 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Visual Question Answering with Attention Priors
Paper and Code
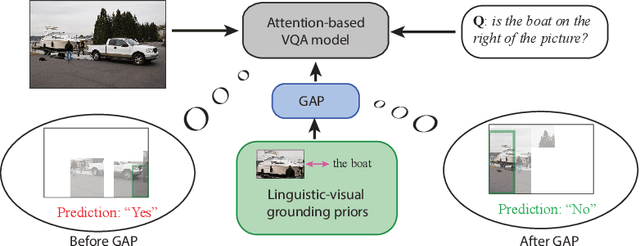
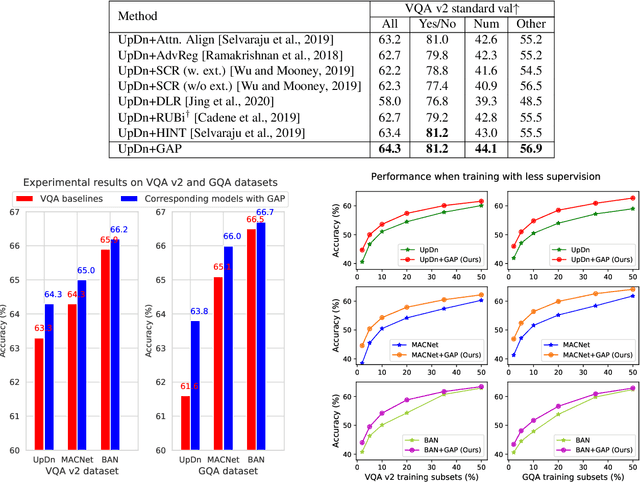
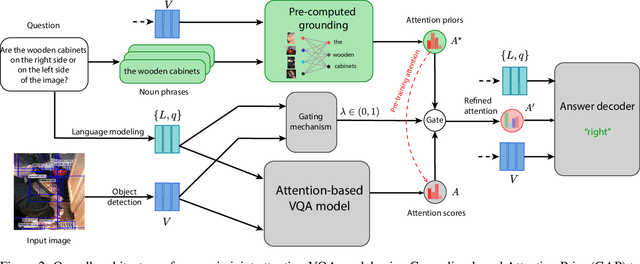

The current success of modern visual reasoning systems is arguably attributed to cross-modality attention mechanisms. However, in deliberative reasoning such as in VQA, attention is unconstrained at each step, and thus may serve as a statistical pooling mechanism rather than a semantic operation intended to select information relevant to inference. This is because at training time, attention is only guided by a very sparse signal (i.e. the answer label) at the end of the inference chain. This causes the cross-modality attention weights to deviate from the desired visual-language bindings. To rectify this deviation, we propose to guide the attention mechanism using explicit linguistic-visual grounding. This grounding is derived by connecting structured linguistic concepts in the query to their referents among the visual objects. Here we learn the grounding from the pairing of questions and images alone, without the need for answer annotation or external grounding supervision. This grounding guides the attention mechanism inside VQA models through a duality of mechanisms: pre-training attention weight calculation and directly guiding the weights at inference time on a case-by-case basis. The resultant algorithm is capable of probing attention-based reasoning models, injecting relevant associative knowledge, and regulating the core reasoning process. This scalable enhancement improves the performance of VQA models, fortifies their robustness to limited access to supervised data, and increases interpretability.