 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Semantic-Geometric Task Graph-Representations from Human Demonstrations
Jan 16, 2026Learning structured task representations from human demonstrations is essential for understanding long-horizon manipulation behaviors, particularly in bimanual settings where action ordering, object involvement, and interaction geometry can vary significantly. A key challenge lies in jointly capturing the discrete semantic structure of tasks and the temporal evolution of object-centric geometric relations in a form that supports reasoning over task progression. In this work, we introduce a semantic-geometric task graph-representation that encodes object identities, inter-object relations, and their temporal geometric evolution from human demonstrations. Building on this formulation, we propose a learning framework that combines a Message Passing Neural Network (MPNN) encoder with a Transformer-based decoder, decoupling scene representation learning from action-conditioned reasoning about task progression. The encoder operates solely on temporal scene graphs to learn structured representations, while the decoder conditions on action-context to predict future action sequences, associated objects, and object motions over extended time horizons. Through extensive evaluation on human demonstration datasets, we show that semantic-geometric task graph-representations are particularly beneficial for tasks with high action and object variability, where simpler sequence-based models struggle to capture task progression. Finally, we demonstrate that task graph representations can be transferred to a physical bimanual robot and used for online action selection, highlighting their potential as reusable task abstractions for downstream decision-making in manipulation systems.
Self-Supervised Multisensory Pretraining for Contact-Rich Robot Reinforcement Learning
Nov 18, 2025
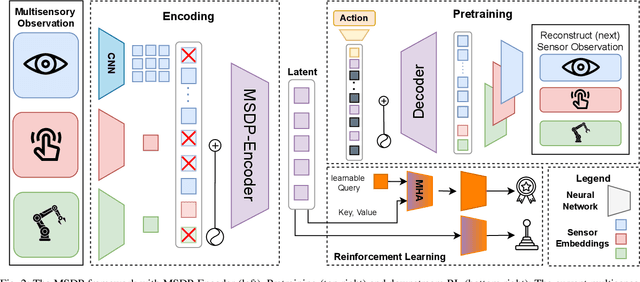
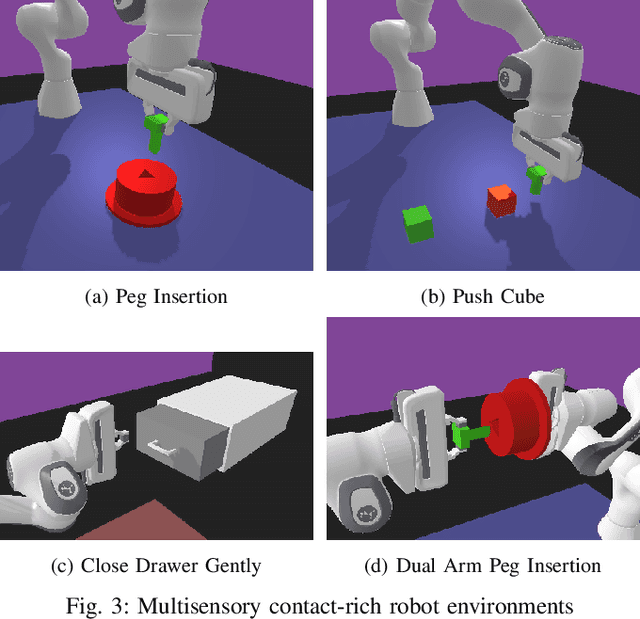
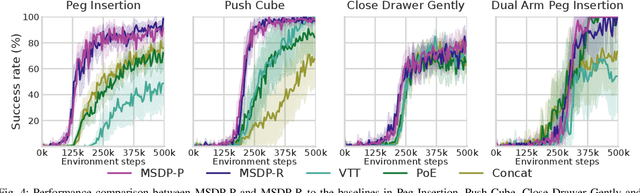
Effective contact-rich manipulation requires robots to synergistically leverage vision, force, and proprioception. However, Reinforcement Learning agents struggle to learn in such multisensory settings, especially amidst sensory noise and dynamic changes. We propose MultiSensory Dynamic Pretraining (MSDP), a novel framework for learning expressive multisensory representations tailored for task-oriented policy learning. MSDP is based on masked autoencoding and trains a transformer-based encoder by reconstructing multisensory observations from only a subset of sensor embeddings, leading to cross-modal prediction and sensor fusion. For downstream policy learning, we introduce a novel asymmetric architecture, where a cross-attention mechanism allows the critic to extract dynamic, task-specific features from the frozen embeddings, while the actor receives a stable pooled representation to guide its actions. Our method demonstrates accelerated learning and robust performance under diverse perturbations, including sensor noise, and changes in object dynamics. Evaluations in multiple challenging, contact-rich robot manipulation tasks in simulation and the real world showcase the effectiveness of MSDP. Our approach exhibits strong robustness to perturbations and achieves high success rates on the real robot with as few as 6,000 online interactions, offering a simple yet powerful solution for complex multisensory robotic control.
2HandedAfforder: Learning Precise Actionable Bimanual Affordances from Human Videos
Mar 13, 2025When interacting with objects, humans effectively reason about which regions of objects are viable for an intended action, i.e., the affordance regions of the object. They can also account for subtle differences in object regions based on the task to be performed and whether one or two hands need to be used. However, current vision-based affordance prediction methods often reduce the problem to naive object part segmentation. In this work, we propose a framework for extracting affordance data from human activity video datasets. Our extracted 2HANDS dataset contains precise object affordance region segmentations and affordance class-labels as narrations of the activity performed. The data also accounts for bimanual actions, i.e., two hands co-ordinating and interacting with one or more objects. We present a VLM-based affordance prediction model, 2HandedAfforder, trained on the dataset and demonstrate superior performance over baselines in affordance region segmentation for various activities. Finally, we show that our predicted affordance regions are actionable, i.e., can be used by an agent performing a task, through demonstration in robotic manipulation scenarios.
6DOPE-GS: Online 6D Object Pose Estimation using Gaussian Splatting
Dec 02, 2024Efficient and accurate object pose estimation is an essential component for modern vision systems in many applications such as Augmented Reality, autonomous driving, and robotics. While research in model-based 6D object pose estimation has delivered promising results, model-free methods are hindered by the high computational load in rendering and inferring consistent poses of arbitrary objects in a live RGB-D video stream. To address this issue, we present 6DOPE-GS, a novel method for online 6D object pose estimation \& tracking with a single RGB-D camera by effectively leveraging advances in Gaussian Splatting. Thanks to the fast differentiable rendering capabilities of Gaussian Splatting, 6DOPE-GS can simultaneously optimize for 6D object poses and 3D object reconstruction. To achieve the necessary efficiency and accuracy for live tracking, our method uses incremental 2D Gaussian Splatting with an intelligent dynamic keyframe selection procedure to achieve high spatial object coverage and prevent erroneous pose updates. We also propose an opacity statistic-based pruning mechanism for adaptive Gaussian density control, to ensure training stability and efficiency. We evaluate our method on the HO3D and YCBInEOAT datasets and show that 6DOPE-GS matches the performance of state-of-the-art baselines for model-free simultaneous 6D pose tracking and reconstruction while providing a 5$\times$ speedup. We also demonstrate the method's suitability for live, dynamic object tracking and reconstruction in a real-world setting.
ActionFlow: Equivariant, Accurate, and Efficient Policies with Spatially Symmetric Flow Matching
Sep 06, 2024



Spatial understanding is a critical aspect of most robotic tasks, particularly when generalization is important. Despite the impressive results of deep generative models in complex manipulation tasks, the absence of a representation that encodes intricate spatial relationships between observations and actions often limits spatial generalization, necessitating large amounts of demonstrations. To tackle this problem, we introduce a novel policy class, ActionFlow. ActionFlow integrates spatial symmetry inductive biases while generating expressive action sequences. On the representation level, ActionFlow introduces an SE(3) Invariant Transformer architecture, which enables informed spatial reasoning based on the relative SE(3) poses between observations and actions. For action generation, ActionFlow leverages Flow Matching, a state-of-the-art deep generative model known for generating high-quality samples with fast inference - an essential property for feedback control. In combination, ActionFlow policies exhibit strong spatial and locality biases and SE(3)-equivariant action generation. Our experiments demonstrate the effectiveness of ActionFlow and its two main components on several simulated and real-world robotic manipulation tasks and confirm that we can obtain equivariant, accurate, and efficient policies with spatially symmetric flow matching. Project website: https://flowbasedpolicies.github.io/
MoVEInt: Mixture of Variational Experts for Learning Human-Robot Interactions from Demonstrations
Jul 10, 2024Shared dynamics models are important for capturing the complexity and variability inherent in Human-Robot Interaction (HRI). Therefore, learning such shared dynamics models can enhance coordination and adaptability to enable successful reactive interactions with a human partner. In this work, we propose a novel approach for learning a shared latent space representation for HRIs from demonstrations in a Mixture of Experts fashion for reactively generating robot actions from human observations. We train a Variational Autoencoder (VAE) to learn robot motions regularized using an informative latent space prior that captures the multimodality of the human observations via a Mixture Density Network (MDN). We show how our formulation derives from a Gaussian Mixture Regression formulation that is typically used approaches for learning HRI from demonstrations such as using an HMM/GMM for learning a joint distribution over the actions of the human and the robot. We further incorporate an additional regularization to prevent "mode collapse", a common phenomenon when using latent space mixture models with VAEs. We find that our approach of using an informative MDN prior from human observations for a VAE generates more accurate robot motions compared to previous HMM-based or recurrent approaches of learning shared latent representations, which we validate on various HRI datasets involving interactions such as handshakes, fistbumps, waving, and handovers. Further experiments in a real-world human-to-robot handover scenario show the efficacy of our approach for generating successful interactions with four different human interaction partners.
Kinematically Constrained Human-like Bimanual Robot-to-Human Handovers
Feb 22, 2024

Bimanual handovers are crucial for transferring large, deformable or delicate objects. This paper proposes a framework for generating kinematically constrained human-like bimanual robot motions to ensure seamless and natural robot-to-human object handovers. We use a Hidden Semi-Markov Model (HSMM) to reactively generate suitable response trajectories for a robot based on the observed human partner's motion. The trajectories are adapted with task space constraints to ensure accurate handovers. Results from a pilot study show that our approach is perceived as more human--like compared to a baseline Inverse Kinematics approach.
Transition State Clustering for Interaction Segmentation and Learning
Feb 22, 2024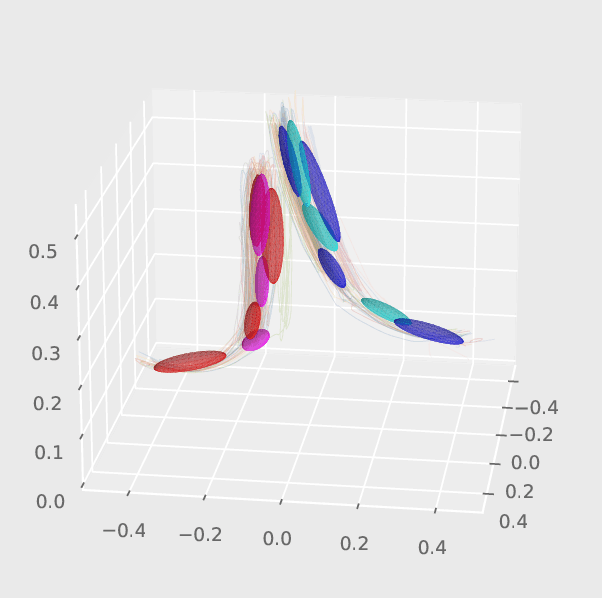

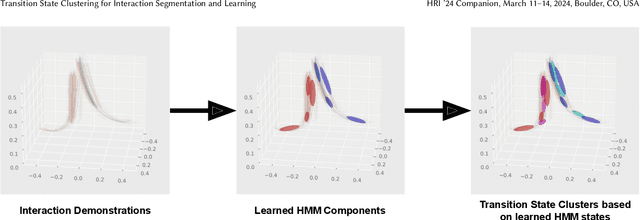

Hidden Markov Models with an underlying Mixture of Gaussian structure have proven effective in learning Human-Robot Interactions from demonstrations for various interactive tasks via Gaussian Mixture Regression. However, a mismatch occurs when segmenting the interaction using only the observed state of the human compared to the joint state of the human and the robot. To enhance this underlying segmentation and subsequently the predictive abilities of such Gaussian Mixture-based approaches, we take a hierarchical approach by learning an additional mixture distribution on the states at the transition boundary. This helps prevent misclassifications that usually occur in such states. We find that our framework improves the performance of the underlying Gaussian Mixture-based approach, which we evaluate on various interactive tasks such as handshaking and fistbumps.
Learning Multimodal Latent Dynamics for Human-Robot Interaction
Nov 27, 2023This article presents a method for learning well-coordinated Human-Robot Interaction (HRI) from Human-Human Interactions (HHI). We devise a hybrid approach using Hidden Markov Models (HMMs) as the latent space priors for a Variational Autoencoder to model a joint distribution over the interacting agents. We leverage the interaction dynamics learned from HHI to learn HRI and incorporate the conditional generation of robot motions from human observations into the training, thereby predicting more accurate robot trajectories. The generated robot motions are further adapted with Inverse Kinematics to ensure the desired physical proximity with a human, combining the ease of joint space learning and accurate task space reachability. For contact-rich interactions, we modulate the robot's stiffness using HMM segmentation for a compliant interaction. We verify the effectiveness of our approach deployed on a Humanoid robot via a user study. Our method generalizes well to various humans despite being trained on data from just two humans. We find that Users perceive our method as more human-like, timely, and accurate and rank our method with a higher degree of preference over other baselines.
Learning Human-like Hand Reaching for Human-Robot Handshaking
Feb 28, 2021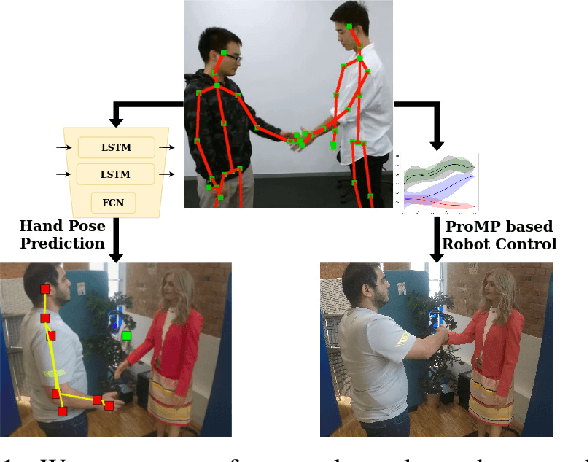
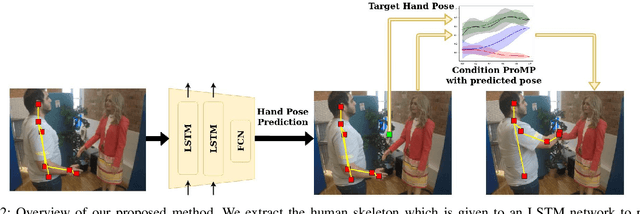


One of the first and foremost non-verbal interactions that humans perform is a handshake. It has an impact on first impressions as touch can convey complex emotions. This makes handshaking an important skill for the repertoire of a social robot. In this paper, we present a novel framework for learning human-robot handshaking behaviours for humanoid robots solely using third-person human-human interaction data. This is especially useful for non-backdrivable robots that cannot be taught by demonstrations via kinesthetic teaching. Our approach can be easily executed on different humanoid robots. This removes the need for re-training, which is especially tedious when training with human-interaction partners. We show this by applying the learnt behaviours on two different humanoid robots with similar degrees of freedom but different shapes and control limits.