 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredIN: Towards Open-Set Gesture Recognition via Prediction Inconsistency
Jul 29, 2024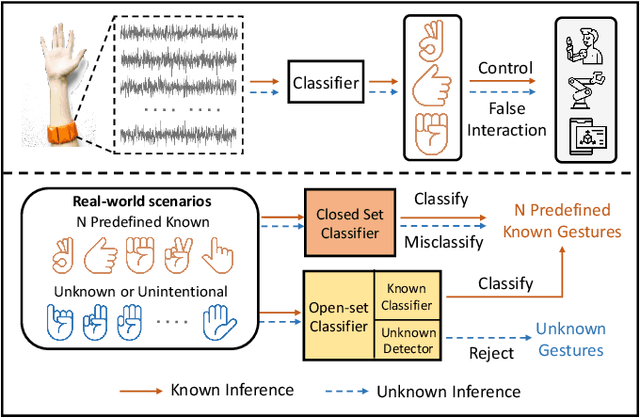
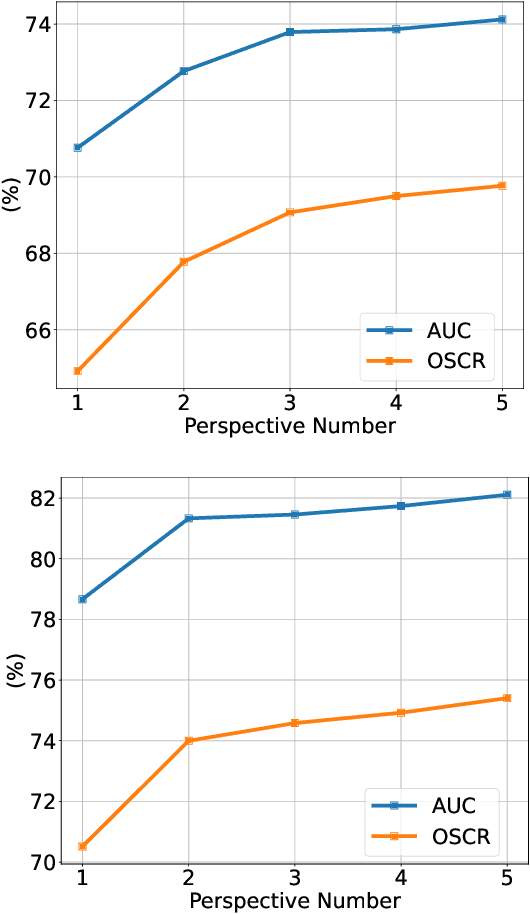
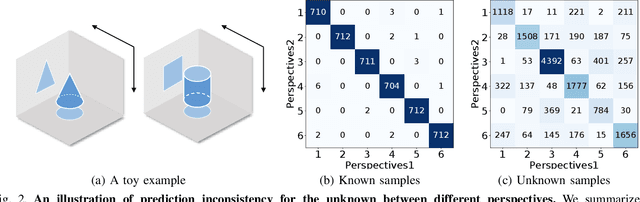
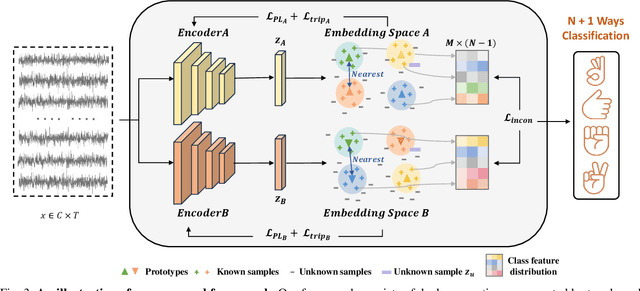
Gesture recognition based on surface electromyography (sEMG) has achieved significant progress in human-machine interaction (HMI). However, accurately recognizing predefined gestures within a closed set is still inadequate in practice; a robust open-set system needs to effectively reject unknown gestures while correctly classifying known ones. To handle this challenge, we first report prediction inconsistency discovered for unknown classes due to ensemble diversity, which can significantly facilitate the detection of unknown classes. Based on this insight, we propose an ensemble learning approach, PredIN, to explicitly magnify the prediction inconsistency by enhancing ensemble diversity. Specifically, PredIN maximizes the class feature distribution inconsistency among ensemble members to enhance diversity. Meanwhile, it optimizes inter-class separability within an individual ensemble member to maintain individual performance. Comprehensive experiments on various benchmark datasets demonstrate that the PredIN outperforms state-of-the-art methods by a clear margin.Our proposed method simultaneously achieves accurate closed-set classification for predefined gestures and effective rejection for unknown gestures, exhibiting its efficacy and superiority in open-set gesture recognition based on sEMG.
EDPNet: An Efficient Dual Prototype Network for Motor Imagery EEG Decoding
Jul 03, 2024Motor imagery electroencephalograph (MI-EEG) decoding plays a crucial role in developing motor imagery brain-computer interfaces (MI-BCIs). However, decoding intentions from MI remains challenging due to the inherent complexity of EEG signals relative to the small-sample size. In this paper, we propose an Efficient Dual Prototype Network (EDPNet) to enable accurate and fast MI decoding. EDPNet employs a lightweight adaptive spatial-spectral fusion module, which promotes more efficient information fusion between multiple EEG electrodes. Subsequently, a parameter-free multi-scale variance pooling module extracts more comprehensive temporal features. Furthermore, we introduce dual prototypical learning to optimize the feature space distribution and training process, thereby improving the model's generalization ability on small-sample MI datasets. Our experimental results show that the EDPNet outperforms state-of-the-art models with superior classification accuracy and kappa values (84.11% and 0.7881 for dataset BCI competition IV 2a, 86.65% and 0.7330 for dataset BCI competition IV 2b). Additionally, we use the BCI competition III IVa dataset with fewer training data to further validate the generalization ability of the proposed EDPNet. We also achieve superior performance with 82.03% classification accuracy. Benefiting from the lightweight parameters and superior decoding accuracy, our EDPNet shows great potential for MI-BCI applications. The code is publicly available at https://github.com/hancan16/EDPNet.
Towards Open-set Gesture Recognition via Feature Activation Enhancement and Orthogonal Prototype Learning
Dec 05, 2023Gesture recognition is a foundational task in human-machine interaction (HMI). While there has been significant progress in gesture recognition based on surface electromyography (sEMG), accurate recognition of predefined gestures only within a closed set is still inadequate in practice. It is essential to effectively discern and reject unknown gestures of disinterest in a robust system. Numerous methods based on prototype learning (PL) have been proposed to tackle this open set recognition (OSR) problem. However, they do not fully explore the inherent distinctions between known and unknown classes. In this paper, we propose a more effective PL method leveraging two novel and inherent distinctions, feature activation level and projection inconsistency. Specifically, the Feature Activation Enhancement Mechanism (FAEM) widens the gap in feature activation values between known and unknown classes. Furthermore, we introduce Orthogonal Prototype Learning (OPL) to construct multiple perspectives. OPL acts to project a sample from orthogonal directions to maximize the distinction between its two projections, where unknown samples will be projected near the clusters of different known classes while known samples still maintain intra-class similarity. Our proposed method simultaneously achieves accurate closed-set classification for predefined gestures and effective rejection for unknown gestures. Extensive experiments demonstrate its efficacy and superiority in open-set gesture recognition based on sEMG.
Towards Discriminative Representation with Meta-learning for Colonoscopic Polyp Re-Identification
Aug 02, 2023

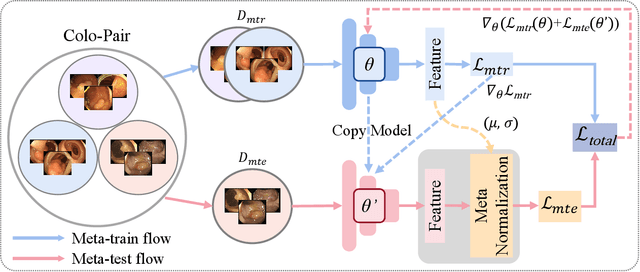

Colonoscopic Polyp Re-Identification aims to match the same polyp from a large gallery with images from different views taken using different cameras and plays an important role in the prevention and treatment of colorectal cancer in computer-aided diagnosis. However, traditional methods for object ReID directly adopting CNN models trained on the ImageNet dataset usually produce unsatisfactory retrieval performance on colonoscopic datasets due to the large domain gap. Additionally, these methods neglect to explore the potential of self-discrepancy among intra-class relations in the colonoscopic polyp dataset, which remains an open research problem in the medical community. To solve this dilemma, we propose a simple but effective training method named Colo-ReID, which can help our model to learn more general and discriminative knowledge based on the meta-learning strategy in scenarios with fewer samples. Based on this, a dynamic Meta-Learning Regulation mechanism called MLR is introduced to further boost the performance of polyp re-identification. To the best of our knowledge, this is the first attempt to leverage the meta-learning paradigm instead of traditional machine learning to effectively train deep models in the task of colonoscopic polyp re-identification. Empirical results show that our method significantly outperforms current state-of-the-art methods by a clear margin.
Colo-SCRL: Self-Supervised Contrastive Representation Learning for Colonoscopic Video Retrieval
Mar 28, 2023



Colonoscopic video retrieval, which is a critical part of polyp treatment, has great clinical significance for the prevention and treatment of colorectal cancer. However, retrieval models trained on action recognition datasets usually produce unsatisfactory retrieval results on colonoscopic datasets due to the large domain gap between them. To seek a solution to this problem, we construct a large-scale colonoscopic dataset named Colo-Pair for medical practice. Based on this dataset, a simple yet effective training method called Colo-SCRL is proposed for more robust representation learning. It aims to refine general knowledge from colonoscopies through masked autoencoder-based reconstruction and momentum contrast to improve retrieval performance. To the best of our knowledge, this is the first attempt to employ the contrastive learning paradigm for medical video retrieval. Empirical results show that our method significantly outperforms current state-of-the-art methods in the colonoscopic video retrieval task.