 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Vision Transformer for Camera-LiDAR Fusion based Traffic Object Segmentation
Jan 06, 2025This paper presents Camera-LiDAR Fusion Transformer (CLFT) models for traffic object segmentation, which leverage the fusion of camera and LiDAR data using vision transformers. Building on the methodology of visual transformers that exploit the self-attention mechanism, we extend segmentation capabilities with additional classification options to a diverse class of objects including cyclists, traffic signs, and pedestrians across diverse weather conditions. Despite good performance, the models face challenges under adverse conditions which underscores the need for further optimization to enhance performance in darkness and rain. In summary, the CLFT models offer a compelling solution for autonomous driving perception, advancing the state-of-the-art in multimodal fusion and object segmentation, with ongoing efforts required to address existing limitations and fully harness their potential in practical deployments.
CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation in Autonomous Driving
Apr 27, 2024Critical research about camera-and-LiDAR-based semantic object segmentation for autonomous driving significantly benefited from the recent development of deep learning. Specifically, the vision transformer is the novel ground-breaker that successfully brought the multi-head-attention mechanism to computer vision applications. Therefore, we propose a vision-transformer-based network to carry out camera-LiDAR fusion for semantic segmentation applied to autonomous driving. Our proposal uses the novel progressive-assemble strategy of vision transformers on a double-direction network and then integrates the results in a cross-fusion strategy over the transformer decoder layers. Unlike other works in the literature, our camera-LiDAR fusion transformers have been evaluated in challenging conditions like rain and low illumination, showing robust performance. The paper reports the segmentation results over the vehicle and human classes in different modalities: camera-only, LiDAR-only, and camera-LiDAR fusion. We perform coherent controlled benchmark experiments of CLFT against other networks that are also designed for semantic segmentation. The experiments aim to evaluate the performance of CLFT independently from two perspectives: multimodal sensor fusion and backbone architectures. The quantitative assessments show our CLFT networks yield an improvement of up to 10\% for challenging dark-wet conditions when comparing with Fully-Convolutional-Neural-Network-based (FCN) camera-LiDAR fusion neural network. Contrasting to the network with transformer backbone but using single modality input, the all-around improvement is 5-10\%.
Learning Based High-Level Decision Making for Abortable Overtaking in Autonomous Vehicles
Jul 29, 2022

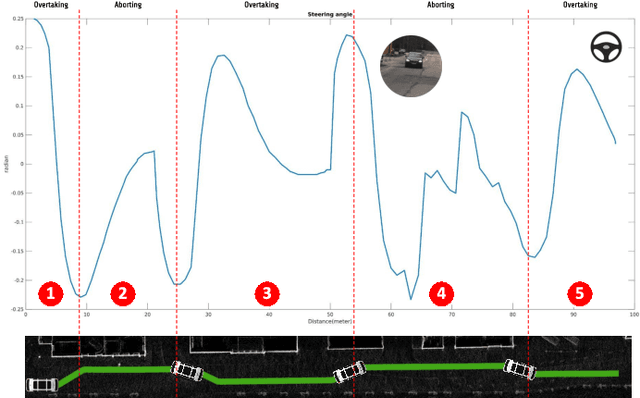
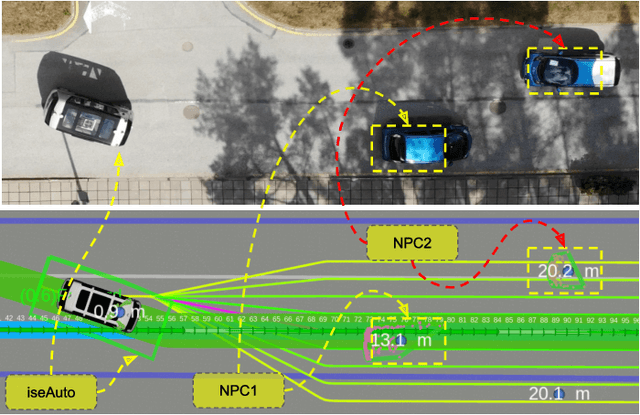
Autonomous vehicles are a growing technology that aims to enhance safety, accessibility, efficiency, and convenience through autonomous maneuvers ranging from lane change to overtaking. Overtaking is one of the most challenging maneuvers for autonomous vehicles, and current techniques for autonomous overtaking are limited to simple situations. This paper studies how to increase safety in autonomous overtaking by allowing the maneuver to be aborted. We propose a decision-making process based on a deep Q-Network to determine if and when the overtaking maneuver needs to be aborted. The proposed algorithm is empirically evaluated in simulation with varying traffic situations, indicating that the proposed method improves safety during overtaking maneuvers. Furthermore, the approach is demonstrated in real-world experiments using the autonomous shuttle iseAuto.