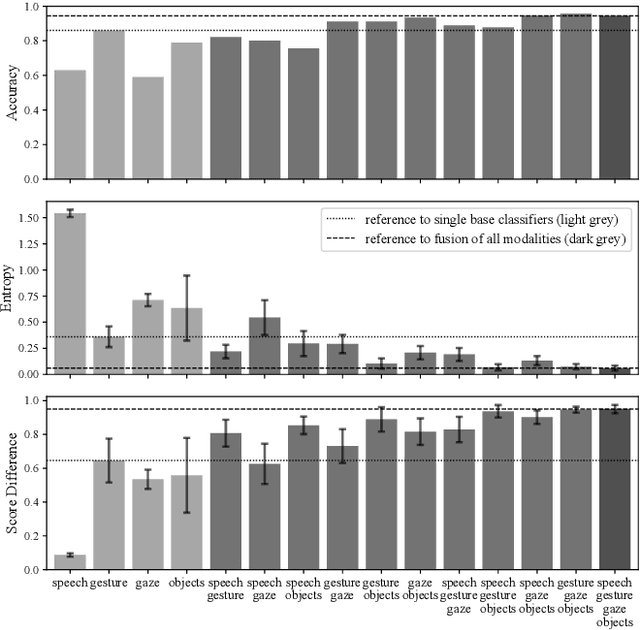
Assistive robots can potentially improve the quality of life and personal independence of elderly people by supporting everyday life activities. To guarantee a safe and intuitive interaction between human and robot, human intentions need to be recognized automatically. As humans communicate their intentions multimodally, the use of multiple modalities for intention recognition may not just increase the robustness against failure of individual modalities but especially reduce the uncertainty about the intention to be predicted. This is desirable as particularly in direct interaction between robots and potentially vulnerable humans a minimal uncertainty about the situation as well as knowledge about this actual uncertainty is necessary. Thus, in contrast to existing methods, in this work a new approach for multimodal intention recognition is introduced that focuses on uncertainty reduction through classifier fusion. For the four considered modalities speech, gestures, gaze directions and scene objects individual intention classifiers are trained, all of which output a probability distribution over all possible intentions. By combining these output distributions using the Bayesian method Independent Opinion Pool the uncertainty about the intention to be recognized can be decreased. The approach is evaluated in a collaborative human-robot interaction task with a 7-DoF robot arm. The results show that fused classifiers which combine multiple modalities outperform the respective individual base classifiers with respect to increased accuracy, robustness, and reduced uncertainty.