 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrawEduMath: Evaluating Vision Language Models with Expert-Annotated Students' Hand-Drawn Math Images
Jan 24, 2025



In real-world settings, vision language models (VLMs) should robustly handle naturalistic, noisy visual content as well as domain-specific language and concepts. For example, K-12 educators using digital learning platforms may need to examine and provide feedback across many images of students' math work. To assess the potential of VLMs to support educators in settings like this one, we introduce DrawEduMath, an English-language dataset of 2,030 images of students' handwritten responses to K-12 math problems. Teachers provided detailed annotations, including free-form descriptions of each image and 11,661 question-answer (QA) pairs. These annotations capture a wealth of pedagogical insights, ranging from students' problem-solving strategies to the composition of their drawings, diagrams, and writing. We evaluate VLMs on teachers' QA pairs, as well as 44,362 synthetic QA pairs derived from teachers' descriptions using language models (LMs). We show that even state-of-the-art VLMs leave much room for improvement on DrawEduMath questions. We also find that synthetic QAs, though imperfect, can yield similar model rankings as teacher-written QAs. We release DrawEduMath to support the evaluation of VLMs' abilities to reason mathematically over images gathered with educational contexts in mind.
Generative AI for Education (GAIED): Advances, Opportunities, and Challenges
Feb 07, 2024This survey article has grown out of the GAIED (pronounced "guide") workshop organized by the authors at the NeurIPS 2023 conference. We organized the GAIED workshop as part of a community-building effort to bring together researchers, educators, and practitioners to explore the potential of generative AI for enhancing education. This article aims to provide an overview of the workshop activities and highlight several future research directions in the area of GAIED.
Using Auxiliary Data to Boost Precision in the Analysis of A/B Tests on an Online Educational Platform: New Data and New Results
Jun 09, 2023Randomized A/B tests within online learning platforms represent an exciting direction in learning sciences. With minimal assumptions, they allow causal effect estimation without confounding bias and exact statistical inference even in small samples. However, often experimental samples and/or treatment effects are small, A/B tests are underpowered, and effect estimates are overly imprecise. Recent methodological advances have shown that power and statistical precision can be substantially boosted by coupling design-based causal estimation to machine-learning models of rich log data from historical users who were not in the experiment. Estimates using these techniques remain unbiased and inference remains exact without any additional assumptions. This paper reviews those methods and applies them to a new dataset including over 250 randomized A/B comparisons conducted within ASSISTments, an online learning platform. We compare results across experiments using four novel deep-learning models of auxiliary data and show that incorporating auxiliary data into causal estimates is roughly equivalent to increasing the sample size by 20\% on average, or as much as 50-80\% in some cases, relative to t-tests, and by about 10\% on average, or as much as 30-50\%, compared to cutting-edge machine learning unbiased estimates that use only data from the experiments. We show that the gains can be even larger for estimating subgroup effects, hold even when the remnant is unrepresentative of the A/B test sample, and extend to post-stratification population effects estimators.
Reinforcement Learning for Education: Opportunities and Challenges
Jul 15, 2021This survey article has grown out of the RL4ED workshop organized by the authors at the Educational Data Mining (EDM) 2021 conference. We organized this workshop as part of a community-building effort to bring together researchers and practitioners interested in the broad areas of reinforcement learning (RL) and education (ED). This article aims to provide an overview of the workshop activities and summarize the main research directions in the area of RL for ED.
The Utility of Clustering in Prediction Tasks
Sep 21, 2015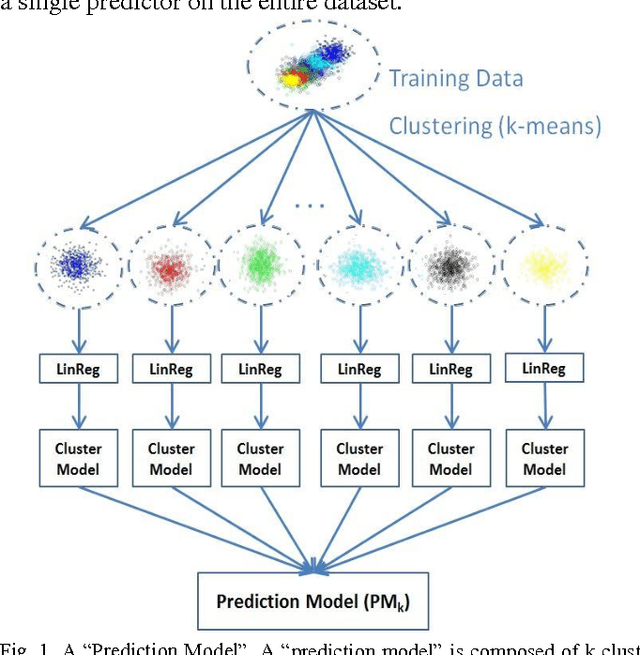
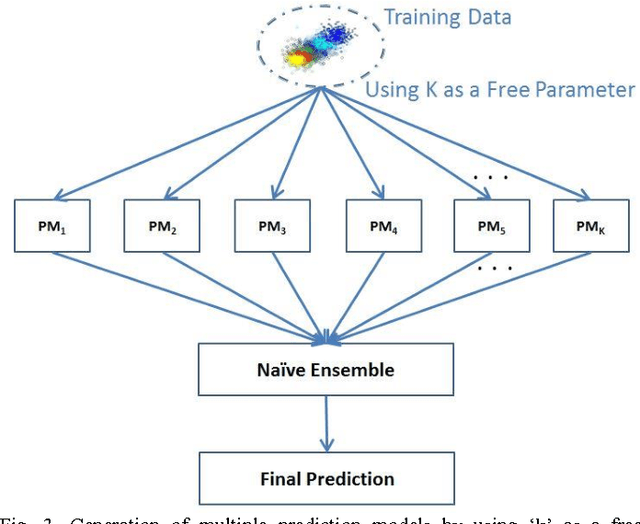
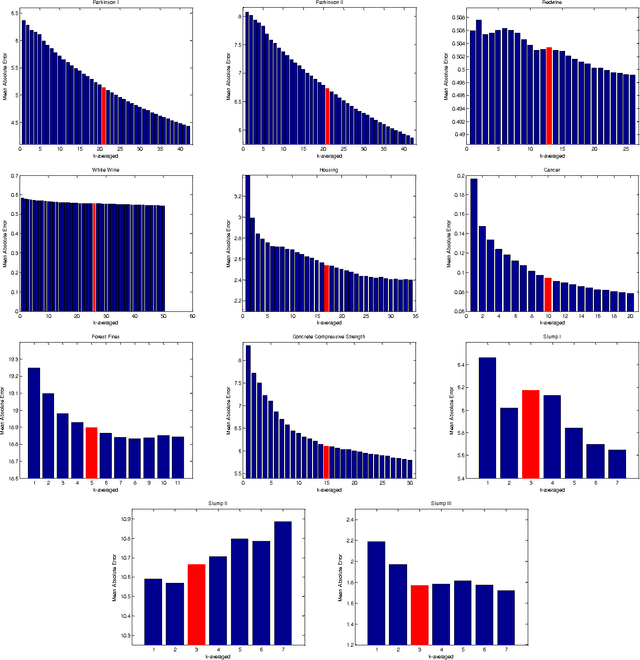
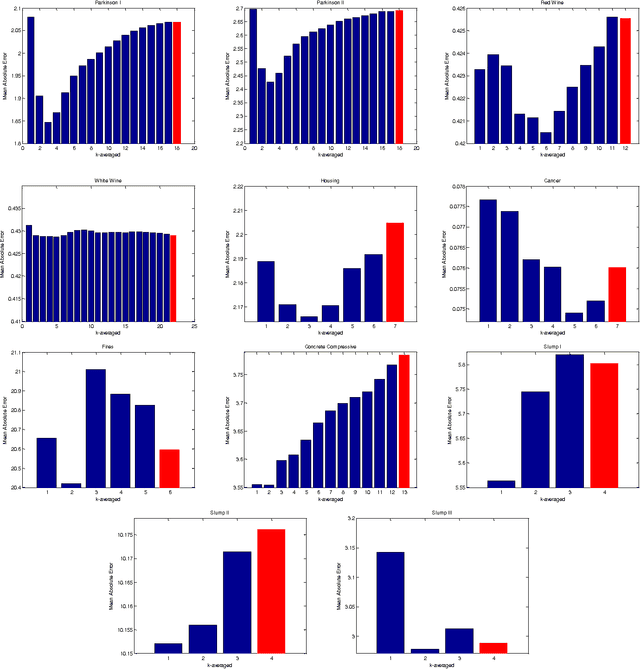
We explore the utility of clustering in reducing error in various prediction tasks. Previous work has hinted at the improvement in prediction accuracy attributed to clustering algorithms if used to pre-process the data. In this work we more deeply investigate the direct utility of using clustering to improve prediction accuracy and provide explanations for why this may be so. We look at a number of datasets, run k-means at different scales and for each scale we train predictors. This produces k sets of predictions. These predictions are then combined by a na\"ive ensemble. We observed that this use of a predictor in conjunction with clustering improved the prediction accuracy in most datasets. We believe this indicates the predictive utility of exploiting structure in the data and the data compression handed over by clustering. We also found that using this method improves upon the prediction of even a Random Forests predictor which suggests this method is providing a novel, and useful source of variance in the prediction process.