 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVitalLens 2.0: High-Fidelity rPPG for Heart Rate Variability Estimation from Face Video
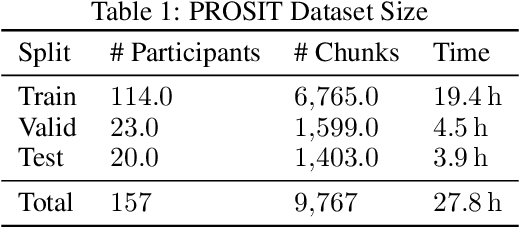
Oct 30, 2025This report introduces VitalLens 2.0, a new deep learning model for estimating physiological signals from face video. This new model demonstrates a significant leap in accuracy for remote photoplethysmography (rPPG), enabling the robust estimation of not only heart rate (HR) and respiratory rate (RR) but also Heart Rate Variability (HRV) metrics. This advance is achieved through a combination of a new model architecture and a substantial increase in the size and diversity of our training data, now totaling 1,413 unique individuals. We evaluate VitalLens 2.0 on a new, combined test set of 422 unique individuals from four public and private datasets. When averaging results by individual, VitalLens 2.0 achieves a Mean Absolute Error (MAE) of 1.57 bpm for HR, 1.08 bpm for RR, 10.18 ms for HRV-SDNN, and 16.45 ms for HRV-RMSSD. These results represent a new state-of-the-art, significantly outperforming previous methods. This model is now available to developers via the VitalLens API at https://rouast.com/api.
VitalLens: Take A Vital Selfie
Jan 03, 2024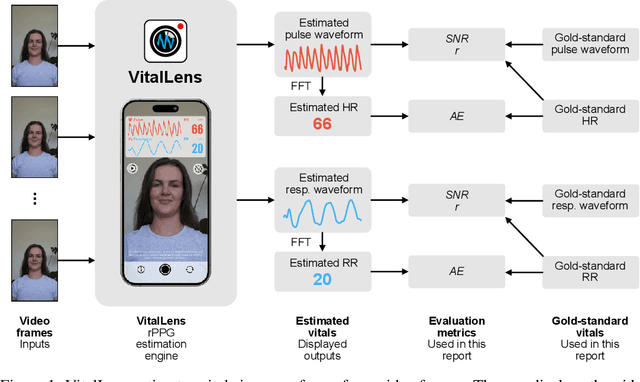


This report introduces VitalLens, an app that estimates vital signs such as heart rate and respiration rate from selfie video in real time. VitalLens uses a computer vision model trained on a diverse dataset of video and physiological sensor data. We benchmark performance on several diverse datasets, including VV-Medium, which consists of 289 unique participants. VitalLens outperforms several existing methods including POS and MTTS-CAN on all datasets while maintaining a fast inference speed. On VV-Medium, VitalLens achieves mean absolute errors of 0.71 bpm for heart rate estimation, and 0.76 bpm for respiratory rate estimation.
OREBA: A Dataset for Objectively Recognizing Eating Behaviour and Associated Intake
Aug 20, 2020



Automatic detection of intake gestures is a key element of automatic dietary monitoring. Several types of sensors, including inertial measurement units (IMU) and video cameras, have been used for this purpose. The common machine learning approaches make use of the labeled sensor data to automatically learn how to make detections. One characteristic, especially for deep learning models, is the need for large datasets. To meet this need, we collected the Objectively Recognizing Eating Behavior and Associated Intake (OREBA) dataset. The OREBA dataset aims to provide a comprehensive multi-sensor recording of communal intake occasions for researchers interested in intake gesture detection. Two scenarios are included, with 100 participants for a discrete dish and 102 participants for a shared dish, totalling 9069 intake gestures. Available sensor data consists of synchronized frontal video and IMU with accelerometer and gyroscope for both hands. We report the details of data collection and annotation, as well as details of sensor processing. The results of studies on IMU and video data involving deep learning models are reported to provide a baseline for future research. Specifically, the best baseline models achieve performances of $F_1$ = 0.853 for the discrete dish using video and $F_1$ = 0.852 for the shared dish using inertial data.
Single-stage intake gesture detection using CTC loss and extended prefix beam search
Aug 07, 2020


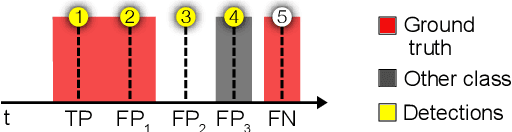
Accurate detection of individual intake gestures is a key step towards automatic dietary monitoring. Both inertial sensor data of wrist movements and video data depicting the upper body have been used for this purpose. The most advanced approaches to date use a two-stage approach, in which (i) frame-level intake probabilities are learned from the sensor data using a deep neural network, and then (ii) sparse intake events are detected by finding the maxima of the frame-level probabilities. In this study, we propose a single-stage approach which directly decodes the probabilities learned from sensor data into sparse intake detections. This is achieved by weakly supervised training using Connectionist Temporal Classification (CTC) loss, and decoding using a novel extended prefix beam search decoding algorithm. Benefits of this approach include (i) end-to-end training for detections, (ii) consistency with the fuzzy nature of intake gestures, and (iii) avoidance of hard-coded rules. Across two separate datasets, we quantify these benefits by showing relative $F_1$ score improvements between 2.0% and 6.2% over the two-stage approach for intake detection and eating vs. drinking recognition tasks, for both video and inertial sensors.
Learning deep representations for video-based intake gesture detection
Sep 24, 2019



Automatic detection of individual intake gestures during eating occasions has the potential to improve dietary monitoring and support dietary recommendations. Existing studies typically make use of on-body solutions such as inertial and audio sensors, while video is used as ground truth. Intake gesture detection directly based on video has rarely been attempted. In this study, we address this gap and show that deep learning architectures can successfully be applied to the problem of video-based detection of intake gestures. For this purpose, we collect and label video data of eating occasions using 360-degree video of 102 participants. Applying state-of-the-art approaches from video action recognition, our results show that (1) the best model achieves an $F_1$ score of 0.858, (2) appearance features contribute more than motion features, and (3) temporal context in form of multiple video frames is essential for top model performance.
Deep Learning for Human Affect Recognition: Insights and New Developments
Jan 09, 2019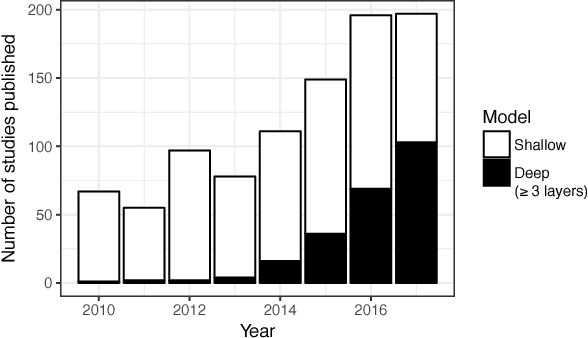
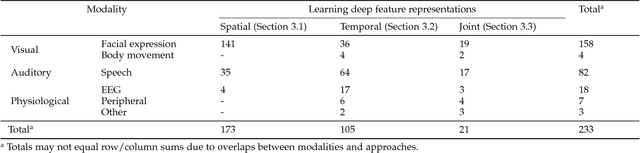
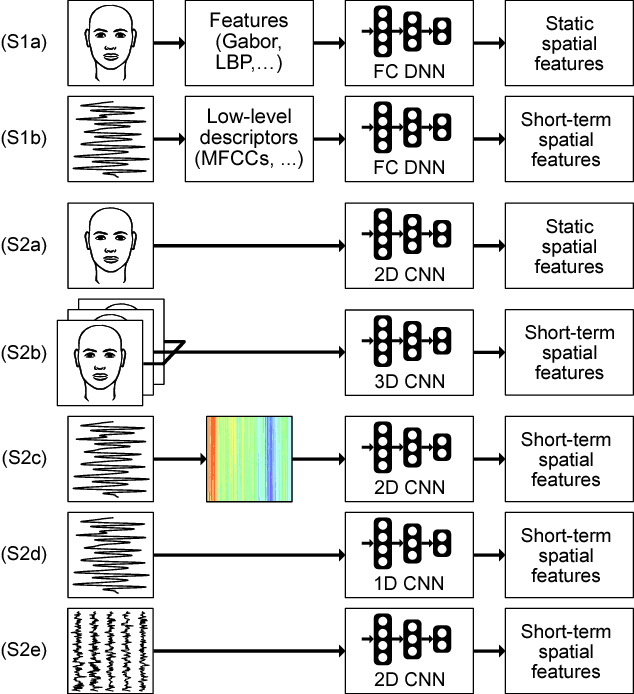
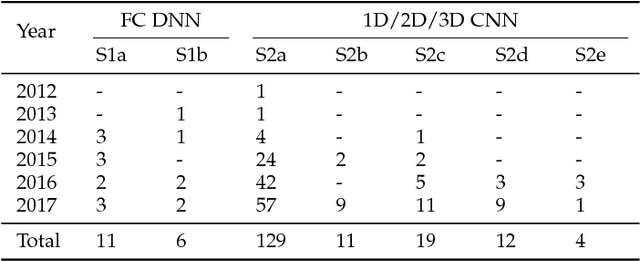
Automatic human affect recognition is a key step towards more natural human-computer interaction. Recent trends include recognition in the wild using a fusion of audiovisual and physiological sensors, a challenging setting for conventional machine learning algorithms. Since 2010, novel deep learning algorithms have been applied increasingly in this field. In this paper, we review the literature on human affect recognition between 2010 and 2017, with a special focus on approaches using deep neural networks. By classifying a total of 950 studies according to their usage of shallow or deep architectures, we are able to show a trend towards deep learning. Reviewing a subset of 233 studies that employ deep neural networks, we comprehensively quantify their applications in this field. We find that deep learning is used for learning of (i) spatial feature representations, (ii) temporal feature representations, and (iii) joint feature representations for multimodal sensor data. Exemplary state-of-the-art architectures illustrate the progress. Our findings show the role deep architectures will play in human affect recognition, and can serve as a reference point for researchers working on related applications.