 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Malicious Web Domains Using Machine Learning Techniques with Online Credibility and Performance Data
Feb 23, 2019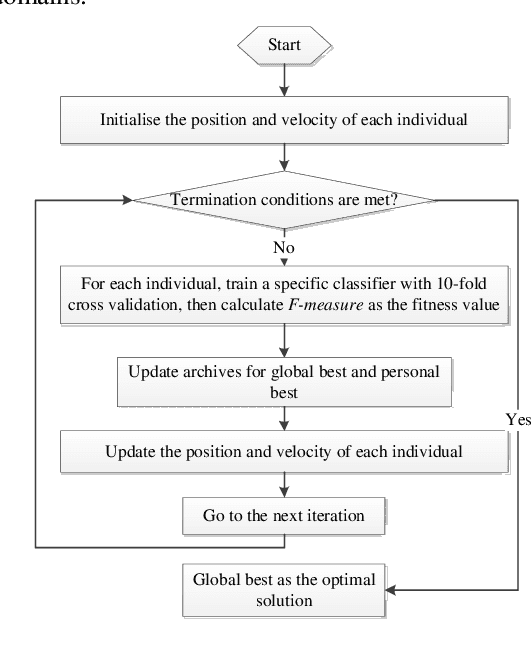

Malicious web domains represent a big threat to web users' privacy and security. With so much freely available data on the Internet about web domains' popularity and performance, this study investigated the performance of well-known machine learning techniques used in conjunction with this type of online data to identify malicious web domains. Two datasets consisting of malware and phishing domains were collected to build and evaluate the machine learning classifiers. Five single classifiers and four ensemble classifiers were applied to distinguish malicious domains from benign ones. In addition, a binary particle swarm optimisation (BPSO) based feature selection method was used to improve the performance of single classifiers. Experimental results show that, based on the web domains' popularity and performance data features, the examined machine learning techniques can accurately identify malicious domains in different ways. Furthermore, the BPSO-based feature selection procedure is shown to be an effective way to improve the performance of classifiers.
* 10 pages, conference
Malicious Web Domain Identification using Online Credibility and Performance Data by Considering the Class Imbalance Issue
Oct 19, 2018

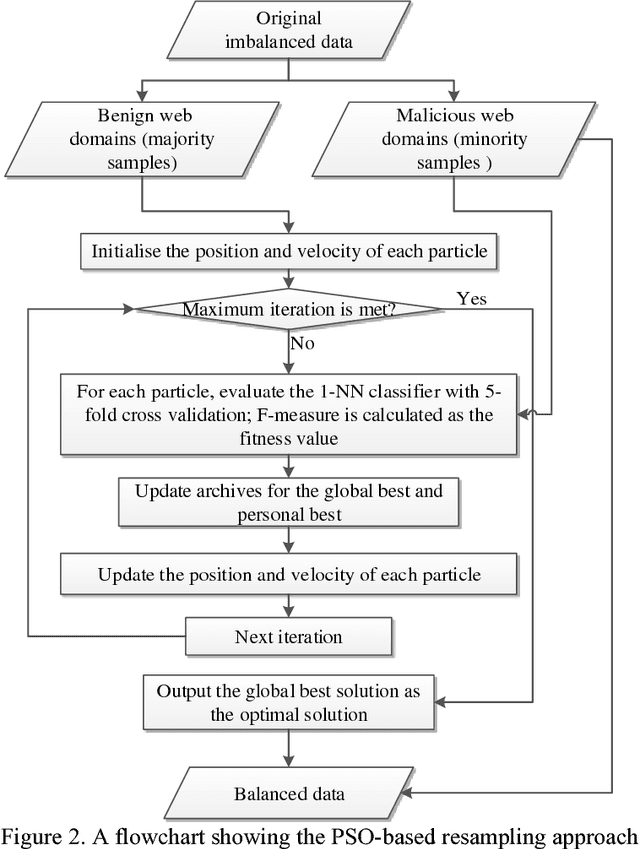
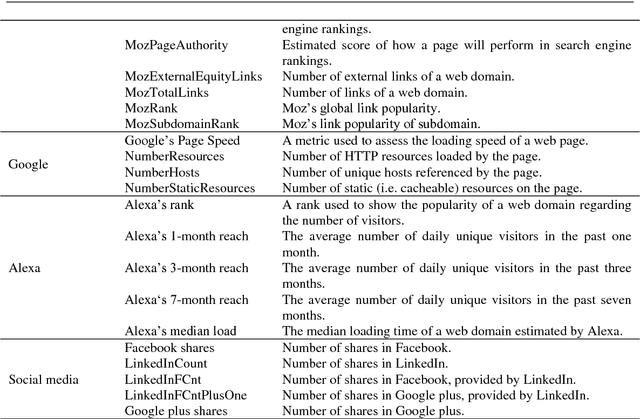
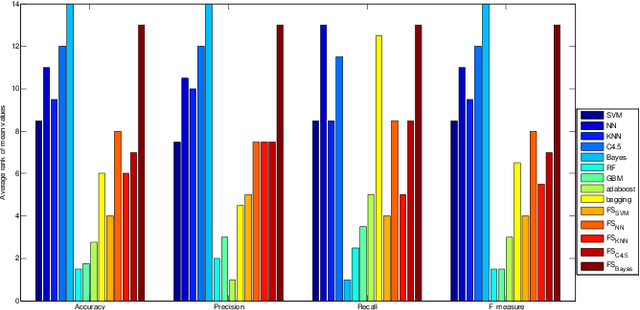
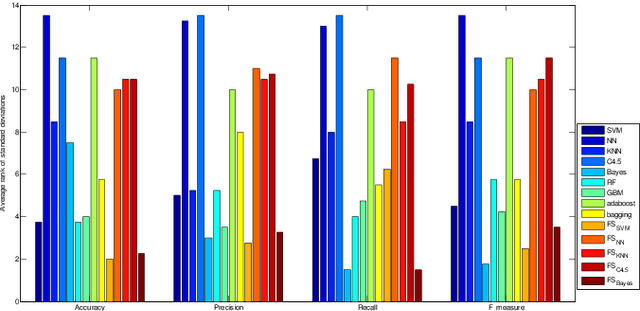
Purpose: Malicious web domain identification is of significant importance to the security protection of Internet users. With online credibility and performance data, this paper aims to investigate the use of machine learning tech-niques for malicious web domain identification by considering the class imbalance issue (i.e., there are more benign web domains than malicious ones). Design/methodology/approach: We propose an integrated resampling approach to handle class imbalance by combining the Synthetic Minority Over-sampling TEchnique (SMOTE) and Particle Swarm Optimisation (PSO), a population-based meta-heuristic algorithm. We use the SMOTE for over-sampling and PSO for under-sampling. Findings: By applying eight well-known machine learning classifiers, the proposed integrated resampling approach is comprehensively examined using several imbalanced web domain datasets with different imbalance ratios. Com-pared to five other well-known resampling approaches, experimental results confirm that the proposed approach is highly effective. Practical implications: This study not only inspires the practical use of online credibility and performance data for identifying malicious web domains, but also provides an effective resampling approach for handling the class imbal-ance issue in the area of malicious web domain identification. Originality/value: Online credibility and performance data is applied to build malicious web domain identification models using machine learning techniques. An integrated resampling approach is proposed to address the class im-balance issue. The performance of the proposed approach is confirmed based on real-world datasets with different imbalance ratios.
* 20 pages