 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-stage intake gesture detection using CTC loss and extended prefix beam search
Paper and Code



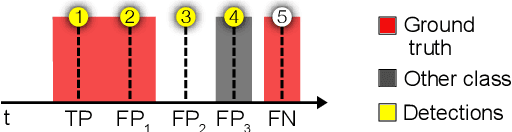
Accurate detection of individual intake gestures is a key step towards automatic dietary monitoring. Both inertial sensor data of wrist movements and video data depicting the upper body have been used for this purpose. The most advanced approaches to date use a two-stage approach, in which (i) frame-level intake probabilities are learned from the sensor data using a deep neural network, and then (ii) sparse intake events are detected by finding the maxima of the frame-level probabilities. In this study, we propose a single-stage approach which directly decodes the probabilities learned from sensor data into sparse intake detections. This is achieved by weakly supervised training using Connectionist Temporal Classification (CTC) loss, and decoding using a novel extended prefix beam search decoding algorithm. Benefits of this approach include (i) end-to-end training for detections, (ii) consistency with the fuzzy nature of intake gestures, and (iii) avoidance of hard-coded rules. Across two separate datasets, we quantify these benefits by showing relative $F_1$ score improvements between 2.0% and 6.2% over the two-stage approach for intake detection and eating vs. drinking recognition tasks, for both video and inertial sensors.