 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSADL: An Effective In-Context Learning Method for Compositional Visual QA
Paper and Code



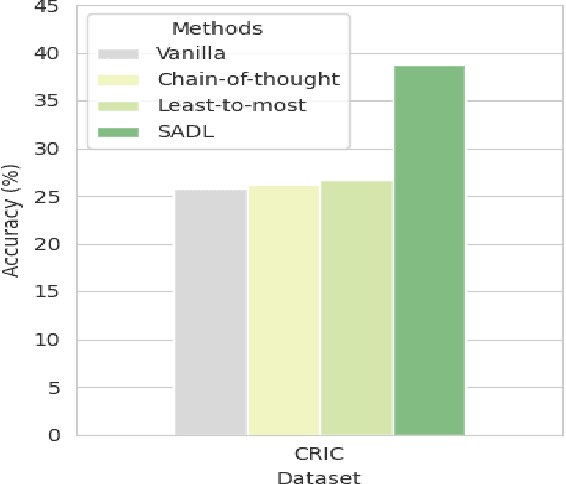
Large vision-language models (LVLMs) offer a novel capability for performing in-context learning (ICL) in Visual QA. When prompted with a few demonstrations of image-question-answer triplets, LVLMs have demonstrated the ability to discern underlying patterns and transfer this latent knowledge to answer new questions about unseen images without the need for expensive supervised fine-tuning. However, designing effective vision-language prompts, especially for compositional questions, remains poorly understood. Adapting language-only ICL techniques may not necessarily work because we need to bridge the visual-linguistic semantic gap: Symbolic concepts must be grounded in visual content, which does not share the syntactic linguistic structures. This paper introduces SADL, a new visual-linguistic prompting framework for the task. SADL revolves around three key components: SAmpling, Deliberation, and Pseudo-Labeling of image-question pairs. Given an image-question query, we sample image-question pairs from the training data that are in semantic proximity to the query. To address the compositional nature of questions, the deliberation step decomposes complex questions into a sequence of subquestions. Finally, the sequence is progressively annotated one subquestion at a time to generate a sequence of pseudo-labels. We investigate the behaviors of SADL under OpenFlamingo on large-scale Visual QA datasets, namely GQA, GQA-OOD, CLEVR, and CRIC. The evaluation demonstrates the critical roles of sampling in the neighborhood of the image, the decomposition of complex questions, and the accurate pairing of the subquestions and labels. These findings do not always align with those found in language-only ICL, suggesting fresh insights in vision-language settings.