 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Backdoor Detection in Neural Networks
Paper and Code
Jun 10, 2020
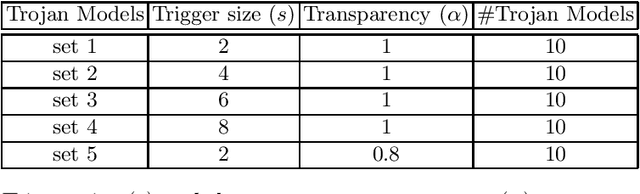


Recently, it has been shown that deep learning models are vulnerable to Trojan attacks, where an attacker can install a backdoor during training time to make the resultant model misidentify samples contaminated with a small trigger patch. Current backdoor detection methods fail to achieve good detection performance and are computationally expensive. In this paper, we propose a novel trigger reverse-engineering based approach whose computational complexity does not scale with the number of labels, and is based on a measure that is both interpretable and universal across different network and patch types. In experiments, we observe that our method achieves a perfect score in separating Trojaned models from pure models, which is an improvement over the current state-of-the art method.