 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Explanations to Action: A Zero-Shot, Theory-Driven LLM Framework for Student Performance Feedback
Sep 12, 2024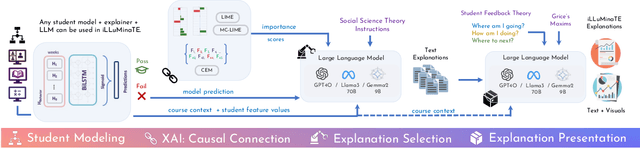
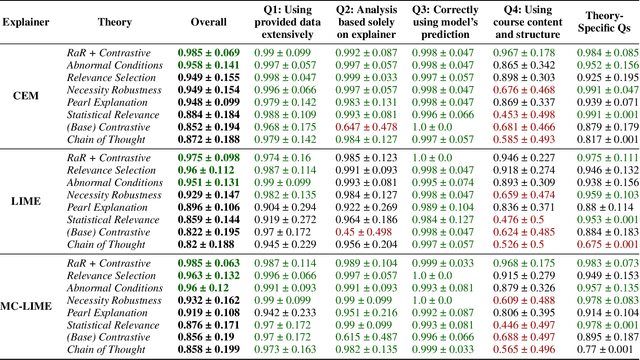
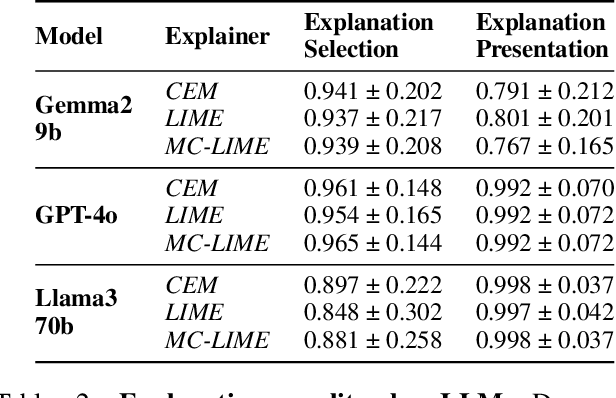
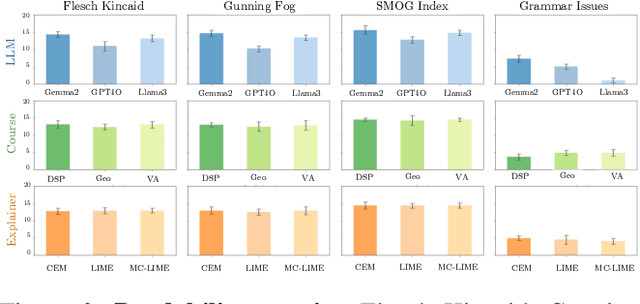
Recent advances in eXplainable AI (XAI) for education have highlighted a critical challenge: ensuring that explanations for state-of-the-art AI models are understandable for non-technical users such as educators and students. In response, we introduce iLLuMinaTE, a zero-shot, chain-of-prompts LLM-XAI pipeline inspired by Miller's cognitive model of explanation. iLLuMinaTE is designed to deliver theory-driven, actionable feedback to students in online courses. iLLuMinaTE navigates three main stages - causal connection, explanation selection, and explanation presentation - with variations drawing from eight social science theories (e.g. Abnormal Conditions, Pearl's Model of Explanation, Necessity and Robustness Selection, Contrastive Explanation). We extensively evaluate 21,915 natural language explanations of iLLuMinaTE extracted from three LLMs (GPT-4o, Gemma2-9B, Llama3-70B), with three different underlying XAI methods (LIME, Counterfactuals, MC-LIME), across students from three diverse online courses. Our evaluation involves analyses of explanation alignment to the social science theory, understandability of the explanation, and a real-world user preference study with 114 university students containing a novel actionability simulation. We find that students prefer iLLuMinaTE explanations over traditional explainers 89.52% of the time. Our work provides a robust, ready-to-use framework for effectively communicating hybrid XAI-driven insights in education, with significant generalization potential for other human-centric fields.
Divergences in Color Perception between Deep Neural Networks and Humans
Sep 11, 2023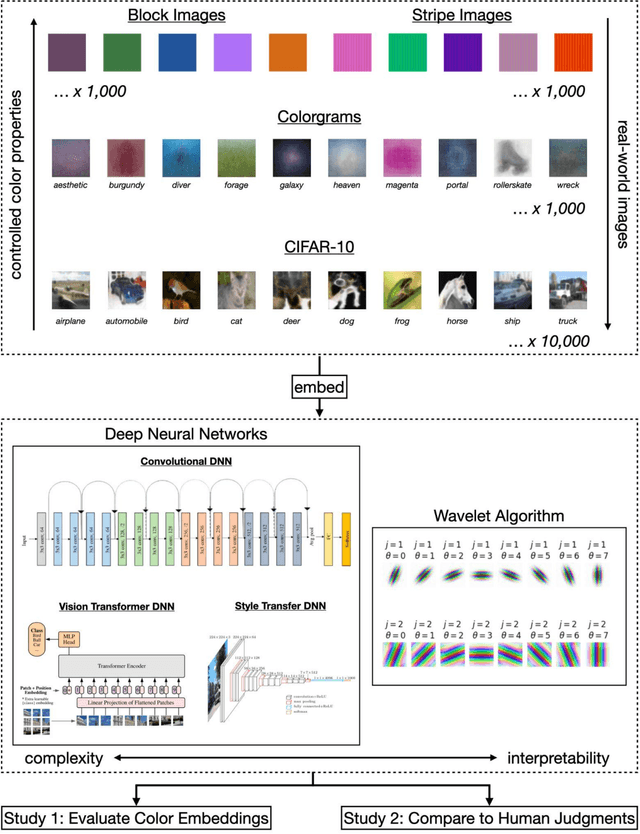

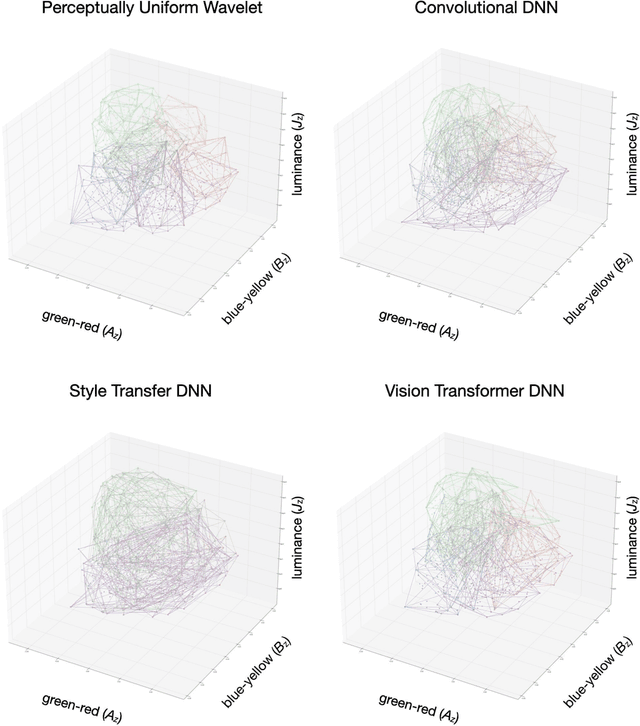
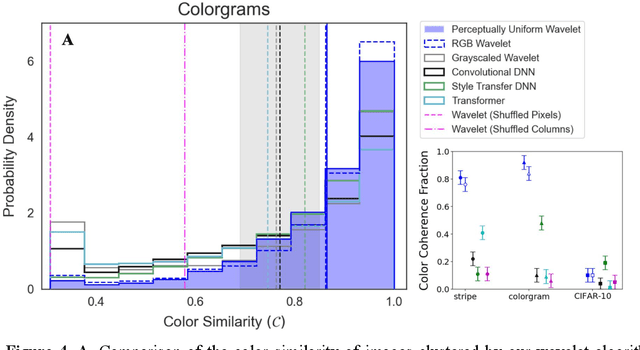
Deep neural networks (DNNs) are increasingly proposed as models of human vision, bolstered by their impressive performance on image classification and object recognition tasks. Yet, the extent to which DNNs capture fundamental aspects of human vision such as color perception remains unclear. Here, we develop novel experiments for evaluating the perceptual coherence of color embeddings in DNNs, and we assess how well these algorithms predict human color similarity judgments collected via an online survey. We find that state-of-the-art DNN architectures $-$ including convolutional neural networks and vision transformers $-$ provide color similarity judgments that strikingly diverge from human color judgments of (i) images with controlled color properties, (ii) images generated from online searches, and (iii) real-world images from the canonical CIFAR-10 dataset. We compare DNN performance against an interpretable and cognitively plausible model of color perception based on wavelet decomposition, inspired by foundational theories in computational neuroscience. While one deep learning model $-$ a convolutional DNN trained on a style transfer task $-$ captures some aspects of human color perception, our wavelet algorithm provides more coherent color embeddings that better predict human color judgments compared to all DNNs we examine. These results hold when altering the high-level visual task used to train similar DNN architectures (e.g., image classification versus image segmentation), as well as when examining the color embeddings of different layers in a given DNN architecture. These findings break new ground in the effort to analyze the perceptual representations of machine learning algorithms and to improve their ability to serve as cognitively plausible models of human vision. Implications for machine learning, human perception, and embodied cognition are discussed.
Signal in Noise: Exploring Meaning Encoded in Random Character Sequences with Character-Aware Language Models
Mar 15, 2022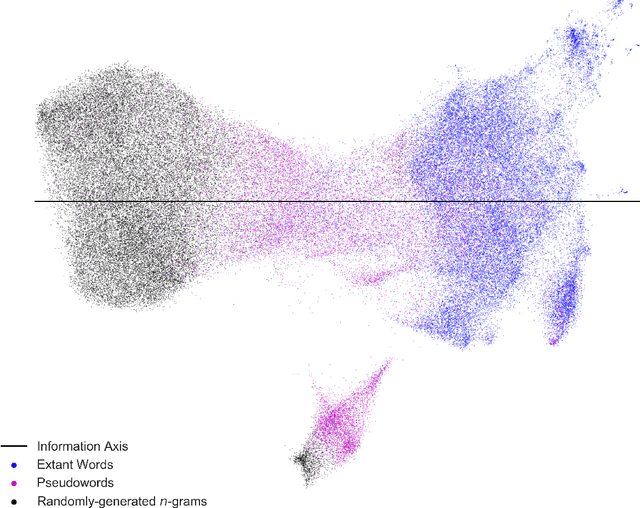

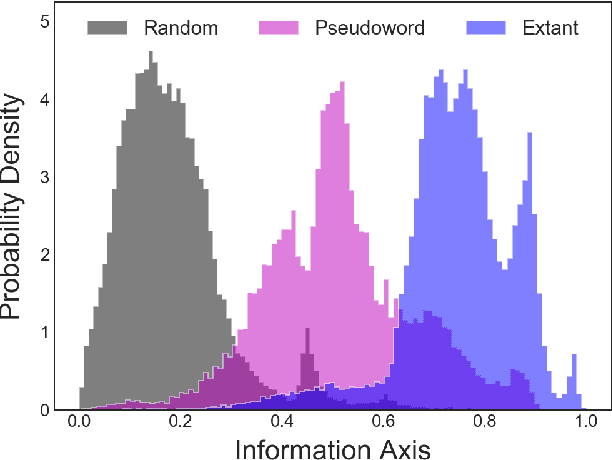
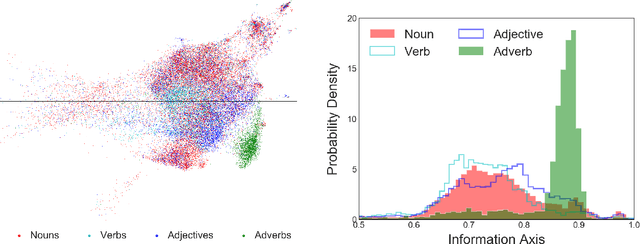
Natural language processing models learn word representations based on the distributional hypothesis, which asserts that word context (e.g., co-occurrence) correlates with meaning. We propose that $n$-grams composed of random character sequences, or $garble$, provide a novel context for studying word meaning both within and beyond extant language. In particular, randomly generated character $n$-grams lack meaning but contain primitive information based on the distribution of characters they contain. By studying the embeddings of a large corpus of garble, extant language, and pseudowords using CharacterBERT, we identify an axis in the model's high-dimensional embedding space that separates these classes of $n$-grams. Furthermore, we show that this axis relates to structure within extant language, including word part-of-speech, morphology, and concept concreteness. Thus, in contrast to studies that are mainly limited to extant language, our work reveals that meaning and primitive information are intrinsically linked.
comp-syn: Perceptually Grounded Word Embeddings with Color
Oct 19, 2020
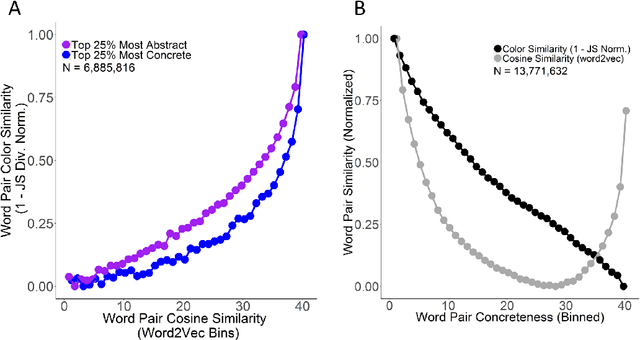
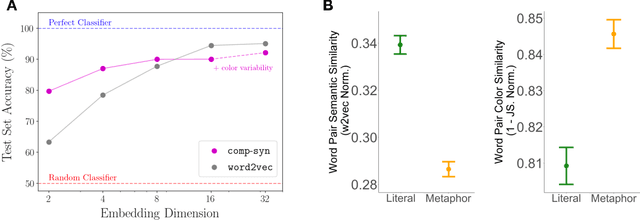

Popular approaches to natural language processing create word embeddings based on textual co-occurrence patterns, but often ignore embodied, sensory aspects of language. Here, we introduce the Python package comp-syn, which provides grounded word embeddings based on the perceptually uniform color distributions of Google Image search results. We demonstrate that comp-syn significantly enriches models of distributional semantics. In particular, we show that (1) comp-syn predicts human judgments of word concreteness with greater accuracy and in a more interpretable fashion than word2vec using low-dimensional word-color embeddings, and (2) comp-syn performs comparably to word2vec on a metaphorical vs. literal word-pair classification task. comp-syn is open-source on PyPi and is compatible with mainstream machine-learning Python packages. Our package release includes word-color embeddings for over 40,000 English words, each associated with crowd-sourced word concreteness judgments.
Kernel-Based Ensemble Learning in Python
Dec 17, 2019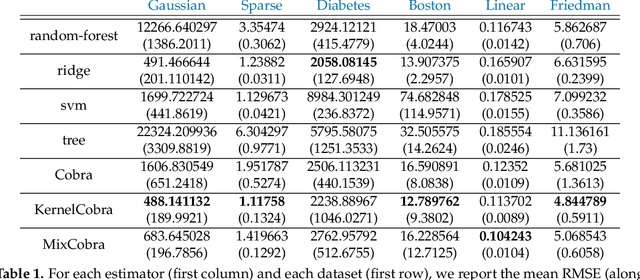
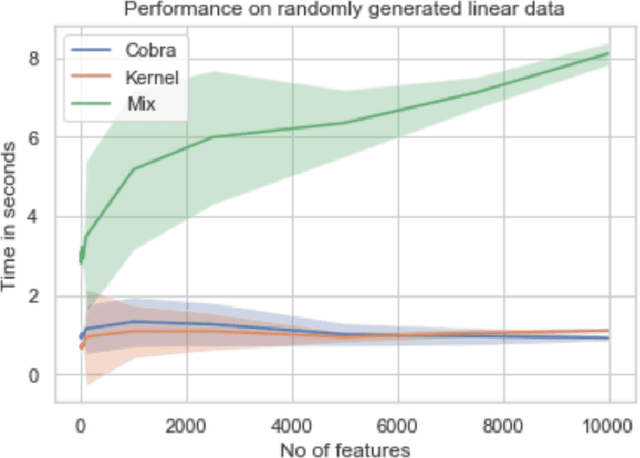
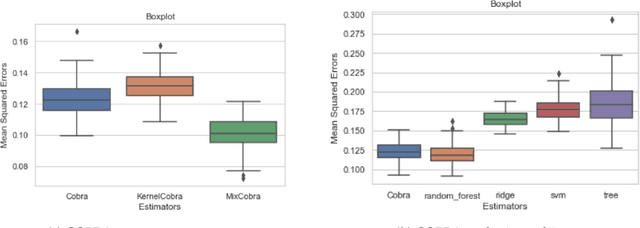
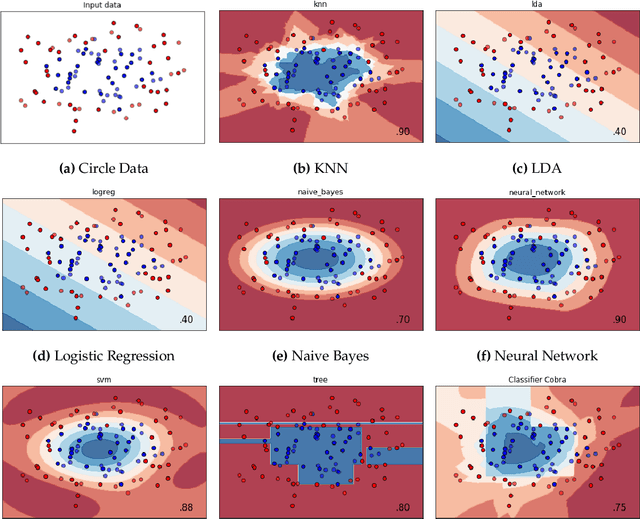
We propose a new supervised learning algorithm, for classification and regression problems where two or more preliminary predictors are available. We introduce \texttt{KernelCobra}, a non-linear learning strategy for combining an arbitrary number of initial predictors. \texttt{KernelCobra} builds on the COBRA algorithm introduced by \citet{biau2016cobra}, which combined estimators based on a notion of proximity of predictions on the training data. While the COBRA algorithm used a binary threshold to declare which training data were close and to be used, we generalize this idea by using a kernel to better encapsulate the proximity information. Such a smoothing kernel provides more representative weights to each of the training points which are used to build the aggregate and final predictor, and \texttt{KernelCobra} systematically outperforms the COBRA algorithm. While COBRA is intended for regression, \texttt{KernelCobra} deals with classification and regression. \texttt{KernelCobra} is included as part of the open source Python package \texttt{Pycobra} (0.2.4 and onward), introduced by \citet{guedj2018pycobra}. Numerical experiments assess the performance (in terms of pure prediction and computational complexity) of \texttt{KernelCobra} on real-life and synthetic datasets.
Pycobra: A Python Toolbox for Ensemble Learning and Visualisation
Jul 27, 2017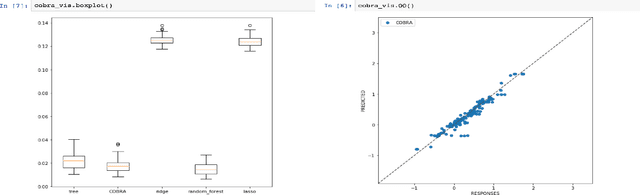
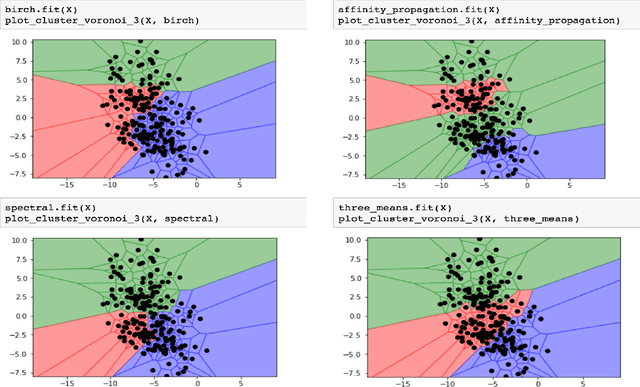
We introduce \texttt{pycobra}, a Python library devoted to ensemble learning (regression and classification) and visualisation. Its main assets are the implementation of several ensemble learning algorithms, a flexible and generic interface to compare and blend any existing machine learning algorithm available in Python libraries (as long as a \texttt{predict} method is given), and visualisation tools such as Voronoi tessellations. \texttt{pycobra} is fully \texttt{scikit-learn} compatible and is released under the MIT open-source license. \texttt{pycobra} can be downloaded from the Python Package Index (PyPi) and Machine Learning Open Source Software (MLOSS). The current version (along with Jupyter notebooks, extensive documentation, and continuous integration tests) is available at \href{https://github.com/bhargavvader/pycobra}{https://github.com/bhargavvader/pycobra}.