 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolmoB0T: Large-Scale Simulation Enables Zero-Shot Manipulation
Mar 17, 2026A prevailing view in robot learning is that simulation alone is not enough; effective sim-to-real transfer is widely believed to require at least some real-world data collection or task-specific fine-tuning to bridge the gap between simulated and physical environments. We challenge that assumption. With sufficiently large-scale and diverse simulated synthetic training data, we show that zero-shot transfer to the real world is not only possible, but effective for both static and mobile manipulation. We introduce MolmoBot-Engine, a fully open-source pipeline for procedural data generation across robots, tasks, and diverse simulated environments in MolmoSpaces. With it, we release MolmoBot-Data, a dataset of 1.8 million expert trajectories for articulated object manipulation and pick-and-place tasks. We train three policy classes: MolmoBot, a Molmo2-based multi-frame vision-language model with a flow-matching action head; MolmoBot-Pi0, which replicates the $π_0$ architecture to enable direct comparison; and MolmoBot-SPOC, a lightweight policy suitable for edge deployment and amenable to RL fine-tuning. We evaluate on two robotic platforms: the Franka FR3 for tabletop manipulation tasks and the Rainbow Robotics RB-Y1 mobile manipulator for door opening, drawer manipulation, cabinet interaction, and mobile pick-and-place. Without any real-world fine-tuning, our policies achieve zero-shot transfer to unseen objects and environments. On tabletop pick-and-place, MolmoBot achieves a success rate of 79.2% in real world evaluations across 4 settings, outperforming $π_{0.5}$ at 39.2%. Our results demonstrate that procedural environment generation combined with diverse articulated assets can produce robust manipulation policies that generalize broadly to the real world. Technical Blog: https://allenai.org/blog/molmobot-robot-manipulation
MolmoSpaces: A Large-Scale Open Ecosystem for Robot Navigation and Manipulation
Feb 11, 2026Deploying robots at scale demands robustness to the long tail of everyday situations. The countless variations in scene layout, object geometry, and task specifications that characterize real environments are vast and underrepresented in existing robot benchmarks. Measuring this level of generalization requires infrastructure at a scale and diversity that physical evaluation alone cannot provide. We introduce MolmoSpaces, a fully open ecosystem to support large-scale benchmarking of robot policies. MolmoSpaces consists of over 230k diverse indoor environments, ranging from handcrafted household scenes to procedurally generated multiroom houses, populated with 130k richly annotated object assets, including 48k manipulable objects with 42M stable grasps. Crucially, these environments are simulator-agnostic, supporting popular options such as MuJoCo, Isaac, and ManiSkill. The ecosystem supports the full spectrum of embodied tasks: static and mobile manipulation, navigation, and multiroom long-horizon tasks requiring coordinated perception, planning, and interaction across entire indoor environments. We also design MolmoSpaces-Bench, a benchmark suite of 8 tasks in which robots interact with our diverse scenes and richly annotated objects. Our experiments show MolmoSpaces-Bench exhibits strong sim-to-real correlation (R = 0.96, \r{ho} = 0.98), confirm newer and stronger zero-shot policies outperform earlier versions in our benchmarks, and identify key sensitivities to prompt phrasing, initial joint positions, and camera occlusion. Through MolmoSpaces and its open-source assets and tooling, we provide a foundation for scalable data generation, policy training, and benchmark creation for robot learning research.
2HandedAfforder: Learning Precise Actionable Bimanual Affordances from Human Videos
Mar 13, 2025When interacting with objects, humans effectively reason about which regions of objects are viable for an intended action, i.e., the affordance regions of the object. They can also account for subtle differences in object regions based on the task to be performed and whether one or two hands need to be used. However, current vision-based affordance prediction methods often reduce the problem to naive object part segmentation. In this work, we propose a framework for extracting affordance data from human activity video datasets. Our extracted 2HANDS dataset contains precise object affordance region segmentations and affordance class-labels as narrations of the activity performed. The data also accounts for bimanual actions, i.e., two hands co-ordinating and interacting with one or more objects. We present a VLM-based affordance prediction model, 2HandedAfforder, trained on the dataset and demonstrate superior performance over baselines in affordance region segmentation for various activities. Finally, we show that our predicted affordance regions are actionable, i.e., can be used by an agent performing a task, through demonstration in robotic manipulation scenarios.
6DOPE-GS: Online 6D Object Pose Estimation using Gaussian Splatting
Dec 02, 2024Efficient and accurate object pose estimation is an essential component for modern vision systems in many applications such as Augmented Reality, autonomous driving, and robotics. While research in model-based 6D object pose estimation has delivered promising results, model-free methods are hindered by the high computational load in rendering and inferring consistent poses of arbitrary objects in a live RGB-D video stream. To address this issue, we present 6DOPE-GS, a novel method for online 6D object pose estimation \& tracking with a single RGB-D camera by effectively leveraging advances in Gaussian Splatting. Thanks to the fast differentiable rendering capabilities of Gaussian Splatting, 6DOPE-GS can simultaneously optimize for 6D object poses and 3D object reconstruction. To achieve the necessary efficiency and accuracy for live tracking, our method uses incremental 2D Gaussian Splatting with an intelligent dynamic keyframe selection procedure to achieve high spatial object coverage and prevent erroneous pose updates. We also propose an opacity statistic-based pruning mechanism for adaptive Gaussian density control, to ensure training stability and efficiency. We evaluate our method on the HO3D and YCBInEOAT datasets and show that 6DOPE-GS matches the performance of state-of-the-art baselines for model-free simultaneous 6D pose tracking and reconstruction while providing a 5$\times$ speedup. We also demonstrate the method's suitability for live, dynamic object tracking and reconstruction in a real-world setting.
Active-Perceptive Motion Generation for Mobile Manipulation
Sep 30, 2023
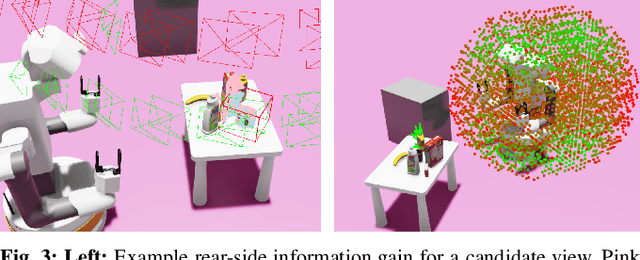


Mobile Manipulation (MoMa) systems incorporate the benefits of mobility and dexterity, thanks to the enlarged space in which they can move and interact with their environment. MoMa robots can also continuously perceive their environment when equipped with onboard sensors, e.g., an embodied camera. However, extracting task-relevant visual information in unstructured and cluttered environments such as households remains a challenge. In this work, we introduce an active perception pipeline for mobile manipulators to generate motions that are informative toward manipulation tasks such as grasping, in initially unknown, cluttered scenes. Our proposed approach ActPerMoMa generates robot trajectories in a receding horizon fashion, sampling trajectories and computing path-wise utilities that trade-off reconstructing the unknown scene by maximizing the visual information gain and the taskoriented objective, e.g., grasp success by maximizing grasp reachability efficiently. We demonstrate the efficacy of our method in simulated experiments with a dual-arm TIAGo++ MoMa robot performing mobile grasping in cluttered scenes and when its path is obstructed by external obstacles. We empirically analyze the contribution of various utilities and hyperparameters, and compare against representative baselines both with and without active perception objectives. Finally, we demonstrate the transfer of our mobile grasping strategy to the real world, showing a promising direction for active-perceptive MoMa.
Learning Any-View 6DoF Robotic Grasping in Cluttered Scenes via Neural Surface Rendering
Jun 25, 2023



Robotic manipulation is critical for admitting robotic agents to various application domains, like intelligent assistance. A major challenge therein is the effective 6DoF grasping of objects in cluttered environments from any viewpoint without requiring additional scene exploration. We introduce $\textit{NeuGraspNet}$, a novel method for 6DoF grasp detection that leverages recent advances in neural volumetric representations and surface rendering. Our approach learns both global (scene-level) and local (grasp-level) neural surface representations, enabling effective and fully implicit 6DoF grasp quality prediction, even in unseen parts of the scene. Further, we reinterpret grasping as a local neural surface rendering problem, allowing the model to encode the interaction between the robot's end-effector and the object's surface geometry. NeuGraspNet operates on single viewpoints and can sample grasp candidates in occluded scenes, outperforming existing implicit and semi-implicit baseline methods in the literature. We demonstrate the real-world applicability of NeuGraspNet with a mobile manipulator robot, grasping in open spaces with clutter by rendering the scene, reasoning about graspable areas of different objects, and selecting grasps likely to succeed without colliding with the environment. Visit our project website: https://sites.google.com/view/neugraspnet
Safe reinforcement learning of dynamic high-dimensional robotic tasks: navigation, manipulation, interaction
Sep 27, 2022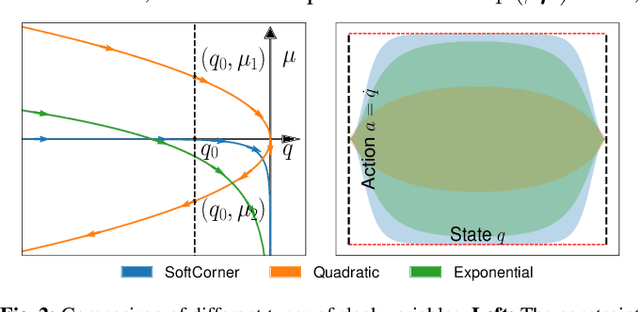

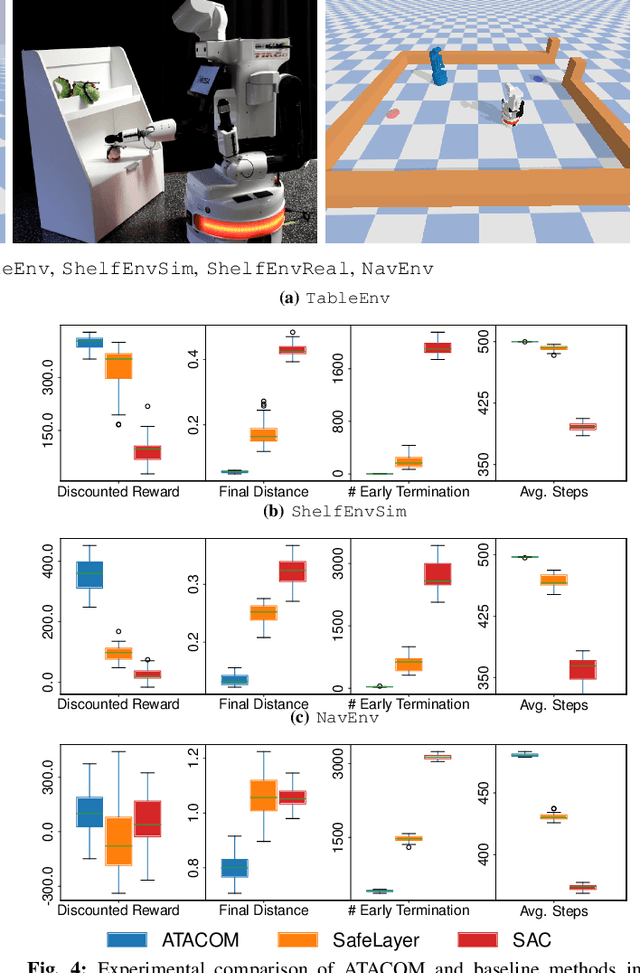
Safety is a crucial property of every robotic platform: any control policy should always comply with actuator limits and avoid collisions with the environment and humans. In reinforcement learning, safety is even more fundamental for exploring an environment without causing any damage. While there are many proposed solutions to the safe exploration problem, only a few of them can deal with the complexity of the real world. This paper introduces a new formulation of safe exploration for reinforcement learning of various robotic tasks. Our approach applies to a wide class of robotic platforms and enforces safety even under complex collision constraints learned from data by exploring the tangent space of the constraint manifold. Our proposed approach achieves state-of-the-art performance in simulated high-dimensional and dynamic tasks while avoiding collisions with the environment. We show safe real-world deployment of our learned controller on a TIAGo++ robot, achieving remarkable performance in manipulation and human-robot interaction tasks.
Regularized Deep Signed Distance Fields for Reactive Motion Generation
Mar 09, 2022
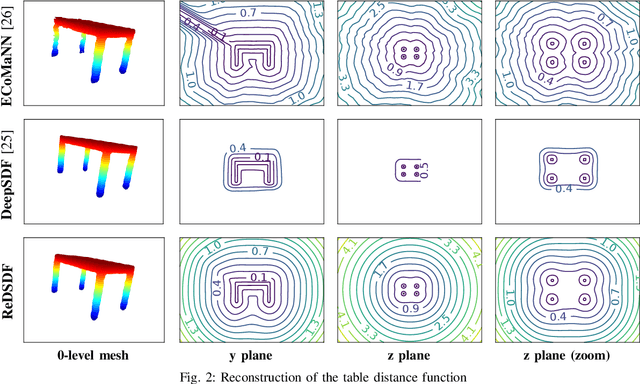
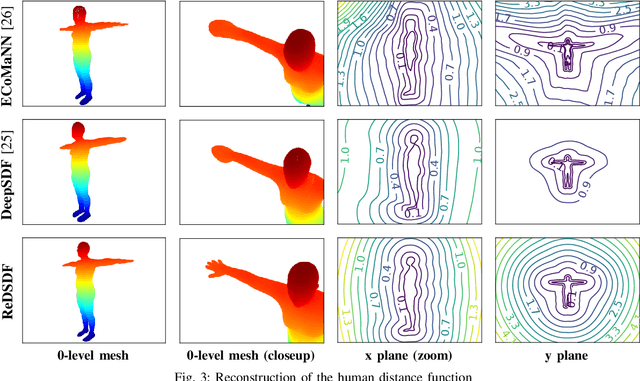
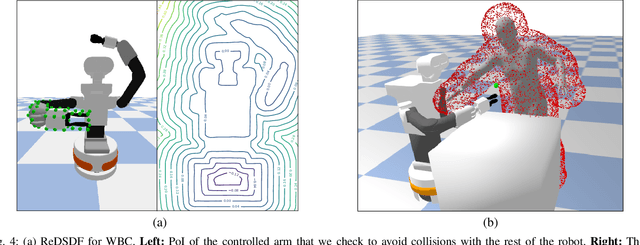
Autonomous robots should operate in real-world dynamic environments and collaborate with humans in tight spaces. A key component for allowing robots to leave structured lab and manufacturing settings is their ability to evaluate online and real-time collisions with the world around them. Distance-based constraints are fundamental for enabling robots to plan their actions and act safely, protecting both humans and their hardware. However, different applications require different distance resolutions, leading to various heuristic approaches for measuring distance fields w.r.t. obstacles, which are computationally expensive and hinder their application in dynamic obstacle avoidance use-cases. We propose Regularized Deep Signed Distance Fields (ReDSDF), a single neural implicit function that can compute smooth distance fields at any scale, with fine-grained resolution over high-dimensional manifolds and articulated bodies like humans, thanks to our effective data generation and a simple inductive bias during training. We demonstrate the effectiveness of our approach in representative simulated tasks for whole-body control (WBC) and safe Human-Robot Interaction (HRI) in shared workspaces. Finally, we provide proof of concept of a real-world application in a HRI handover task with a mobile manipulator robot.
Robot Learning of Mobile Manipulation with Reachability Behavior Priors
Mar 08, 2022
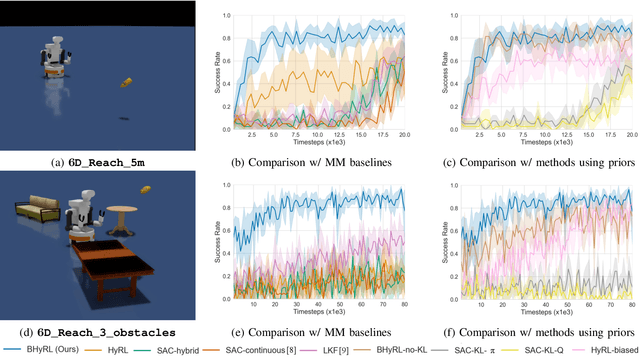

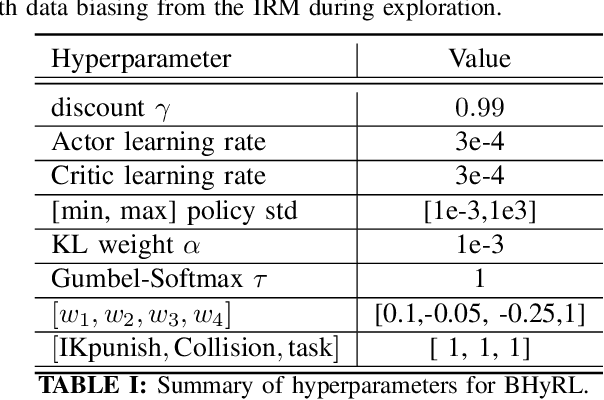
Mobile Manipulation (MM) systems are ideal candidates for taking up the role of a personal assistant in unstructured real-world environments. Among other challenges, MM requires effective coordination of the robot's embodiments for executing tasks that require both mobility and manipulation. Reinforcement Learning (RL) holds the promise of endowing robots with adaptive behaviors, but most methods require prohibitively large amounts of data for learning a useful control policy. In this work, we study the integration of robotic reachability priors in actor-critic RL methods for accelerating the learning of MM for reaching and fetching tasks. Namely, we consider the problem of optimal base placement and the subsequent decision of whether to activate the arm for reaching a 6D target. For this, we devise a novel Hybrid RL method that handles discrete and continuous actions jointly, resorting to the Gumbel-Softmax reparameterization. Next, we train a reachability prior using data from the operational robot workspace, inspired by classical methods. Subsequently, we derive Boosted Hybrid RL (BHyRL), a novel algorithm for learning Q-functions by modeling them as a sum of residual approximators. Every time a new task needs to be learned, we can transfer our learned residuals and learn the component of the Q-function that is task-specific, hence, maintaining the task structure from prior behaviors. Moreover, we find that regularizing the target policy with a prior policy yields more expressive behaviors. We evaluate our method in simulation in reaching and fetching tasks of increasing difficulty, and we show the superior performance of BHyRL against baseline methods. Finally, we zero-transfer our learned 6D fetching policy with BHyRL to our MM robot TIAGo++. For more details and code release, please refer to our project site: irosalab.com/rlmmbp
Interactive Imitation Learning in State-Space
Aug 02, 2020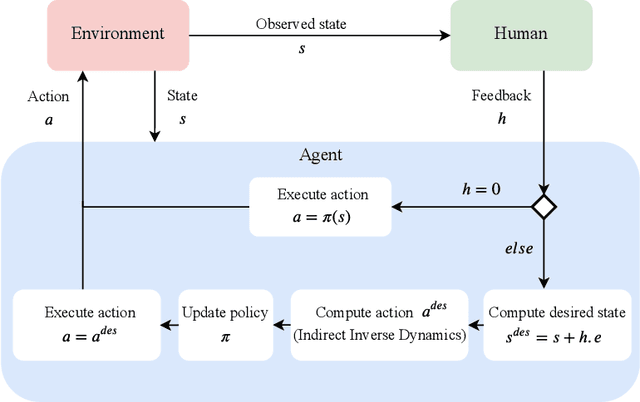
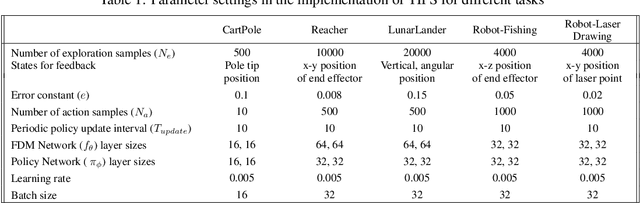
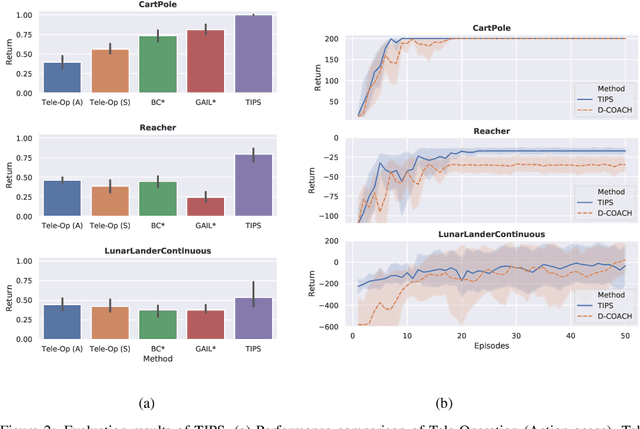
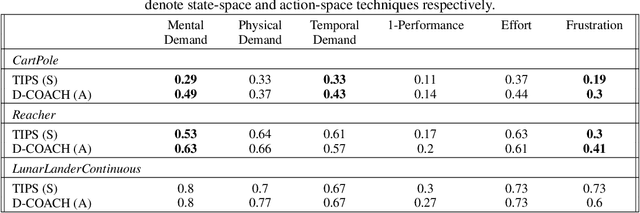
Imitation Learning techniques enable programming the behavior of agents through demonstrations rather than manual engineering. However, they are limited by the quality of available demonstration data. Interactive Imitation Learning techniques can improve the efficacy of learning since they involve teachers providing feedback while the agent executes its task. In this work, we propose a novel Interactive Learning technique that uses human feedback in state-space to train and improve agent behavior (as opposed to alternative methods that use feedback in action-space). Our method titled Teaching Imitative Policies in State-space~(TIPS) enables providing guidance to the agent in terms of `changing its state' which is often more intuitive for a human demonstrator. Through continuous improvement via corrective feedback, agents trained by non-expert demonstrators using TIPS outperformed the demonstrator and conventional Imitation Learning agents.