 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS2MoE: Robust Sparse Mixture of Experts via Stochastic Learning
Paper and Code
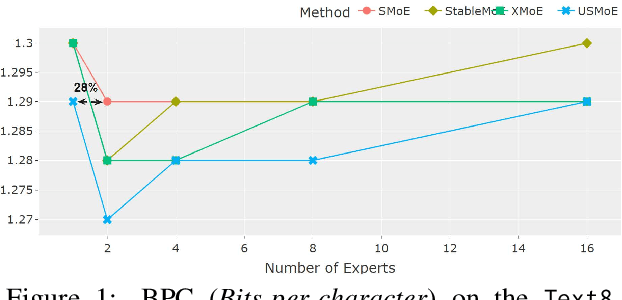
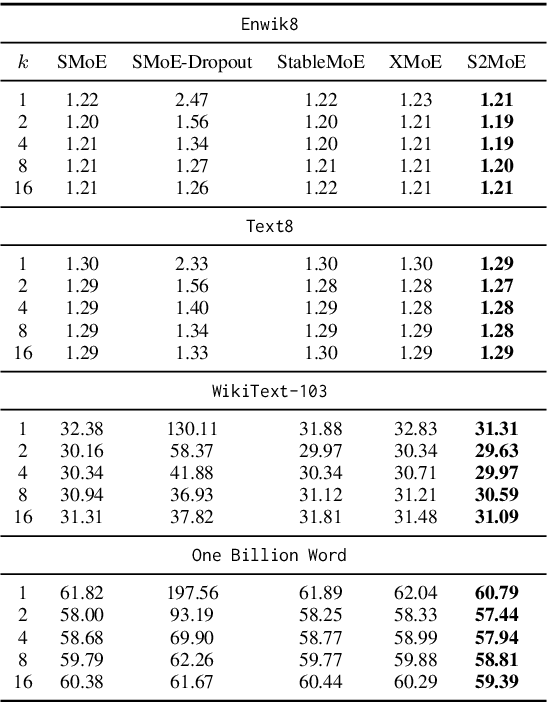
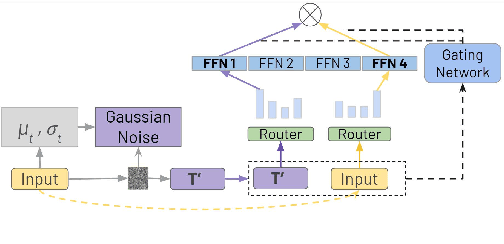
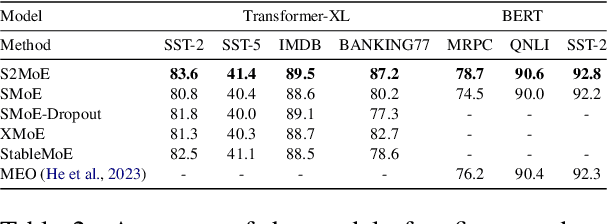
Sparse Mixture of Experts (SMoE) enables efficient training of large language models by routing input tokens to a select number of experts. However, training SMoE remains challenging due to the issue of representation collapse. Recent studies have focused on improving the router to mitigate this problem, but existing approaches face two key limitations: (1) expert embeddings are significantly smaller than the model's dimension, contributing to representation collapse, and (2) routing each input to the Top-K experts can cause them to learn overly similar features. In this work, we propose a novel approach called Robust Sparse Mixture of Experts via Stochastic Learning (S2MoE), which is a mixture of experts designed to learn from both deterministic and non-deterministic inputs via Learning under Uncertainty. Extensive experiments across various tasks demonstrate that S2MoE achieves performance comparable to other routing methods while reducing computational inference costs by 28%.