 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Discriminative Representation with Meta-learning for Colonoscopic Polyp Re-Identification
Aug 02, 2023

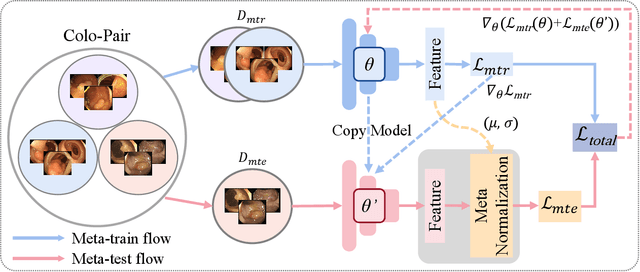

Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras and plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, traditional methods for object ReID directly adopting CNN models trained on the ImageNet dataset usually produce unsatisfactory retrieval performance on colonoscopic datasets due to the large domain gap. Additionally, these methods neglect to explore the potential of self-discrepancy among intra-class relations in the colonoscopic polyp dataset, which remains an open research problem in the medical community. To solve this dilemma, we propose a simple but effective training method named Colo-ReID, which can help our model to learn more general and discriminative knowledge based on the meta-learning strategy in scenarios with fewer samples. Based on this, a dynamic Meta-Learning Regulation mechanism called MLR is introduced to further boost the performance of polyp re-identification. To the best of our knowledge, this is the first attempt to leverage the meta-learning paradigm instead of traditional machine learning to effectively train deep models in the task of colonoscopic polyp re-identification. Empirical results show that our method significantly outperforms current state-of-the-art methods by a clear margin.
Learning Discriminative Visual-Text Representation for Polyp Re-Identification
Jul 20, 2023Colonoscopic Polyp Re-Identification aims to match a specific polyp in a large gallery with different cameras and views, which plays a key role for the prevention and treatment of colorectal cancer in the computer-aided diagnosis. However, traditional methods mainly focus on the visual representation learning, while neglect to explore the potential of semantic features during training, which may easily leads to poor generalization capability when adapted the pretrained model into the new scenarios. To relieve this dilemma, we propose a simple but effective training method named VT-ReID, which can remarkably enrich the representation of polyp videos with the interchange of high-level semantic information. Moreover, we elaborately design a novel clustering mechanism to introduce prior knowledge from textual data, which leverages contrastive learning to promote better separation from abundant unlabeled text data. To the best of our knowledge, this is the first attempt to employ the visual-text feature with clustering mechanism for the colonoscopic polyp re-identification. Empirical results show that our method significantly outperforms current state-of-the art methods with a clear margin.
Trusting the Explainers: Teacher Validation of Explainable Artificial Intelligence for Course Design
Dec 26, 2022Deep learning models for learning analytics have become increasingly popular over the last few years; however, these approaches are still not widely adopted in real-world settings, likely due to a lack of trust and transparency. In this paper, we tackle this issue by implementing explainable AI methods for black-box neural networks. This work focuses on the context of online and blended learning and the use case of student success prediction models. We use a pairwise study design, enabling us to investigate controlled differences between pairs of courses. Our analyses cover five course pairs that differ in one educationally relevant aspect and two popular instance-based explainable AI methods (LIME and SHAP). We quantitatively compare the distances between the explanations across courses and methods. We then validate the explanations of LIME and SHAP with 26 semi-structured interviews of university-level educators regarding which features they believe contribute most to student success, which explanations they trust most, and how they could transform these insights into actionable course design decisions. Our results show that quantitatively, explainers significantly disagree with each other about what is important, and qualitatively, experts themselves do not agree on which explanations are most trustworthy. All code, extended results, and the interview protocol are provided at https://github.com/epfl-ml4ed/trusting-explainers.
Deep Multimodal Fusion for Generalizable Person Re-identification
Nov 02, 2022Person re-identification plays a significant role in realistic scenarios due to its various applications in public security and video surveillance. Recently, leveraging the supervised or semi-unsupervised learning paradigms, which benefits from the large-scale datasets and strong computing performance, has achieved a competitive performance on a specific target domain. However, when Re-ID models are directly deployed in a new domain without target samples, they always suffer from considerable performance degradation and poor domain generalization. To address this challenge, in this paper, we propose DMF, a Deep Multimodal Fusion network for the general scenarios on person re-identification task, where rich semantic knowledge is introduced to assist in feature representation learning during the pre-training stage. On top of it, a multimodal fusion strategy is introduced to translate the data of different modalities into the same feature space, which can significantly boost generalization capability of Re-ID model. In the fine-tuning stage, a realistic dataset is adopted to fine-tine the pre-trained model for distribution alignment with real-world. Comprehensive experiments on benchmarks demonstrate that our proposed method can significantly outperform previous domain generalization or meta-learning methods. Our source code will also be publicly available at https://github.com/JeremyXSC/DMF.