 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-graph Tuning-free GNN Prompting Framework
Apr 01, 2026GNN prompting aims to adapt models across tasks and graphs without requiring extensive retraining. However, most existing graph prompt methods still require task-specific parameter updates and face the issue of generalizing across graphs, limiting their performance and undermining the core promise of prompting. In this work, we introduce a Cross-graph Tuning-free Prompting Framework (CTP), which supports both homogeneous and heterogeneous graphs, can be directly deployed to unseen graphs without further parameter tuning, and thus enables a plug-and-play GNN inference engine. Extensive experiments on few-shot prediction tasks show that, compared to SOTAs, CTP achieves an average accuracy gain of 30.8% and a maximum gain of 54%, confirming its effectiveness and offering a new perspective on graph prompt learning.
Intellectual Property Protection for Deep Learning Model and Dataset Intelligence
Nov 07, 2024
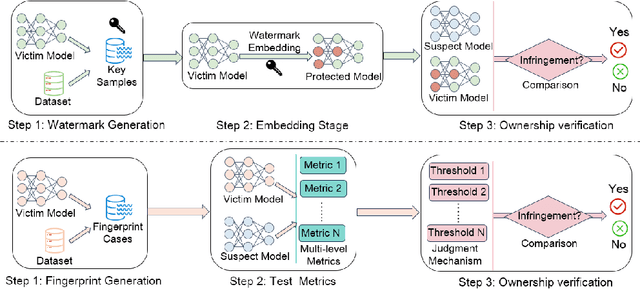


With the growing applications of Deep Learning (DL), especially recent spectacular achievements of Large Language Models (LLMs) such as ChatGPT and LLaMA, the commercial significance of these remarkable models has soared. However, acquiring well-trained models is costly and resource-intensive. It requires a considerable high-quality dataset, substantial investment in dedicated architecture design, expensive computational resources, and efforts to develop technical expertise. Consequently, safeguarding the Intellectual Property (IP) of well-trained models is attracting increasing attention. In contrast to existing surveys overwhelmingly focusing on model IPP mainly, this survey not only encompasses the protection on model level intelligence but also valuable dataset intelligence. Firstly, according to the requirements for effective IPP design, this work systematically summarizes the general and scheme-specific performance evaluation metrics. Secondly, from proactive IP infringement prevention and reactive IP ownership verification perspectives, it comprehensively investigates and analyzes the existing IPP methods for both dataset and model intelligence. Additionally, from the standpoint of training settings, it delves into the unique challenges that distributed settings pose to IPP compared to centralized settings. Furthermore, this work examines various attacks faced by deep IPP techniques. Finally, we outline prospects for promising future directions that may act as a guide for innovative research.
Defense Against Multi-target Trojan Attacks
Jul 08, 2022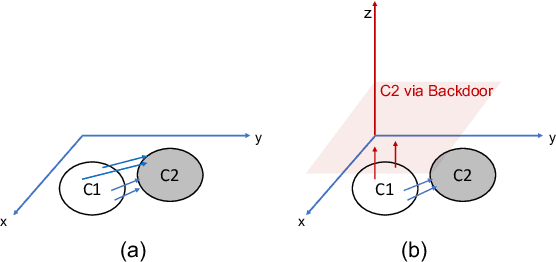
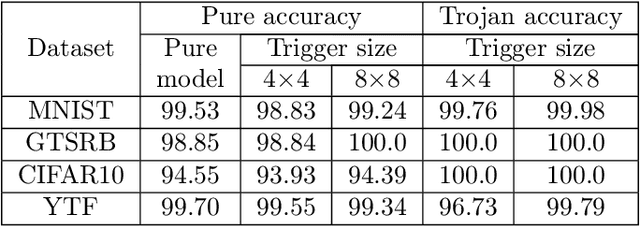
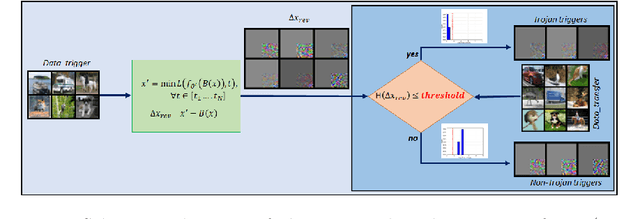

Adversarial attacks on deep learning-based models pose a significant threat to the current AI infrastructure. Among them, Trojan attacks are the hardest to defend against. In this paper, we first introduce a variation of the Badnet kind of attacks that introduces Trojan backdoors to multiple target classes and allows triggers to be placed anywhere in the image. The former makes it more potent and the latter makes it extremely easy to carry out the attack in the physical space. The state-of-the-art Trojan detection methods fail with this threat model. To defend against this attack, we first introduce a trigger reverse-engineering mechanism that uses multiple images to recover a variety of potential triggers. We then propose a detection mechanism by measuring the transferability of such recovered triggers. A Trojan trigger will have very high transferability i.e. they make other images also go to the same class. We study many practical advantages of our attack method and then demonstrate the detection performance using a variety of image datasets. The experimental results show the superior detection performance of our method over the state-of-the-arts.
CASSOCK: Viable Backdoor Attacks against DNN in The Wall of Source-Specific Backdoor Defences
May 31, 2022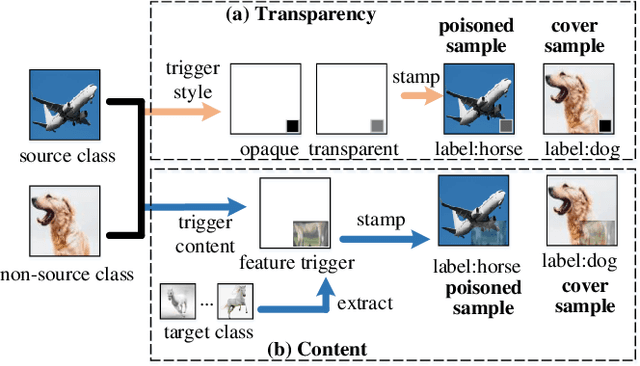

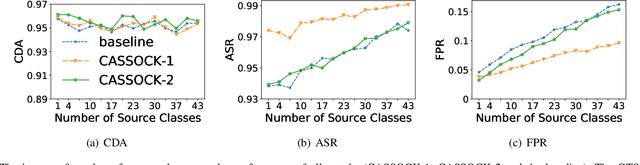
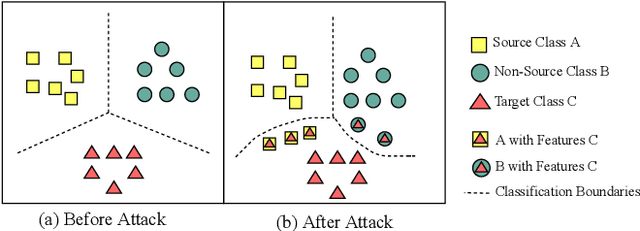
Backdoor attacks have been a critical threat to deep neural network (DNN). However, most existing countermeasures focus on source-agnostic backdoor attacks (SABAs) and fail to defeat source-specific backdoor attacks (SSBAs). Compared to an SABA, an SSBA activates a backdoor when an input from attacker-chosen class(es) is stamped with an attacker-specified trigger, making itself stealthier and thus evade most existing backdoor mitigation. Nonetheless, existing SSBAs have trade-offs on attack success rate (ASR, a backdoor is activated by a trigger input from a source class as expected) and false positive rate (FPR, a backdoor is activated unexpectedly by a trigger input from a non-source class). Significantly, they can still be effectively detected by the state-of-the-art (SOTA) countermeasures targeting SSBAs. This work overcomes efficiency and effectiveness deficiencies of existing SSBAs, thus bypassing the SOTA defences. The key insight is to construct desired poisoned and cover data during backdoor training by characterising SSBAs in-depth. Both data are samples with triggers: the cover/poisoned data from non-source/source class(es) holds ground-truth/target labels. Therefore, two cover/poisoned data enhancements are developed from trigger style and content, respectively, coined CASSOCK. First, we leverage trigger patterns with discrepant transparency to craft cover/poisoned data, enforcing triggers with heterogeneous sensitivity on different classes. The second enhancement chooses the target class features as triggers to craft these samples, entangling trigger features with the target class heavily. Compared with existing SSBAs, CASSOCK-based attacks have higher ASR and low FPR on four popular tasks: MNIST, CIFAR10, GTSRB, and LFW. More importantly, CASSOCK has effectively evaded three defences (SCAn, Februus and extended Neural Cleanse) already defeat existing SSBAs effectively.
Towards Effective and Robust Neural Trojan Defenses via Input Filtering
Mar 08, 2022


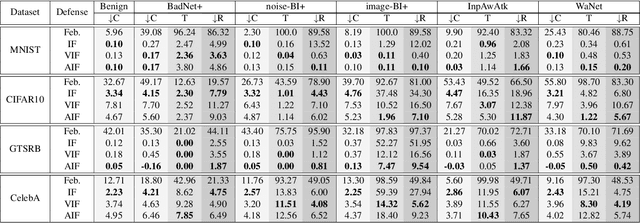
Trojan attacks on deep neural networks are both dangerous and surreptitious. Over the past few years, Trojan attacks have advanced from using only a single input-agnostic trigger and targeting only one class to using multiple, input-specific triggers and targeting multiple classes. However, Trojan defenses have not caught up with this development. Most defense methods still make out-of-date assumptions about Trojan triggers and target classes, thus, can be easily circumvented by modern Trojan attacks. To deal with this problem, we propose two novel "filtering" defenses called Variational Input Filtering (VIF) and Adversarial Input Filtering (AIF) which leverage lossy data compression and adversarial learning respectively to effectively purify all potential Trojan triggers in the input at run time without making assumptions about the number of triggers/target classes or the input dependence property of triggers. In addition, we introduce a new defense mechanism called "Filtering-then-Contrasting" (FtC) which helps avoid the drop in classification accuracy on clean data caused by "filtering", and combine it with VIF/AIF to derive new defenses of this kind. Extensive experimental results and ablation studies show that our proposed defenses significantly outperform well-known baseline defenses in mitigating five advanced Trojan attacks including two recent state-of-the-art while being quite robust to small amounts of training data and large-norm triggers.
ABG: A Multi-Party Mixed Protocol Framework for Privacy-Preserving Cooperative Learning
Feb 10, 2022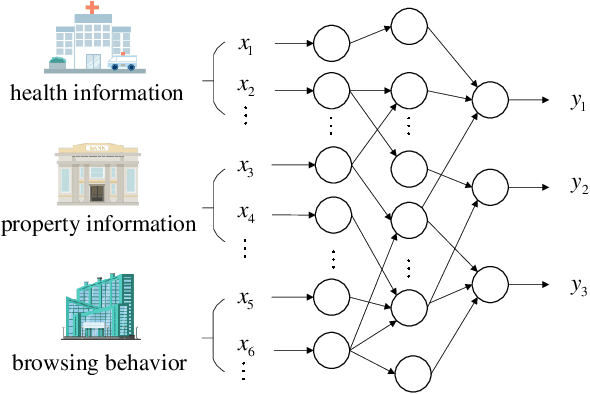



Cooperative learning, that enables two or more data owners to jointly train a model, has been widely adopted to solve the problem of insufficient training data in machine learning. Nowadays, there is an urgent need for institutions and organizations to train a model cooperatively while keeping each other's data privately. To address the issue of privacy-preserving in collaborative learning, secure outsourced computation and federated learning are two typical methods. Nevertheless, there are many drawbacks for these two methods when they are leveraged in cooperative learning. For secure outsourced computation, semi-honest servers need to be introduced. Once the outsourced servers collude or perform other active attacks, the privacy of data will be disclosed. For federated learning, it is difficult to apply to the scenarios where vertically partitioned data are distributed over multiple parties. In this work, we propose a multi-party mixed protocol framework, ABG$^n$, which effectively implements arbitrary conversion between Arithmetic sharing (A), Boolean sharing (B) and Garbled-Circuits sharing (G) for $n$-party scenarios. Based on ABG$^n$, we design a privacy-preserving multi-party cooperative learning system, which allows different data owners to cooperate in machine learning in terms of data security and privacy-preserving. Additionally, we design specific privacy-preserving computation protocols for some typical machine learning methods such as logistic regression and neural networks. Compared with previous work, the proposed method has a wider scope of application and does not need to rely on additional servers. Finally, we evaluate the performance of ABG$^n$ on the local setting and on the public cloud setting. The experiments indicate that ABG$^n$ has excellent performance, especially in the network environment with low latency.
Identifying Malicious Web Domains Using Machine Learning Techniques with Online Credibility and Performance Data
Feb 23, 2019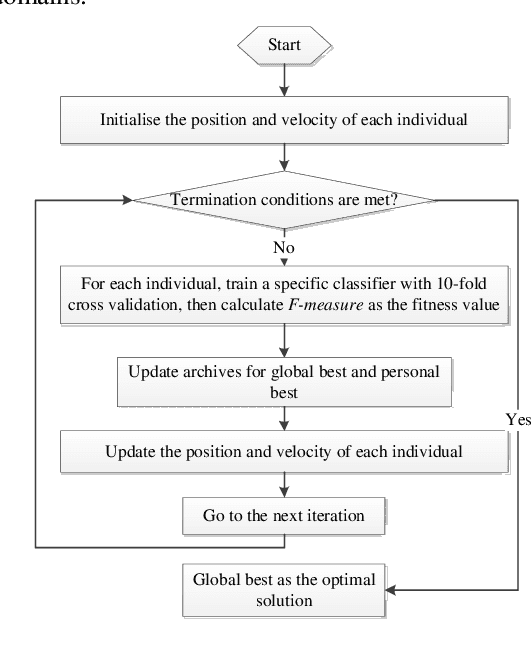
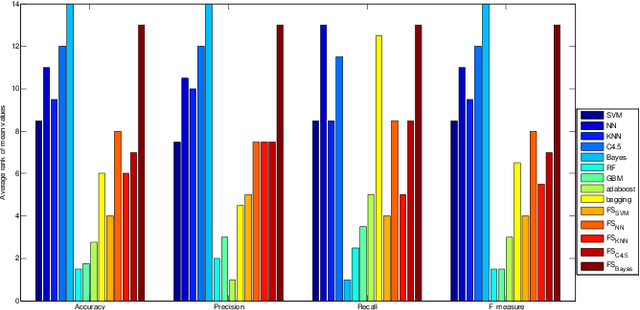
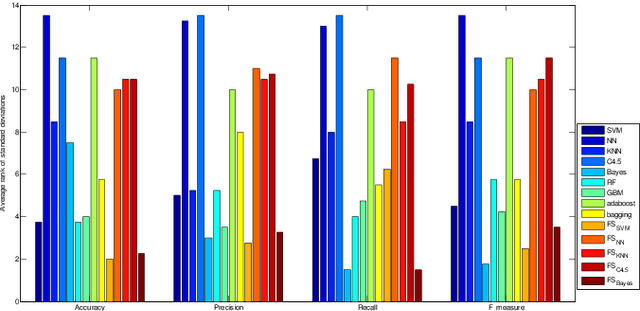

Malicious web domains represent a big threat to web users' privacy and security. With so much freely available data on the Internet about web domains' popularity and performance, this study investigated the performance of well-known machine learning techniques used in conjunction with this type of online data to identify malicious web domains. Two datasets consisting of malware and phishing domains were collected to build and evaluate the machine learning classifiers. Five single classifiers and four ensemble classifiers were applied to distinguish malicious domains from benign ones. In addition, a binary particle swarm optimisation (BPSO) based feature selection method was used to improve the performance of single classifiers. Experimental results show that, based on the web domains' popularity and performance data features, the examined machine learning techniques can accurately identify malicious domains in different ways. Furthermore, the BPSO-based feature selection procedure is shown to be an effective way to improve the performance of classifiers.
* 10 pages, conference