 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnraveling Downstream Gender Bias from Large Language Models: A Study on AI Educational Writing Assistance
Nov 06, 2023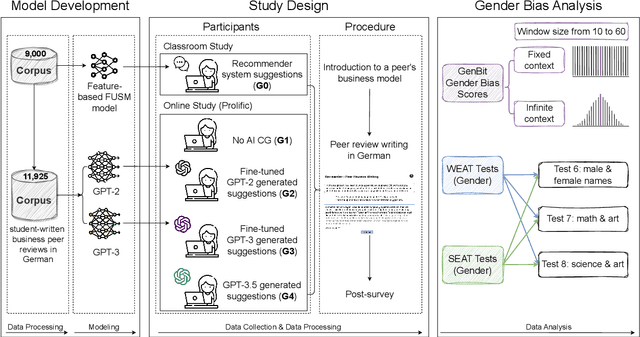
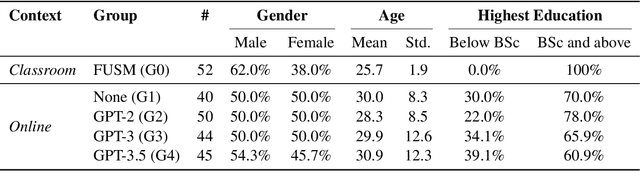
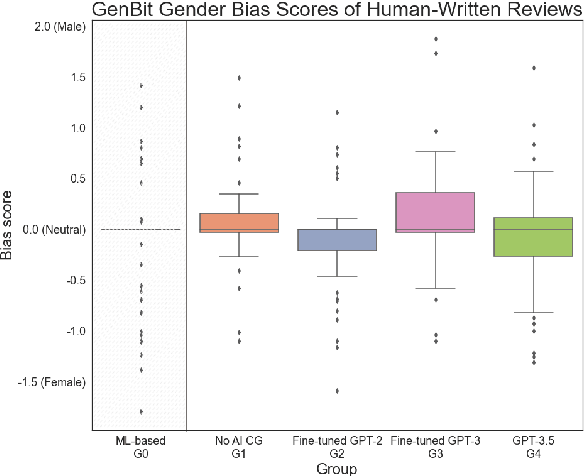
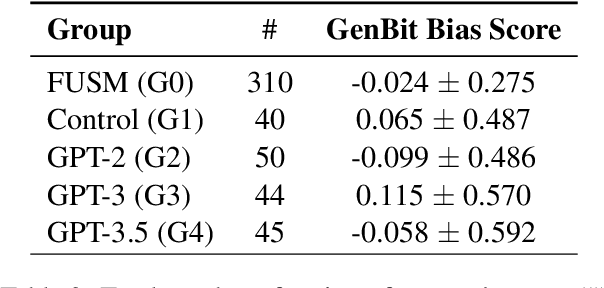
Large Language Models (LLMs) are increasingly utilized in educational tasks such as providing writing suggestions to students. Despite their potential, LLMs are known to harbor inherent biases which may negatively impact learners. Previous studies have investigated bias in models and data representations separately, neglecting the potential impact of LLM bias on human writing. In this paper, we investigate how bias transfers through an AI writing support pipeline. We conduct a large-scale user study with 231 students writing business case peer reviews in German. Students are divided into five groups with different levels of writing support: one classroom group with feature-based suggestions and four groups recruited from Prolific -- a control group with no assistance, two groups with suggestions from fine-tuned GPT-2 and GPT-3 models, and one group with suggestions from pre-trained GPT-3.5. Using GenBit gender bias analysis, Word Embedding Association Tests (WEAT), and Sentence Embedding Association Test (SEAT) we evaluate the gender bias at various stages of the pipeline: in model embeddings, in suggestions generated by the models, and in reviews written by students. Our results demonstrate that there is no significant difference in gender bias between the resulting peer reviews of groups with and without LLM suggestions. Our research is therefore optimistic about the use of AI writing support in the classroom, showcasing a context where bias in LLMs does not transfer to students' responses.
Insert-expansions for Tool-enabled Conversational Agents
Jul 04, 2023



This paper delves into an advanced implementation of Chain-of-Thought-Prompting in Large Language Models, focusing on the use of tools (or "plug-ins") within the explicit reasoning paths generated by this prompting method. We find that tool-enabled conversational agents often become sidetracked, as additional context from tools like search engines or calculators diverts from original user intents. To address this, we explore a concept wherein the user becomes the tool, providing necessary details and refining their requests. Through Conversation Analysis, we characterize this interaction as insert-expansion - an intermediary conversation designed to facilitate the preferred response. We explore possibilities arising from this 'user-as-a-tool' approach in two empirical studies using direct comparison, and find benefits in the recommendation domain.
Bias at a Second Glance: A Deep Dive into Bias for German Educational Peer-Review Data Modeling
Sep 22, 2022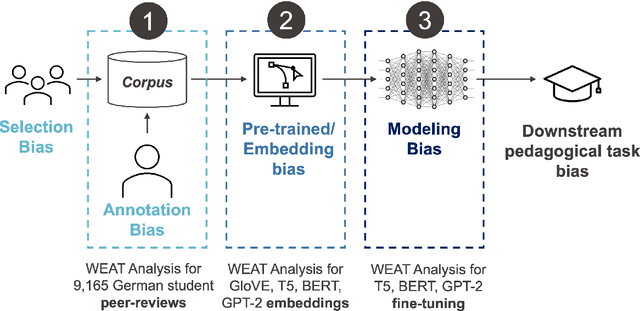
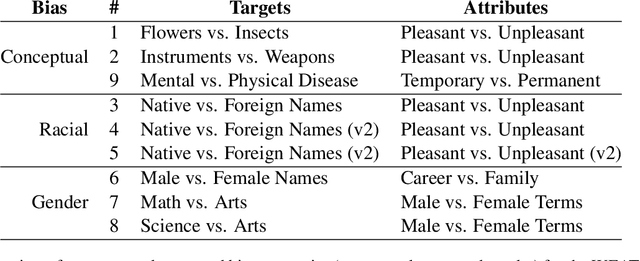

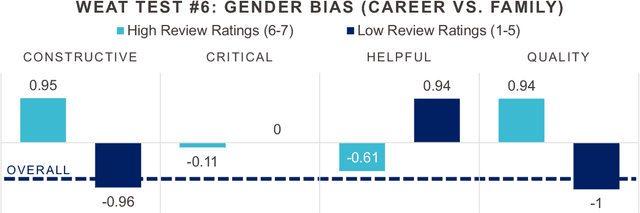
Natural Language Processing (NLP) has become increasingly utilized to provide adaptivity in educational applications. However, recent research has highlighted a variety of biases in pre-trained language models. While existing studies investigate bias in different domains, they are limited in addressing fine-grained analysis on educational and multilingual corpora. In this work, we analyze bias across text and through multiple architectures on a corpus of 9,165 German peer-reviews collected from university students over five years. Notably, our corpus includes labels such as helpfulness, quality, and critical aspect ratings from the peer-review recipient as well as demographic attributes. We conduct a Word Embedding Association Test (WEAT) analysis on (1) our collected corpus in connection with the clustered labels, (2) the most common pre-trained German language models (T5, BERT, and GPT-2) and GloVe embeddings, and (3) the language models after fine-tuning on our collected data-set. In contrast to our initial expectations, we found that our collected corpus does not reveal many biases in the co-occurrence analysis or in the GloVe embeddings. However, the pre-trained German language models find substantial conceptual, racial, and gender bias and have significant changes in bias across conceptual and racial axes during fine-tuning on the peer-review data. With our research, we aim to contribute to the fourth UN sustainability goal (quality education) with a novel dataset, an understanding of biases in natural language education data, and the potential harms of not counteracting biases in language models for educational tasks.