 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing GPT to Enhance Text Summarization: A Strategy to Minimize Hallucinations
May 07, 2024In this research, we uses the DistilBERT model to generate extractive summary and the T5 model to generate abstractive summaries. Also, we generate hybrid summaries by combining both DistilBERT and T5 models. Central to our research is the implementation of GPT-based refining process to minimize the common problem of hallucinations that happens in AI-generated summaries. We evaluate unrefined summaries and, after refining, we also assess refined summaries using a range of traditional and novel metrics, demonstrating marked improvements in the accuracy and reliability of the summaries. Results highlight significant improvements in reducing hallucinatory content, thereby increasing the factual integrity of the summaries.
Evaluating Text Summaries Generated by Large Language Models Using OpenAI's GPT
May 07, 2024This research examines the effectiveness of OpenAI's GPT models as independent evaluators of text summaries generated by six transformer-based models from Hugging Face: DistilBART, BERT, ProphetNet, T5, BART, and PEGASUS. We evaluated these summaries based on essential properties of high-quality summary - conciseness, relevance, coherence, and readability - using traditional metrics such as ROUGE and Latent Semantic Analysis (LSA). Uniquely, we also employed GPT not as a summarizer but as an evaluator, allowing it to independently assess summary quality without predefined metrics. Our analysis revealed significant correlations between GPT evaluations and traditional metrics, particularly in assessing relevance and coherence. The results demonstrate GPT's potential as a robust tool for evaluating text summaries, offering insights that complement established metrics and providing a basis for comparative analysis of transformer-based models in natural language processing tasks.
Metric Ensembles For Hallucination Detection
Oct 16, 2023
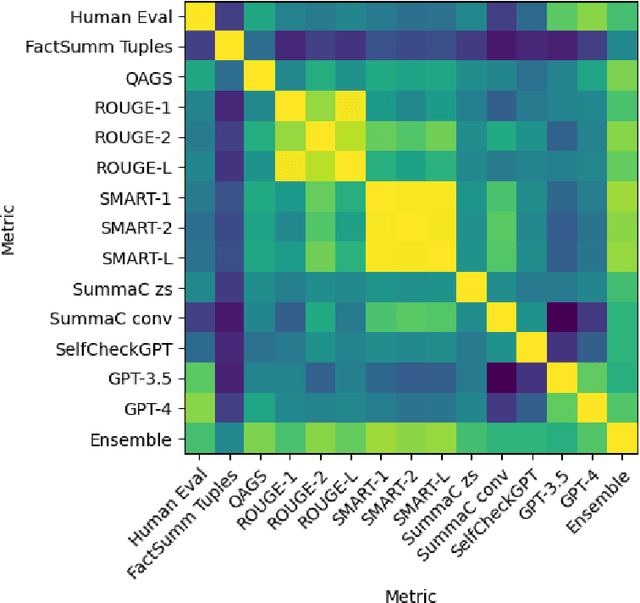

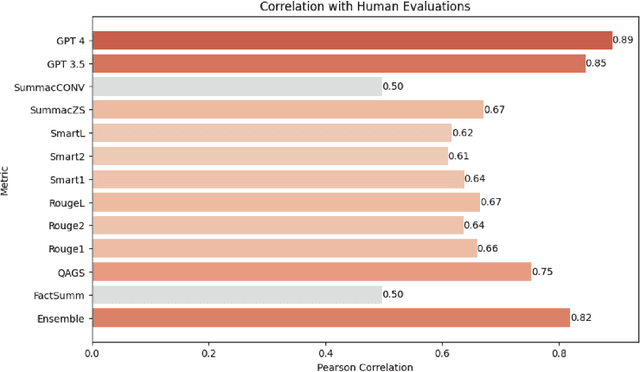
Abstractive text summarization has garnered increased interest as of late, in part due to the proliferation of large language models (LLMs). One of the most pressing problems related to generation of abstractive summaries is the need to reduce "hallucinations," information that was not included in the document being summarized, and which may be wholly incorrect. Due to this need, a wide array of metrics estimating consistency with the text being summarized have been proposed. We examine in particular a suite of unsupervised metrics for summary consistency, and measure their correlations with each other and with human evaluation scores in the wiki_bio_gpt3_hallucination dataset. We then compare these evaluations to models made from a simple linear ensemble of these metrics. We find that LLM-based methods outperform other unsupervised metrics for hallucination detection. We also find that ensemble methods can improve these scores even further, provided that the metrics in the ensemble have sufficiently similar and uncorrelated error rates. Finally, we present an ensemble method for LLM-based evaluations that we show improves over this previous SOTA.