 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivergences in Color Perception between Deep Neural Networks and Humans
Sep 11, 2023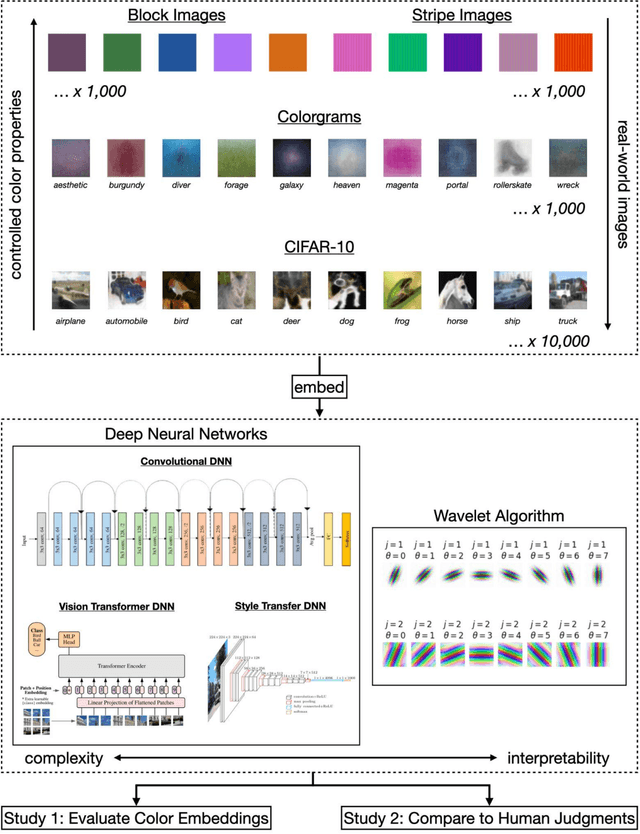

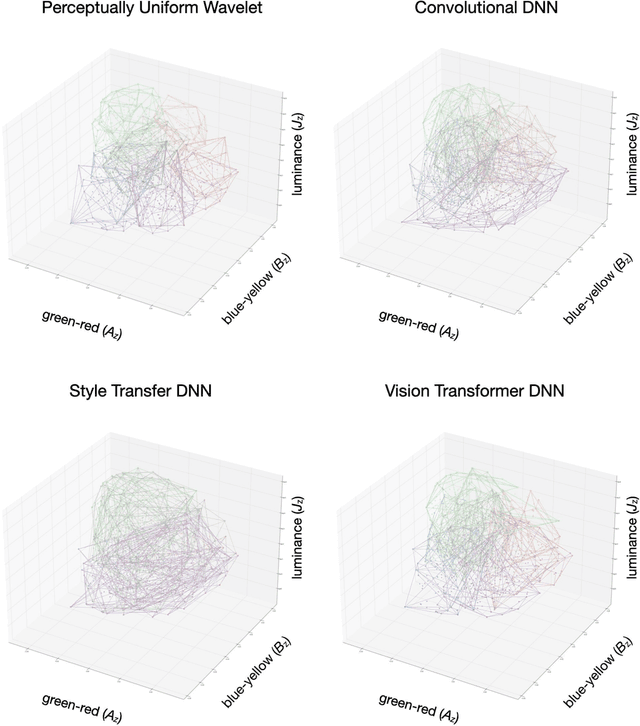
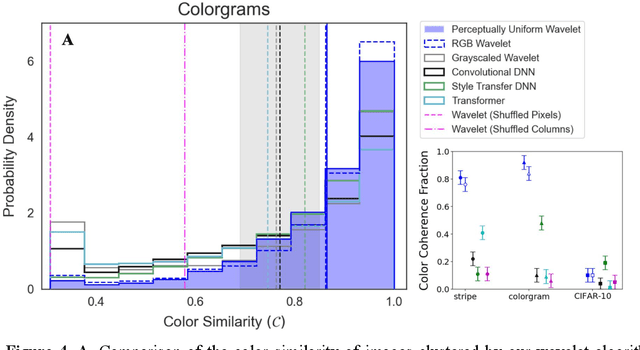
Deep neural networks (DNNs) are increasingly proposed as models of human vision, bolstered by their impressive performance on image classification and object recognition tasks. Yet, the extent to which DNNs capture fundamental aspects of human vision such as color perception remains unclear. Here, we develop novel experiments for evaluating the perceptual coherence of color embeddings in DNNs, and we assess how well these algorithms predict human color similarity judgments collected via an online survey. We find that state-of-the-art DNN architectures $-$ including convolutional neural networks and vision transformers $-$ provide color similarity judgments that strikingly diverge from human color judgments of (i) images with controlled color properties, (ii) images generated from online searches, and (iii) real-world images from the canonical CIFAR-10 dataset. We compare DNN performance against an interpretable and cognitively plausible model of color perception based on wavelet decomposition, inspired by foundational theories in computational neuroscience. While one deep learning model $-$ a convolutional DNN trained on a style transfer task $-$ captures some aspects of human color perception, our wavelet algorithm provides more coherent color embeddings that better predict human color judgments compared to all DNNs we examine. These results hold when altering the high-level visual task used to train similar DNN architectures (e.g., image classification versus image segmentation), as well as when examining the color embeddings of different layers in a given DNN architecture. These findings break new ground in the effort to analyze the perceptual representations of machine learning algorithms and to improve their ability to serve as cognitively plausible models of human vision. Implications for machine learning, human perception, and embodied cognition are discussed.
Signal in Noise: Exploring Meaning Encoded in Random Character Sequences with Character-Aware Language Models
Mar 15, 2022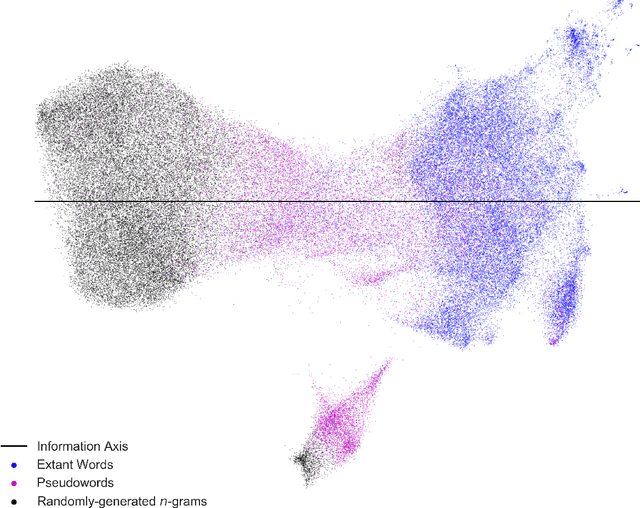

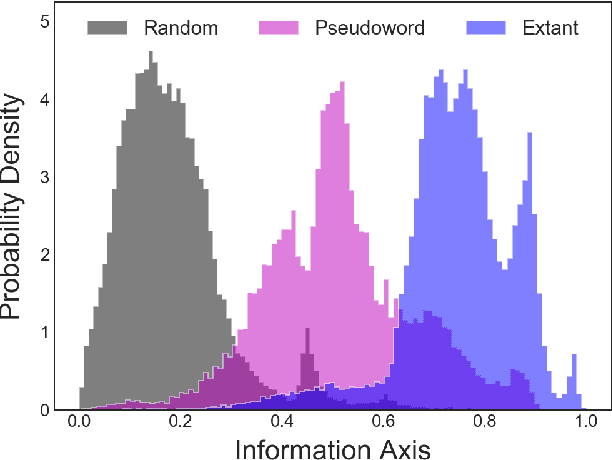
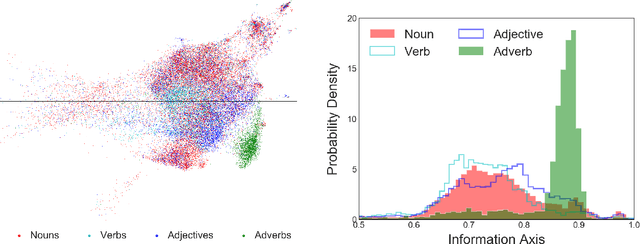
Natural language processing models learn word representations based on the distributional hypothesis, which asserts that word context (e.g., co-occurrence) correlates with meaning. We propose that $n$-grams composed of random character sequences, or $garble$, provide a novel context for studying word meaning both within and beyond extant language. In particular, randomly generated character $n$-grams lack meaning but contain primitive information based on the distribution of characters they contain. By studying the embeddings of a large corpus of garble, extant language, and pseudowords using CharacterBERT, we identify an axis in the model's high-dimensional embedding space that separates these classes of $n$-grams. Furthermore, we show that this axis relates to structure within extant language, including word part-of-speech, morphology, and concept concreteness. Thus, in contrast to studies that are mainly limited to extant language, our work reveals that meaning and primitive information are intrinsically linked.