 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOSBO: Conservative Offline Simulation-Based Policy Optimization
Sep 22, 2024



Offline reinforcement learning allows training reinforcement learning models on data from live deployments. However, it is limited to choosing the best combination of behaviors present in the training data. In contrast, simulation environments attempting to replicate the live environment can be used instead of the live data, yet this approach is limited by the simulation-to-reality gap, resulting in a bias. In an attempt to get the best of both worlds, we propose a method that combines an imperfect simulation environment with data from the target environment, to train an offline reinforcement learning policy. Our experiments demonstrate that the proposed method outperforms state-of-the-art approaches CQL, MOPO, and COMBO, especially in scenarios with diverse and challenging dynamics, and demonstrates robust behavior across a variety of experimental conditions. The results highlight that using simulator-generated data can effectively enhance offline policy learning despite the sim-to-real gap, when direct interaction with the real-world is not possible.
Learning Based High-Level Decision Making for Abortable Overtaking in Autonomous Vehicles
Jul 29, 2022

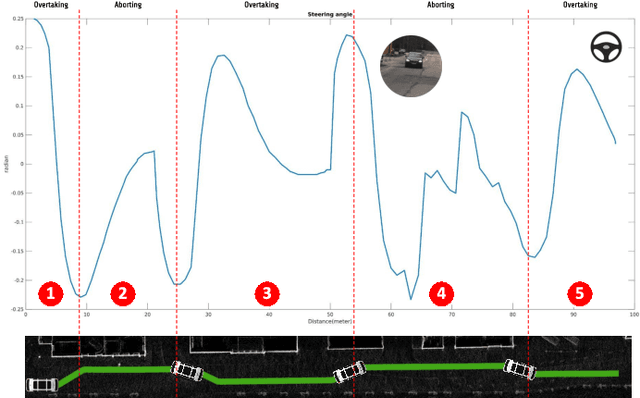
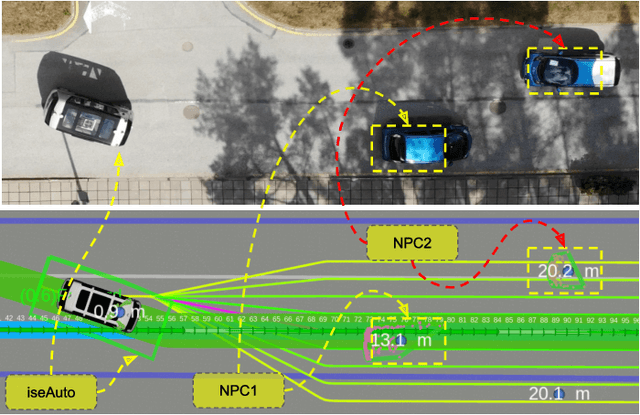
Autonomous vehicles are a growing technology that aims to enhance safety, accessibility, efficiency, and convenience through autonomous maneuvers ranging from lane change to overtaking. Overtaking is one of the most challenging maneuvers for autonomous vehicles, and current techniques for autonomous overtaking are limited to simple situations. This paper studies how to increase safety in autonomous overtaking by allowing the maneuver to be aborted. We propose a decision-making process based on a deep Q-Network to determine if and when the overtaking maneuver needs to be aborted. The proposed algorithm is empirically evaluated in simulation with varying traffic situations, indicating that the proposed method improves safety during overtaking maneuvers. Furthermore, the approach is demonstrated in real-world experiments using the autonomous shuttle iseAuto.
Vision Transformer for Learning Driving Policies in Complex Multi-Agent Environments
Sep 14, 2021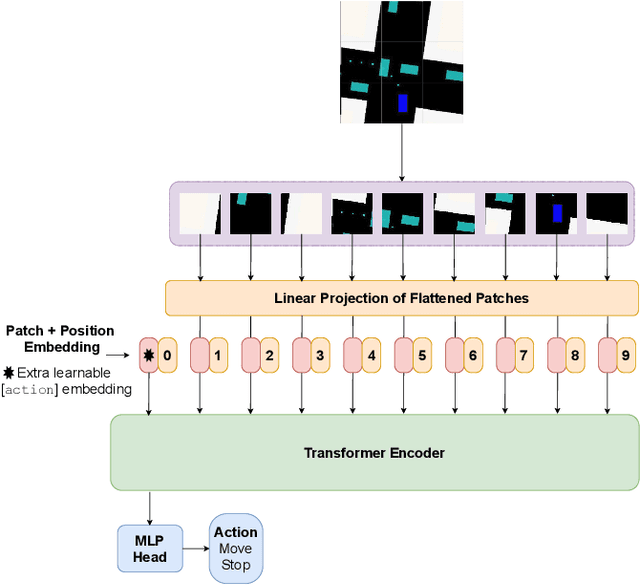
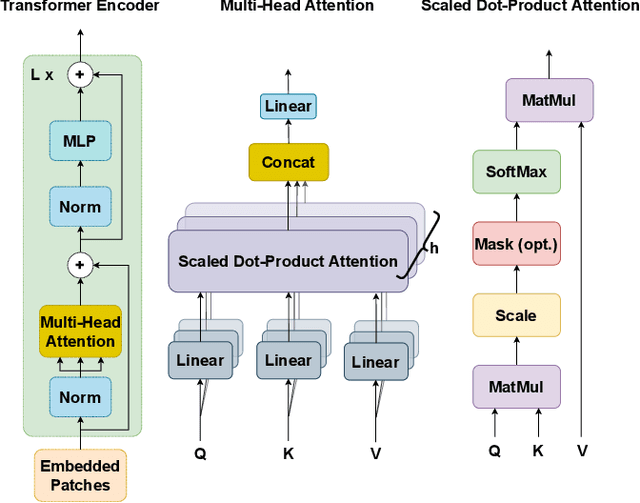
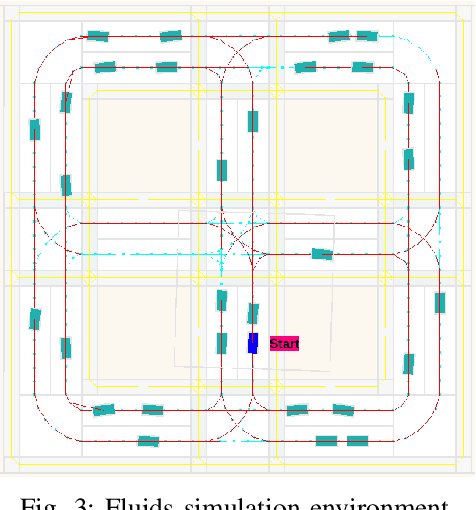
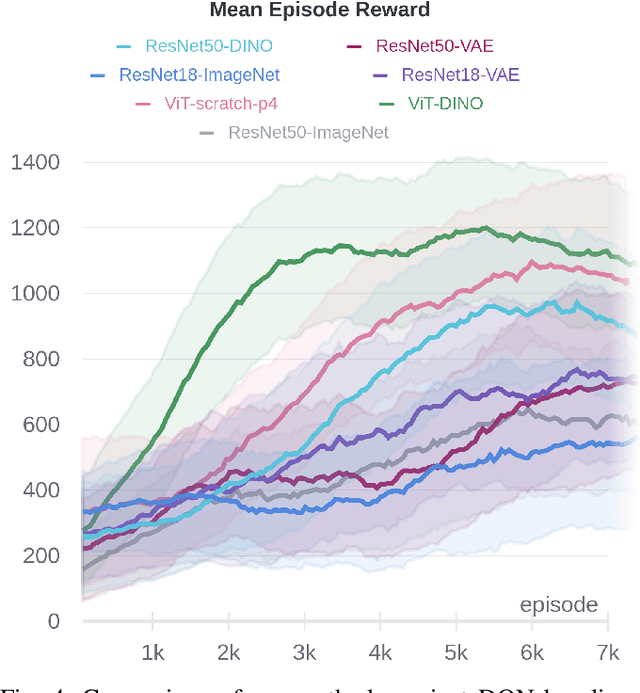
Driving in a complex urban environment is a difficult task that requires a complex decision policy. In order to make informed decisions, one needs to gain an understanding of the long-range context and the importance of other vehicles. In this work, we propose to use Vision Transformer (ViT) to learn a driving policy in urban settings with birds-eye-view (BEV) input images. The ViT network learns the global context of the scene more effectively than with earlier proposed Convolutional Neural Networks (ConvNets). Furthermore, ViT's attention mechanism helps to learn an attention map for the scene which allows the ego car to determine which surrounding cars are important to its next decision. We demonstrate that a DQN agent with a ViT backbone outperforms baseline algorithms with ConvNet backbones pre-trained in various ways. In particular, the proposed method helps reinforcement learning algorithms to learn faster, with increased performance and less data than baselines.
MACRPO: Multi-Agent Cooperative Recurrent Policy Optimization
Sep 02, 2021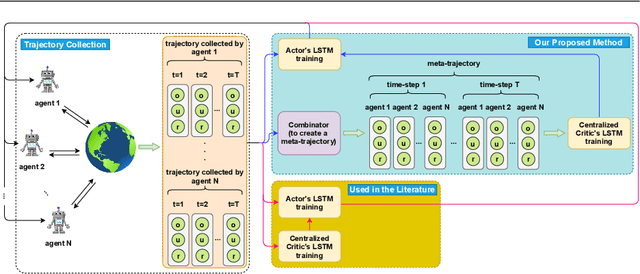
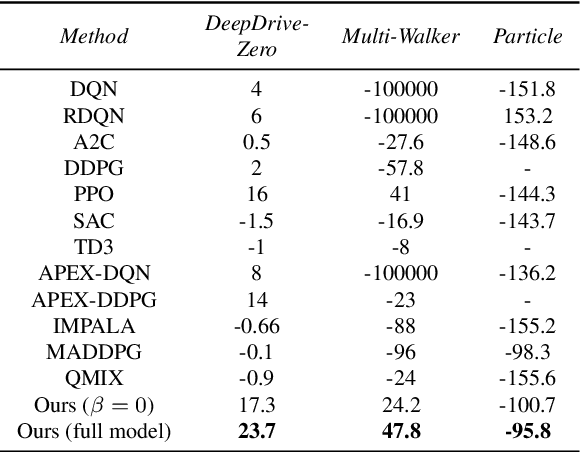
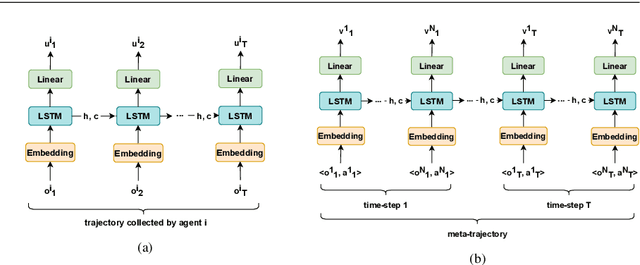

This work considers the problem of learning cooperative policies in multi-agent settings with partially observable and non-stationary environments without a communication channel. We focus on improving information sharing between agents and propose a new multi-agent actor-critic method called \textit{Multi-Agent Cooperative Recurrent Proximal Policy Optimization} (MACRPO). We propose two novel ways of integrating information across agents and time in MACRPO: First, we use a recurrent layer in critic's network architecture and propose a new framework to use a meta-trajectory to train the recurrent layer. This allows the network to learn the cooperation and dynamics of interactions between agents, and also handle partial observability. Second, we propose a new advantage function that incorporates other agents' rewards and value functions. We evaluate our algorithm on three challenging multi-agent environments with continuous and discrete action spaces, Deepdrive-Zero, Multi-Walker, and Particle environment. We compare the results with several ablations and state-of-the-art multi-agent algorithms such as QMIX and MADDPG and also single-agent methods with shared parameters between agents such as IMPALA and APEX. The results show superior performance against other algorithms. The code is available online at https://github.com/kargarisaac/macrpo.
Increasing the Efficiency of Policy Learning for Autonomous Vehicles by Multi-Task Representation Learning
Mar 26, 2021
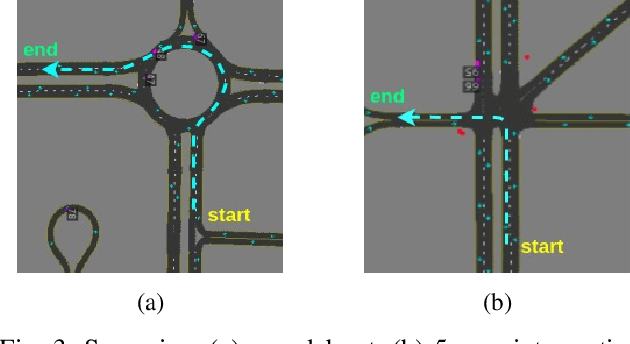
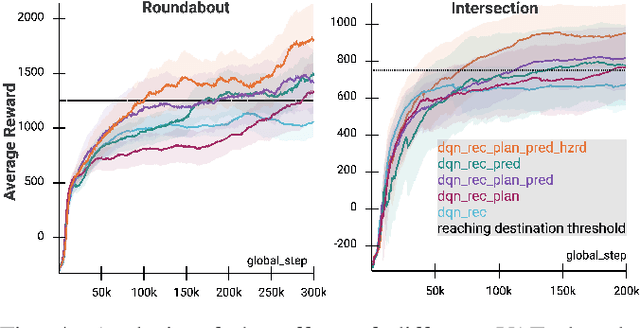
Driving in a dynamic, multi-agent, and complex urban environment is a difficult task requiring a complex decision-making policy. The learning of such a policy requires a state representation that can encode the entire environment. Mid-level representations that encode a vehicle's environment as images have become a popular choice. Still, they are quite high-dimensional, limiting their use in data-hungry approaches such as reinforcement learning. In this article, we propose to learn a low-dimensional and rich latent representation of the environment by leveraging the knowledge of relevant semantic factors. To do this, we train an encoder-decoder deep neural network to predict multiple application-relevant factors such as the trajectories of other agents and the ego car. We also propose a hazard signal in addition to the learned latent representation as input to a down-stream policy. We demonstrate that using the multi-head encoder-decoder neural network results in a more informative representation than a standard single-head model. In particular, the proposed representation learning and the hazard signal help reinforcement learning to learn faster, with increased performance and less data than baseline methods.
Efficient Latent Representations using Multiple Tasks for Autonomous Driving
Mar 02, 2020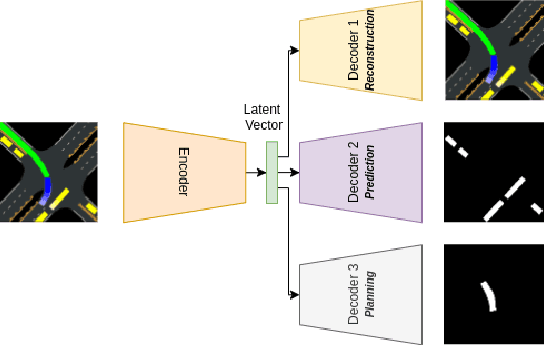


Driving in the dynamic, multi-agent, and complex urban environment is a difficult task requiring a complex decision policy. The learning of such a policy requires a state representation that can encode the entire environment. Mid-level representations that encode a vehicle's environment as images have become a popular choice, but they are quite high-dimensional, which limits their use in data-scarce cases such as reinforcement learning. In this article, we propose to learn a low dimensional and rich feature representation of the environment by training an encoder-decoder deep neural network to predict multiple application relevant factors such as trajectories of other agents. We demonstrate that the use of the multi-head encoder-decoder neural network results in a more informative representation compared to a single-head encoder-decoder model. In particular, the proposed representation learning approach helps the policy network to learn faster, with increased performance and with less data, compared to existing approaches using a single-head network.