 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal in Noise: Exploring Meaning Encoded in Random Character Sequences with Character-Aware Language Models
Mar 15, 2022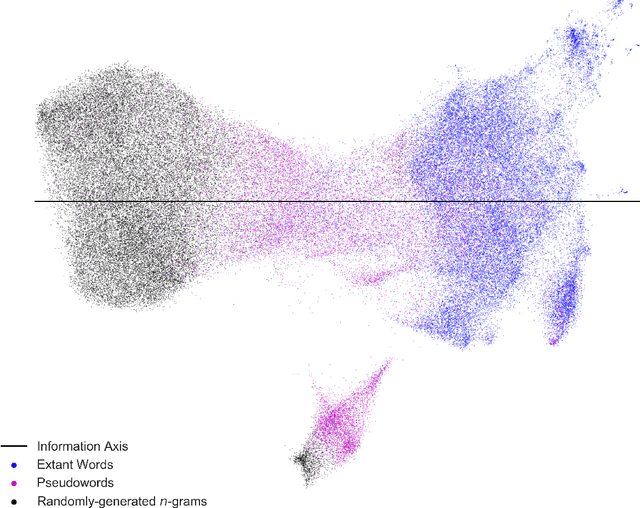

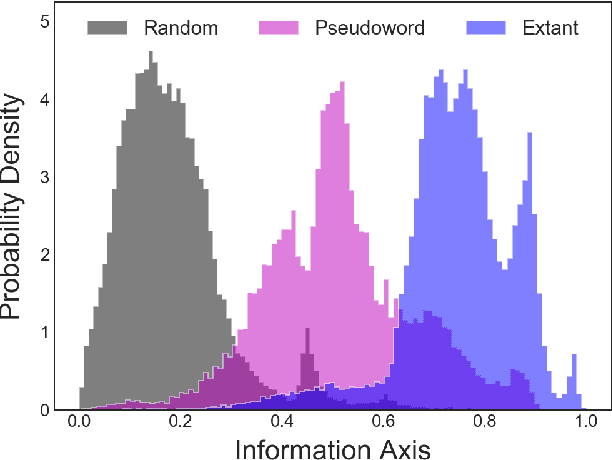
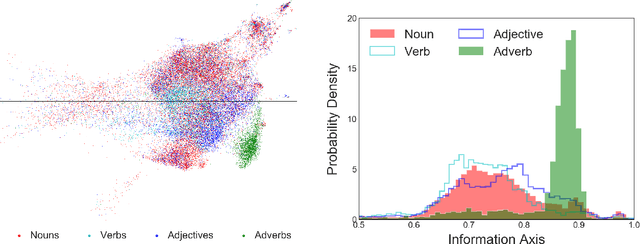
Natural language processing models learn word representations based on the distributional hypothesis, which asserts that word context (e.g., co-occurrence) correlates with meaning. We propose that $n$-grams composed of random character sequences, or $garble$, provide a novel context for studying word meaning both within and beyond extant language. In particular, randomly generated character $n$-grams lack meaning but contain primitive information based on the distribution of characters they contain. By studying the embeddings of a large corpus of garble, extant language, and pseudowords using CharacterBERT, we identify an axis in the model's high-dimensional embedding space that separates these classes of $n$-grams. Furthermore, we show that this axis relates to structure within extant language, including word part-of-speech, morphology, and concept concreteness. Thus, in contrast to studies that are mainly limited to extant language, our work reveals that meaning and primitive information are intrinsically linked.