 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA fuzzy adaptive evolutionary-based feature selection and machine learning framework for single and multi-objective body fat prediction
Mar 20, 2023Predicting body fat can provide medical practitioners and users with essential information for preventing and diagnosing heart diseases. Hybrid machine learning models offer better performance than simple regression analysis methods by selecting relevant body measurements and capturing complex nonlinear relationships among selected features in modelling body fat prediction problems. There are, however, some disadvantages to them. Current machine learning. Modelling body fat prediction as a combinatorial single- and multi-objective optimisation problem often gets stuck in local optima. When multiple feature subsets produce similar or close predictions, avoiding local optima becomes more complex. Evolutionary feature selection has been used to solve several machine-learning-based optimisation problems. A fuzzy set theory determines appropriate levels of exploration and exploitation while managing parameterisation and computational costs. A weighted-sum body fat prediction approach was explored using evolutionary feature selection, fuzzy set theory, and machine learning algorithms, integrating contradictory metrics into a single composite goal optimised by fuzzy adaptive evolutionary feature selection. Hybrid fuzzy adaptive global learning local search universal diversity-based feature selection is applied to this single-objective feature selection-machine learning framework (FAGLSUD-based FS-ML). While using fewer features, this model achieved a more accurate and stable estimate of body fat percentage than other hybrid and state-of-the-art machine learning models. A multi-objective FAGLSUD-based FS-MLP is also proposed to analyse accuracy, stability, and dimensionality conflicts simultaneously. To make informed decisions about fat deposits in the most vital body parts and blood lipid levels, medical practitioners and users can use a well-distributed Pareto set of trade-off solutions.
A fuzzy adaptive metaheuristic algorithm for identifying sustainable, economical, lightweight, and earthquake-resistant reinforced concrete cantilever retaining walls
Feb 01, 2023



In earthquake-prone zones, the seismic performance of reinforced concrete cantilever (RCC) retaining walls is significant. In this study, the seismic performance was investigated using horizontal and vertical pseudo-static coefficients. To tackle RCC weights and forces resulting from these earth pressures, 26 constraints for structural strengths and geotechnical stability along with 12 geometric variables are associated with each design. These constraints and design variables form a constraint optimization problem with a twelve-dimensional solution space. To conduct effective search and produce sustainable, economical, lightweight RCC designs robust against earthquake hazards, a novel adaptive fuzzy-based metaheuristic algorithm is applied. The proposed method divides the search space to sub-regions and establishes exploration, information sharing, and exploitation search capabilities based on its novel search components. Further, fuzzy inference systems were employed to address parameterization and computational cost evaluation issues. It was found that the proposed algorithm can achieve low-cost, low-weight, and low CO2 emission RCC designs under nine seismic conditions in comparison with several classical and best-performing design optimizers.
Identifying Malicious Web Domains Using Machine Learning Techniques with Online Credibility and Performance Data
Feb 23, 2019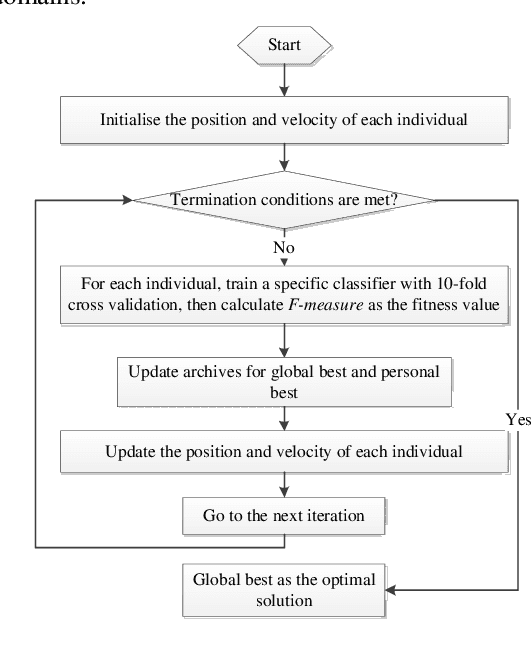

Malicious web domains represent a big threat to web users' privacy and security. With so much freely available data on the Internet about web domains' popularity and performance, this study investigated the performance of well-known machine learning techniques used in conjunction with this type of online data to identify malicious web domains. Two datasets consisting of malware and phishing domains were collected to build and evaluate the machine learning classifiers. Five single classifiers and four ensemble classifiers were applied to distinguish malicious domains from benign ones. In addition, a binary particle swarm optimisation (BPSO) based feature selection method was used to improve the performance of single classifiers. Experimental results show that, based on the web domains' popularity and performance data features, the examined machine learning techniques can accurately identify malicious domains in different ways. Furthermore, the BPSO-based feature selection procedure is shown to be an effective way to improve the performance of classifiers.
* 10 pages, conference
Deep Learning for Human Affect Recognition: Insights and New Developments
Jan 09, 2019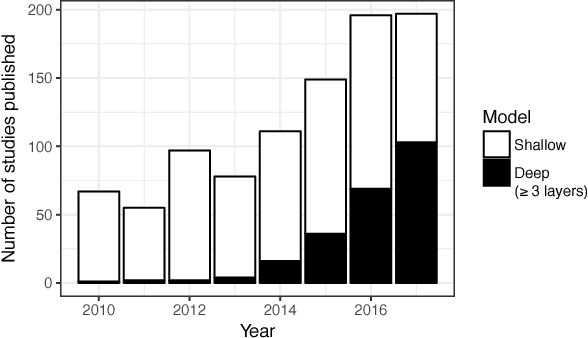
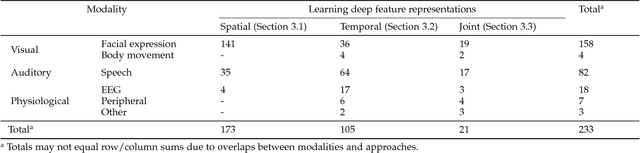
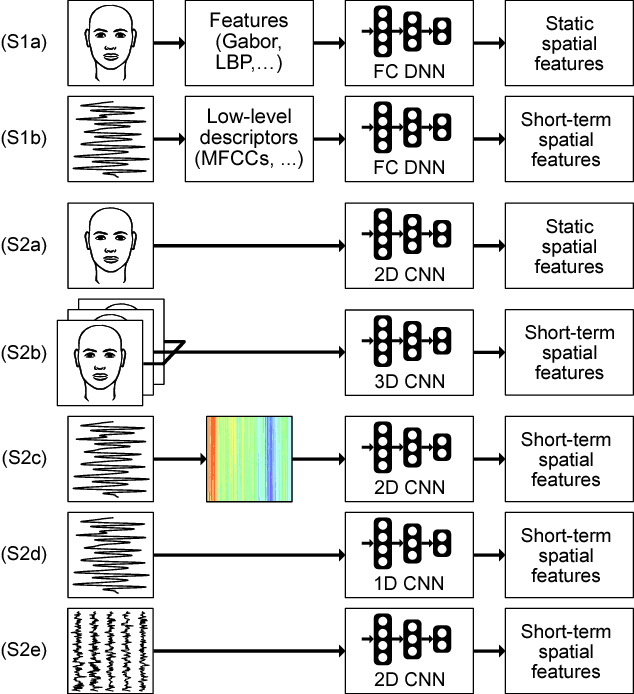
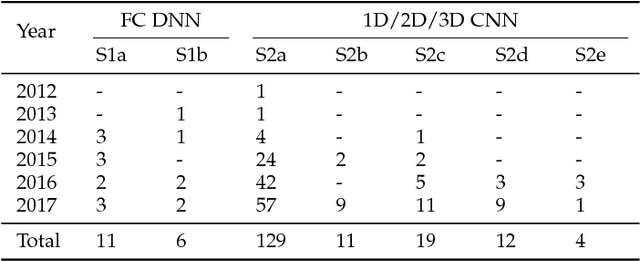
Automatic human affect recognition is a key step towards more natural human-computer interaction. Recent trends include recognition in the wild using a fusion of audiovisual and physiological sensors, a challenging setting for conventional machine learning algorithms. Since 2010, novel deep learning algorithms have been applied increasingly in this field. In this paper, we review the literature on human affect recognition between 2010 and 2017, with a special focus on approaches using deep neural networks. By classifying a total of 950 studies according to their usage of shallow or deep architectures, we are able to show a trend towards deep learning. Reviewing a subset of 233 studies that employ deep neural networks, we comprehensively quantify their applications in this field. We find that deep learning is used for learning of (i) spatial feature representations, (ii) temporal feature representations, and (iii) joint feature representations for multimodal sensor data. Exemplary state-of-the-art architectures illustrate the progress. Our findings show the role deep architectures will play in human affect recognition, and can serve as a reference point for researchers working on related applications.
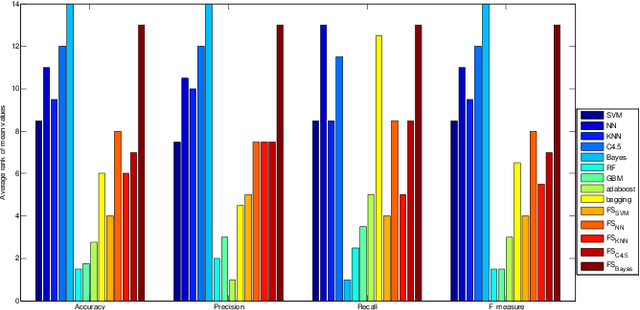
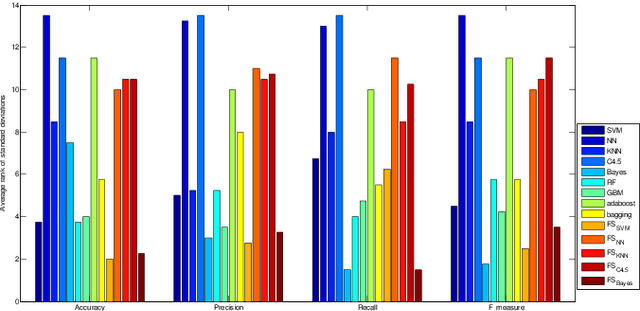
Malicious Web Domain Identification using Online Credibility and Performance Data by Considering the Class Imbalance Issue
Oct 19, 2018

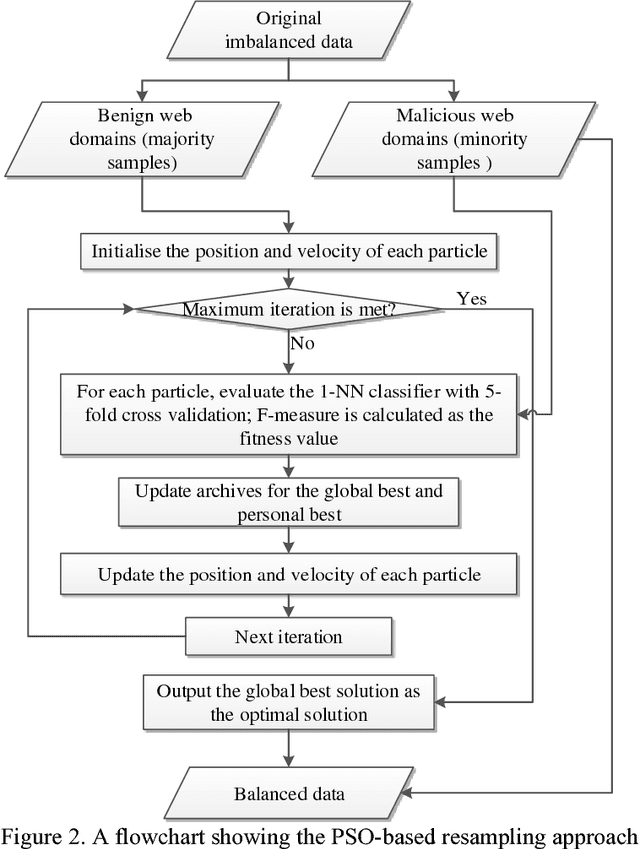
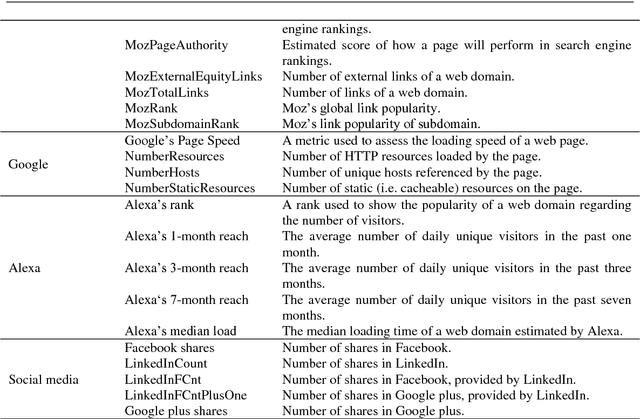
Purpose: Malicious web domain identification is of significant importance to the security protection of Internet users. With online credibility and performance data, this paper aims to investigate the use of machine learning tech-niques for malicious web domain identification by considering the class imbalance issue (i.e., there are more benign web domains than malicious ones). Design/methodology/approach: We propose an integrated resampling approach to handle class imbalance by combining the Synthetic Minority Over-sampling TEchnique (SMOTE) and Particle Swarm Optimisation (PSO), a population-based meta-heuristic algorithm. We use the SMOTE for over-sampling and PSO for under-sampling. Findings: By applying eight well-known machine learning classifiers, the proposed integrated resampling approach is comprehensively examined using several imbalanced web domain datasets with different imbalance ratios. Com-pared to five other well-known resampling approaches, experimental results confirm that the proposed approach is highly effective. Practical implications: This study not only inspires the practical use of online credibility and performance data for identifying malicious web domains, but also provides an effective resampling approach for handling the class imbal-ance issue in the area of malicious web domain identification. Originality/value: Online credibility and performance data is applied to build malicious web domain identification models using machine learning techniques. An integrated resampling approach is proposed to address the class im-balance issue. The performance of the proposed approach is confirmed based on real-world datasets with different imbalance ratios.
* 20 pages