 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel-Based Ensemble Learning in Python
Paper and Code
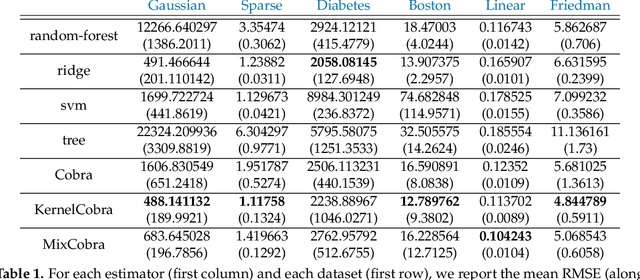
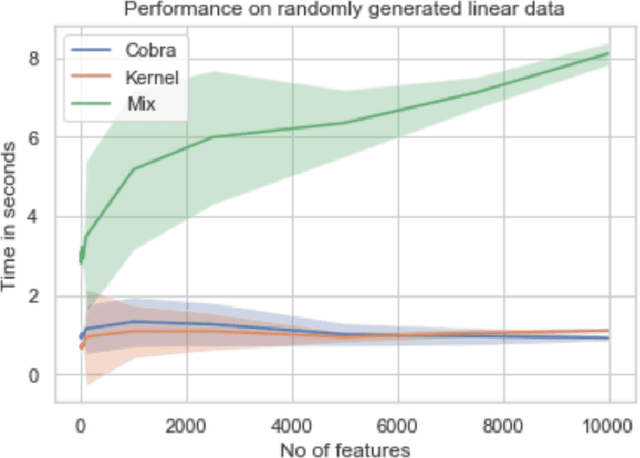
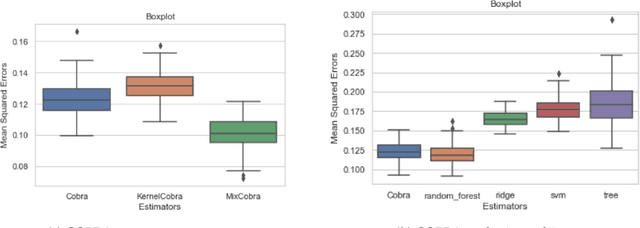
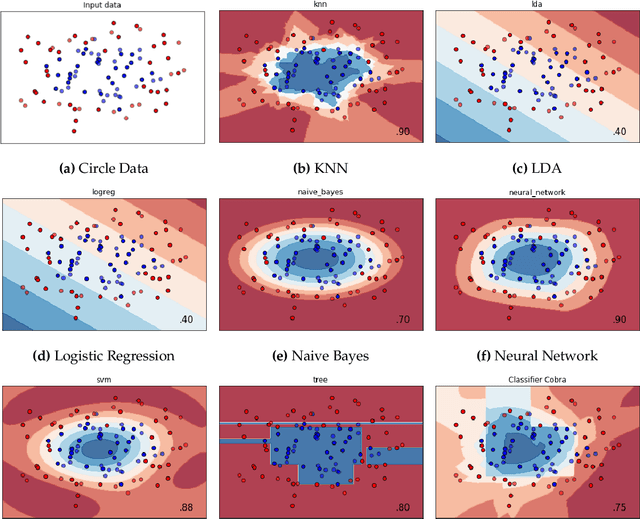
We propose a new supervised learning algorithm, for classification and regression problems where two or more preliminary predictors are available. We introduce \texttt{KernelCobra}, a non-linear learning strategy for combining an arbitrary number of initial predictors. \texttt{KernelCobra} builds on the COBRA algorithm introduced by \citet{biau2016cobra}, which combined estimators based on a notion of proximity of predictions on the training data. While the COBRA algorithm used a binary threshold to declare which training data were close and to be used, we generalize this idea by using a kernel to better encapsulate the proximity information. Such a smoothing kernel provides more representative weights to each of the training points which are used to build the aggregate and final predictor, and \texttt{KernelCobra} systematically outperforms the COBRA algorithm. While COBRA is intended for regression, \texttt{KernelCobra} deals with classification and regression. \texttt{KernelCobra} is included as part of the open source Python package \texttt{Pycobra} (0.2.4 and onward), introduced by \citet{guedj2018pycobra}. Numerical experiments assess the performance (in terms of pure prediction and computational complexity) of \texttt{KernelCobra} on real-life and synthetic datasets.