 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Human-in-the-loop Coordination of Manipulation Skills Learned from Demonstration
Mar 01, 2022


Learning from demonstration (LfD) provides a fast, intuitive and efficient framework to program robot skills, which has gained growing interest both in research and industrial applications. Most complex manipulation tasks are long-term and involve a set of skill primitives. Thus it is crucial to have a reliable coordination scheme that selects the correct sequence of skill primitive and the correct parameters for each skill, under various scenarios. Instead of relying on a precise simulator, this work proposes a human-in-the-loop coordination framework for LfD skills that: builds parameterized skill models from kinesthetic demonstrations; constructs a geometric task network (GTN) on-the-fly from human instructions; learns a hierarchical control policy incrementally during execution. This framework can reduce significantly the manual design efforts, while improving the adaptability to new scenes. We show on a 7-DoF robotic manipulator that the proposed approach can teach complex industrial tasks such as bin sorting and assembly in less than 30 minutes.
Learning Forceful Manipulation Skills from Multi-modal Human Demonstrations
Sep 09, 2021
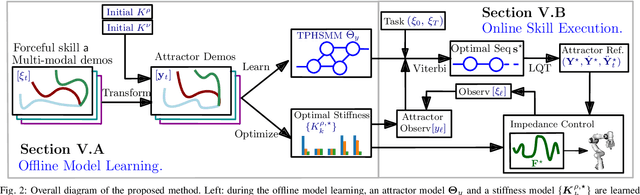
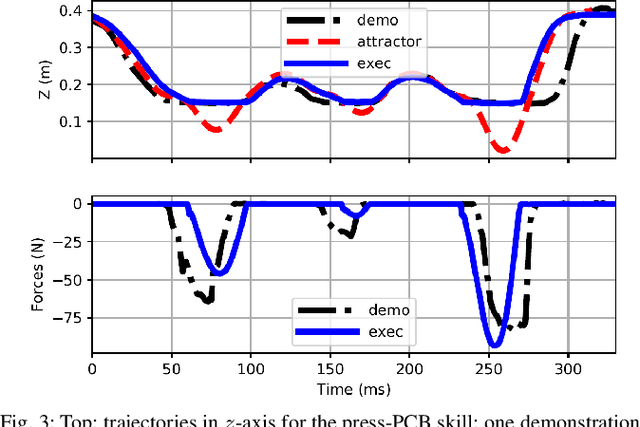
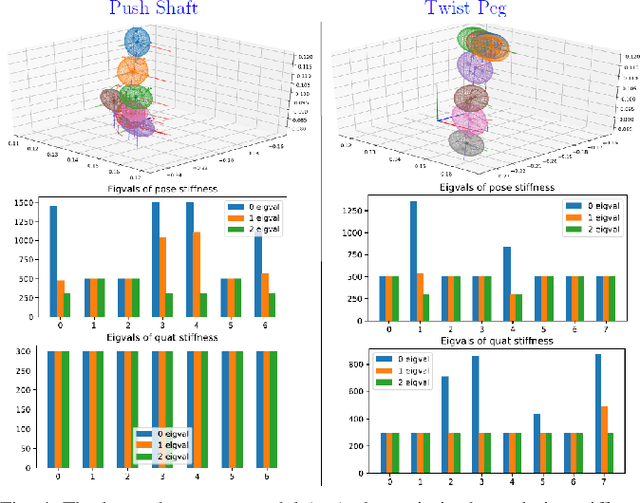
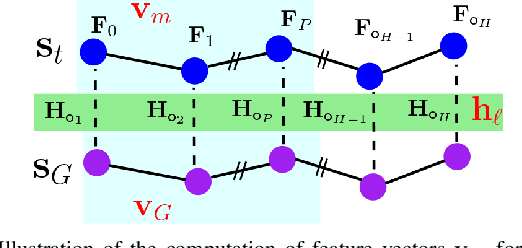
Learning from Demonstration (LfD) provides an intuitive and fast approach to program robotic manipulators. Task parameterized representations allow easy adaptation to new scenes and online observations. However, this approach has been limited to pose-only demonstrations and thus only skills with spatial and temporal features. In this work, we extend the LfD framework to address forceful manipulation skills, which are of great importance for industrial processes such as assembly. For such skills, multi-modal demonstrations including robot end-effector poses, force and torque readings, and operation scene are essential. Our objective is to reproduce such skills reliably according to the demonstrated pose and force profiles within different scenes. The proposed method combines our previous work on task-parameterized optimization and attractor-based impedance control. The learned skill model consists of (i) the attractor model that unifies the pose and force features, and (ii) the stiffness model that optimizes the stiffness for different stages of the skill. Furthermore, an online execution algorithm is proposed to adapt the skill execution to real-time observations of robot poses, measured forces, and changed scenes. We validate this method rigorously on a 7-DoF robot arm over several steps of an E-bike motor assembly process, which require different types of forceful interaction such as insertion, sliding and twisting.
Supervised Training of Dense Object Nets using Optimal Descriptors for Industrial Robotic Applications
Feb 16, 2021


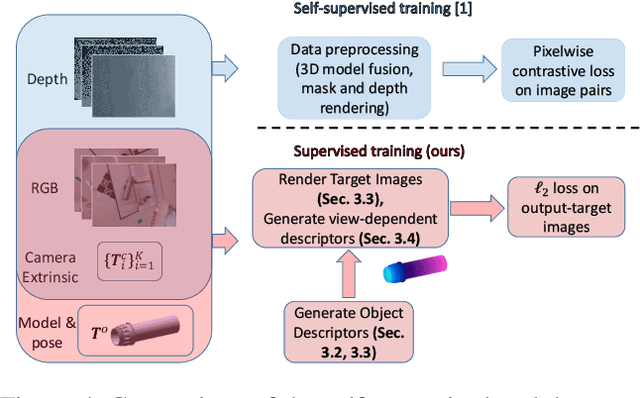
Dense Object Nets (DONs) by Florence, Manuelli and Tedrake (2018) introduced dense object descriptors as a novel visual object representation for the robotics community. It is suitable for many applications including object grasping, policy learning, etc. DONs map an RGB image depicting an object into a descriptor space image, which implicitly encodes key features of an object invariant to the relative camera pose. Impressively, the self-supervised training of DONs can be applied to arbitrary objects and can be evaluated and deployed within hours. However, the training approach relies on accurate depth images and faces challenges with small, reflective objects, typical for industrial settings, when using consumer grade depth cameras. In this paper we show that given a 3D model of an object, we can generate its descriptor space image, which allows for supervised training of DONs. We rely on Laplacian Eigenmaps (LE) to embed the 3D model of an object into an optimally generated space. While our approach uses more domain knowledge, it can be efficiently applied even for smaller and reflective objects, as it does not rely on depth information. We compare the training methods on generating 6D grasps for industrial objects and show that our novel supervised training approach improves the pick-and-place performance in industry-relevant tasks.