 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM-Enhanced Segmentation on Road Datasets: Balancing Critical Classes in Autonomous Driving
May 27, 2026Dense semantic segmentation is essential for autonomous driving, yet many multi-modal datasets lack pixel-level annotations. The Zenseact Open Dataset (ZOD) provides rich multi-sensor data but only bounding-box labels, limiting its use for segmentation research. Our primary contribution is a Segment Anything Model (SAM)-based annotation pipeline that produces dense, pixel-level annotations for ZOD by converting bounding boxes into semantic masks. In this pilot study, we process over 100,000 frames and manually curate a 2,300-frame subset (36% acceptance rate) to establish a reliable baseline. Using these annotations, we evaluate transformer-based CLFT and CNN-based DeepLabV3+ architectures across diverse weather conditions, achieving up to 48.1% mIoU with CLFT-Hybrid. To address extreme class imbalance, where pedestrians, cyclists, and signs constitute less than 1% of pixels, we explore specialized models targeting rare classes. We further validate the pipeline on the Iseauto autonomous-vehicle platform, achieving 77.5% mIoU, and show that SAM-derived representations transfer effectively across sensor configurations via bidirectional transfer learning. All code and annotations are released to support reproducible research.
A Novel Vision Transformer for Camera-LiDAR Fusion based Traffic Object Segmentation
Jan 06, 2025This paper presents Camera-LiDAR Fusion Transformer (CLFT) models for traffic object segmentation, which leverage the fusion of camera and LiDAR data using vision transformers. Building on the methodology of visual transformers that exploit the self-attention mechanism, we extend segmentation capabilities with additional classification options to a diverse class of objects including cyclists, traffic signs, and pedestrians across diverse weather conditions. Despite good performance, the models face challenges under adverse conditions which underscores the need for further optimization to enhance performance in darkness and rain. In summary, the CLFT models offer a compelling solution for autonomous driving perception, advancing the state-of-the-art in multimodal fusion and object segmentation, with ongoing efforts required to address existing limitations and fully harness their potential in practical deployments.
CLFT: Camera-LiDAR Fusion Transformer for Semantic Segmentation in Autonomous Driving
Apr 27, 2024Critical research about camera-and-LiDAR-based semantic object segmentation for autonomous driving significantly benefited from the recent development of deep learning. Specifically, the vision transformer is the novel ground-breaker that successfully brought the multi-head-attention mechanism to computer vision applications. Therefore, we propose a vision-transformer-based network to carry out camera-LiDAR fusion for semantic segmentation applied to autonomous driving. Our proposal uses the novel progressive-assemble strategy of vision transformers on a double-direction network and then integrates the results in a cross-fusion strategy over the transformer decoder layers. Unlike other works in the literature, our camera-LiDAR fusion transformers have been evaluated in challenging conditions like rain and low illumination, showing robust performance. The paper reports the segmentation results over the vehicle and human classes in different modalities: camera-only, LiDAR-only, and camera-LiDAR fusion. We perform coherent controlled benchmark experiments of CLFT against other networks that are also designed for semantic segmentation. The experiments aim to evaluate the performance of CLFT independently from two perspectives: multimodal sensor fusion and backbone architectures. The quantitative assessments show our CLFT networks yield an improvement of up to 10\% for challenging dark-wet conditions when comparing with Fully-Convolutional-Neural-Network-based (FCN) camera-LiDAR fusion neural network. Contrasting to the network with transformer backbone but using single modality input, the all-around improvement is 5-10\%.
LIDAR-Camera Fusion for Road Detection Using Fully Convolutional Neural Networks
Sep 21, 2018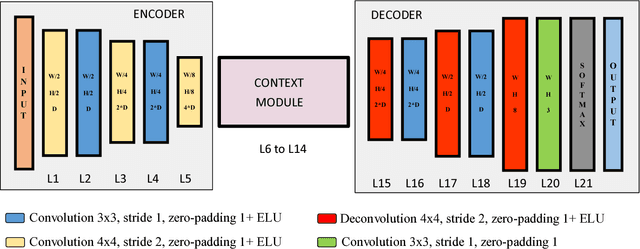
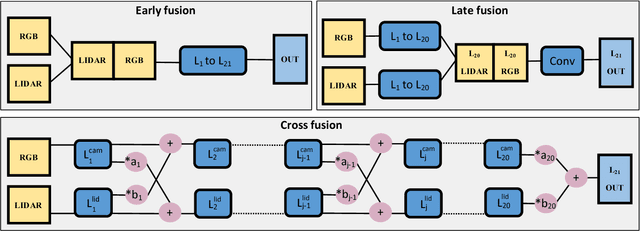


In this work, a deep learning approach has been developed to carry out road detection by fusing LIDAR point clouds and camera images. An unstructured and sparse point cloud is first projected onto the camera image plane and then upsampled to obtain a set of dense 2D images encoding spatial information. Several fully convolutional neural networks (FCNs) are then trained to carry out road detection, either by using data from a single sensor, or by using three fusion strategies: early, late, and the newly proposed cross fusion. Whereas in the former two fusion approaches, the integration of multimodal information is carried out at a predefined depth level, the cross fusion FCN is designed to directly learn from data where to integrate information; this is accomplished by using trainable cross connections between the LIDAR and the camera processing branches. To further highlight the benefits of using a multimodal system for road detection, a data set consisting of visually challenging scenes was extracted from driving sequences of the KITTI raw data set. It was then demonstrated that, as expected, a purely camera-based FCN severely underperforms on this data set. A multimodal system, on the other hand, is still able to provide high accuracy. Finally, the proposed cross fusion FCN was evaluated on the KITTI road benchmark where it achieved excellent performance, with a MaxF score of 96.03%, ranking it among the top-performing approaches.
LIDAR-based Driving Path Generation Using Fully Convolutional Neural Networks
Apr 03, 2017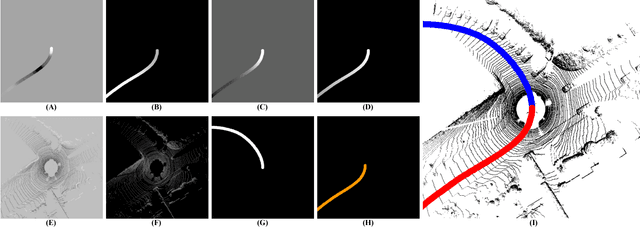
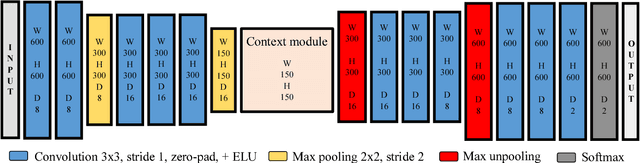
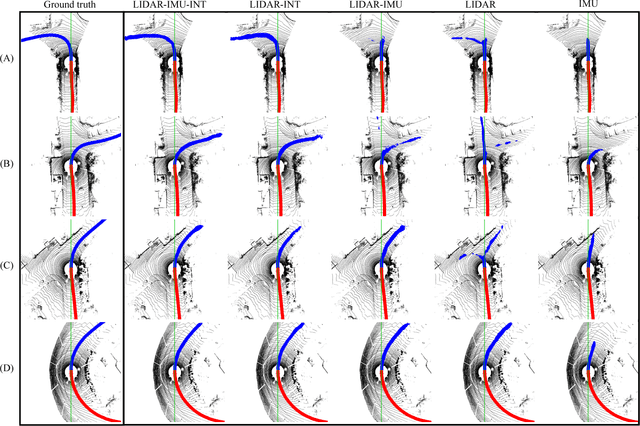
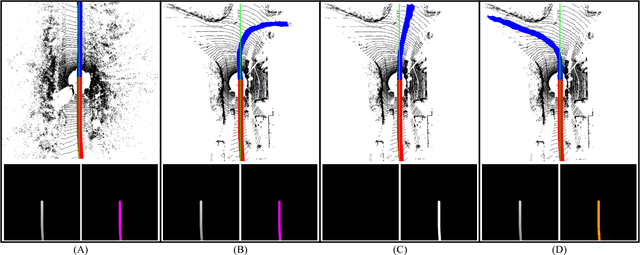
In this work, a novel learning-based approach has been developed to generate driving paths by integrating LIDAR point clouds, GPS-IMU information, and Google driving directions. The system is based on a fully convolutional neural network that jointly learns to carry out perception and path generation from real-world driving sequences and that is trained using automatically generated training examples. Several combinations of input data were tested in order to assess the performance gain provided by specific information modalities. The fully convolutional neural network trained using all the available sensors together with driving directions achieved the best MaxF score of 88.13% when considering a region of interest of 60x60 meters. By considering a smaller region of interest, the agreement between predicted paths and ground-truth increased to 92.60%. The positive results obtained in this work indicate that the proposed system may help fill the gap between low-level scene parsing and behavior-reflex approaches by generating outputs that are close to vehicle control and at the same time human-interpretable.